hudi clustering 数据聚集(二)
小文件合并解析
执行代码:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val t1 = "t1"
val basePath = "file:///tmp/hudi_data/"
val dataGen = new DataGenerator(Array("2020/03/11"))
// 生成随机数据100条
val updates = convertToStringList(dataGen.generateInserts(100))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 1));
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, t1).
// 每次写入的数据都生成一个新的文件
option("hoodie.parquet.small.file.limit", "0").
// 每次操作之后都会进行clustering操作
option("hoodie.clustering.inline", "true").
// 每4次提交就做一次clustering操作
option("hoodie.clustering.inline.max.commits", "4").
// 指定生成文件最大大小
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").
// 指定小文件大小限制,当文件小于该值时,可用于被 clustering 操作
option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").
mode(Append).
save(basePath+t1);
// 创建临时视图,查看当前表内数据总个数
spark.read.format("hudi").load(basePath+t1).createOrReplaceTempView("t1_table")
spark.sql("select count(*) from t1_table").show()
以上示例中,指定了进行 clustering 的触发频率:每4次提交就触发一次,并指定了文件相关大小:生成新文件的最大大小、小文件最小大小。
执行步骤:
1、生成数据,插入数据。
查看当前磁盘上的文件:

查看表内数据个数:
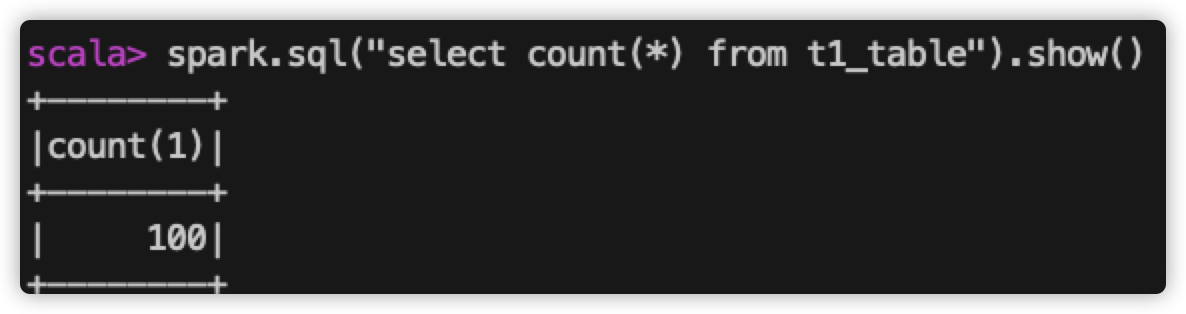
查看 spark-web 上 该 sql 执行读取的文件个数:

所以,当前表中共100条数据,磁盘上生成一个数据文件,在查询该表数据时,只读取了一个文件。
2、重复上面操作两次。
查看当前磁盘上的文件:

查看表内数据个数:
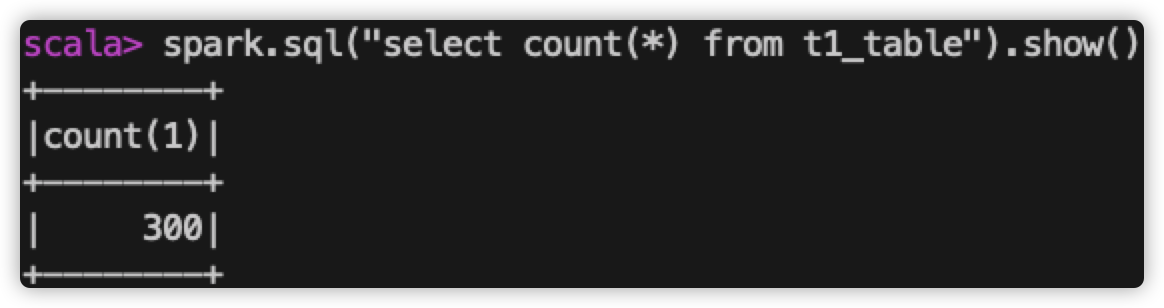
查看 spark-web 上 该 sql 执行读取的文件个数:

所以,目前为止,我们提交了3次写操作,每次生成1个数据文件,共生成了3个数据文件,当查询所有的数据时,需要从3个文件中读取数据。
3、再进行一次数据插入:
查看当前磁盘上的文件:

查看表内数据个数:

查看 spark-web 上 该 sql 执行读取的文件个数:

结论:
1、配置了hoodie.parquet.small.file.limit之后,每次提交新数据,都会生成一个数据文件。
2、在 clustering 之前,每次读取表所有数据的时候,都需要读取所有文件。
3、提交第4次数据之后,触发了 clustering ,生成了一个更大的文件,此时再读取所有数据的时候,就只需要读取合并后的大文件即可。在.hoodie文件夹下,也可以看到 replacecommit 的提交:

小文件合并+sort columns解析
执行代码:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val t1 = "t1"
val basePath = "file:///tmp/hudi_data/"
val dataGen = new DataGenerator(Array("2020/03/11"))
var a = 0;
for (a <- 1 to 8) {
val updates = convertToStringList(dataGen.generateInserts(10000))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 1));
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, t1).
// 每次写入的数据都生成一个新的文件
option("hoodie.parquet.small.file.limit", "0").
// 每次操作之后都会进行clustering操作
option("hoodie.clustering.inline", "true").
// 每4次提交就做一次clustering操作
option("hoodie.clustering.inline.max.commits", "8").
// 指定生成文件最大大小
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1400000").
// 指定小文件大小限制,当文件小于该值时,可用于被 clustering 操作
option("hoodie.clustering.plan.strategy.small.file.limit", "1400000").
// 指定排序的列
option("hoodie.clustering.plan.strategy.sort.columns", "fare").
mode(Append).
save(basePath+t1);
// 创建临时视图,查看当前表内数据总个数
spark.read.format("hudi").load(basePath+t1).createOrReplaceTempView("t1_table")
spark.sql("select count(*) from t1_table where fare > 50").show()
}
执行代码分析
该代码比之前代码修改了几个地方:
1、增加了for循环:
因为我们已经知道了在8次提交之后,小文件会合并大文件,所以一个for循环,做8次提交,我们直接看结果就行。
2、增加了 hoodie.clustering.plan.strategy.sort.columns 配置:
这是本次主要的测试点。该配置可以对指定的列进行排序。
即,当做 clustering 的时候,hudi 会重新读取所有文件,并根据指定的列做排序,这样可以把相关的数据聚集在一起,可以做更好的查询过滤(后面会演示说明),而我们要做的对比,就是以 fare 为条件查询数据,观察在 clustering 前后,hudi 会读取的文件个数。
我们想要的结果是,在 clustering 之前,由于没有根据 fare 对数据任何处理,符合过滤条件的数据会分布在各个文件,所以会读取的文件个数很多,过滤效果差。而在 clustering 之后,会根据 fare 列对数据做重新分布,符合过滤条件的数据较为集中,那么读取的数据就会比较少,过滤效果较好。
3、修改了 hoodie.clustering.plan.strategy.target.file.max.bytes 和 hoodie.clustering.plan.strategy.small.file.limit
我们想测的是,clustering 前后过滤的效果,所以文件个数不能够被改变(否则4个文件合并成1个文件后,读取数据时也只会读取1个文件,就看不出来sort是否有效果),所以这里把该值设置成两个较为近似的值,使其既能够触发 clustering,又能够在 clustering 前后文件个数相同。
执行结果:
查看当前磁盘文件:
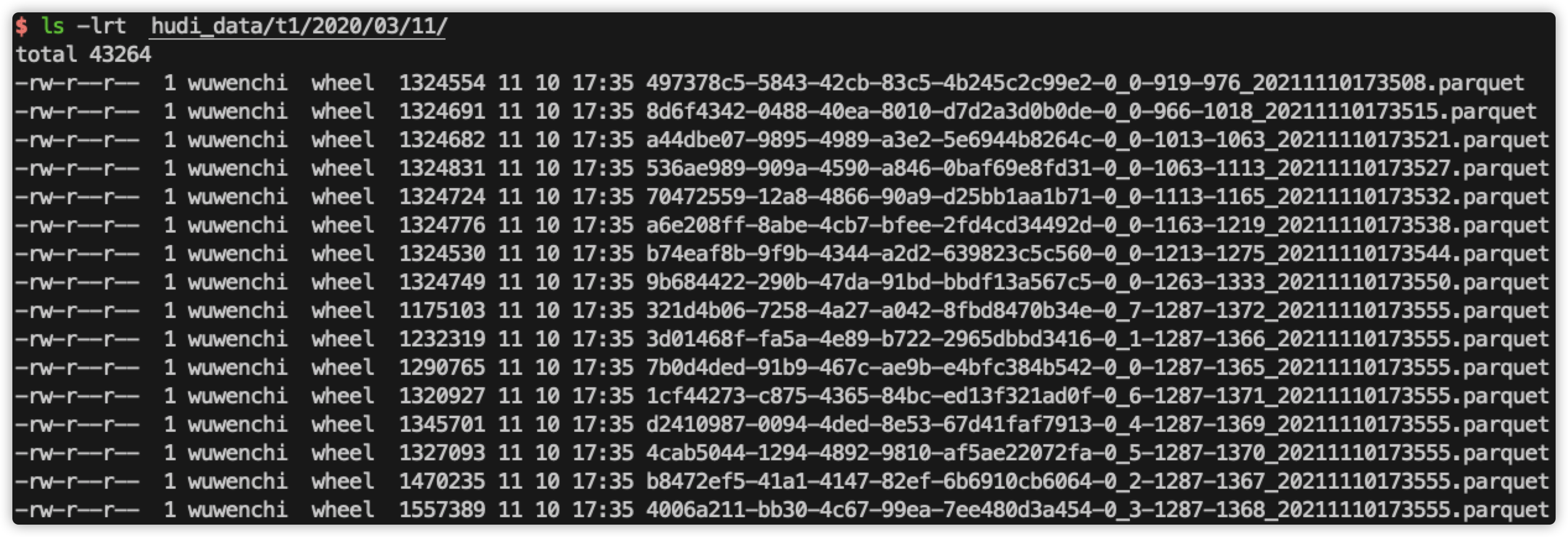
查看第5次的sql过滤结果:
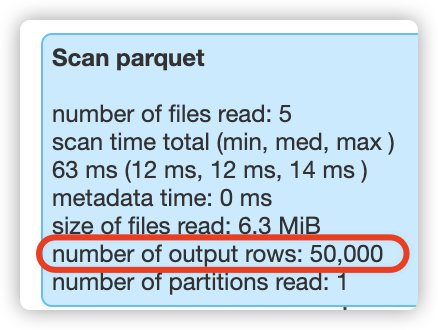
查看第6次的sql过滤结果:
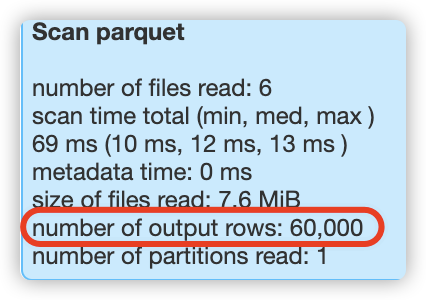
查看第7次的sql过滤结果:
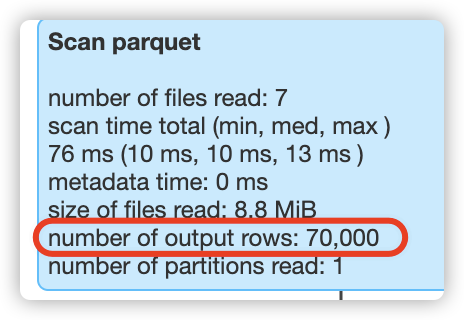
查看最后一次的sql过滤结果:
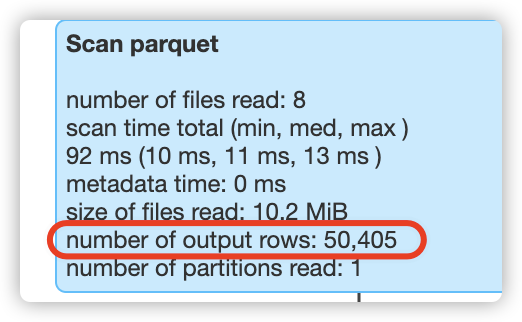
结论:
1、在 clustering 之前,过滤 fare 列时,会读取所有的数据。
比如,在执行第5次过滤时,此时表总共有50000行数据,hudi就会扫描50000行数据;在执行第6次过滤时,此时表总共有60000行数据,hudi就会扫描60000行数据;在执行第7次过滤时,此时表总共有70000行数据,hudi就会扫描70000行数据,
2、在 clustering 之后,数据文件个数不变的情况下(前后都是8个数据文件),在第8次过滤时,能够有效应用sort columns的重排列数据,将本应扫描80000行数据降低到只扫描了50405行数据,过滤效果明显提升很多!!
hudi clustering 数据聚集(二)的更多相关文章
- hudi clustering 数据聚集(一)
概要 数据湖的业务场景主要包括对数据库.日志.文件的分析,而管理数据湖有两点比较重要:写入的吞吐量和查询性能,这里主要说明以下问题: 1.为了获得更好的写入吞吐量,通常把数据直接写入文件中,这种情况下 ...
- hudi clustering 数据聚集(三 zorder使用)
目前最新的 hudi 版本为 0.9,暂时还不支持 zorder 功能,但 master 分支已经合入了(RFC-28),所以可以自己编译 master 分支,提前体验下 zorder 效果. 环境 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 从txt文件中读取数据放在二维数组中
1.我D盘中的test.txt文件内的内容是这样的,也是随机产生的二维数组 /test.txt/ 5.440000 3.4500006.610000 6.0400008.900000 3.030000 ...
- 决战大数据之二:CentOS 7 最新JDK 8安装
决战大数据之二:CentOS 7 最新JDK 8安装 [TOC] 修改hostname # hostnamectl set-hostname node1 --static # reboot now 重 ...
- [数据清洗]- Pandas 清洗“脏”数据(二)
概要 了解数据 分析数据问题 清洗数据 整合代码 了解数据 在处理任何数据之前,我们的第一任务是理解数据以及数据是干什么用的.我们尝试去理解数据的列/行.记录.数据格式.语义错误.缺失的条目以及错误的 ...
- 机器学习入门-数值特征-进行二值化变化 1.Binarizer(进行数据的二值化操作)
函数说明: 1. Binarizer(threshold=0.9) 将数据进行二值化,threshold表示大于0.9的数据为1,小于0.9的数据为0 对于一些数值型的特征:存在0还有其他的一些数 二 ...
- SQL 2005批量插入数据的二种方法
SQL 2005批量插入数据的二种方法 Posted on 2010-07-22 18:13 moss_tan_jun 阅读(2635) 评论(2) 编辑 收藏 在SQL Server 中插入一条数据 ...
- 吴裕雄 python 机器学习——数据预处理二元化OneHotEncoder模型
from sklearn.preprocessing import OneHotEncoder #数据预处理二元化OneHotEncoder模型 def test_OneHotEncoder(): X ...
随机推荐
- YbtOJ#573-后缀表达【二分图匹配】
正题 题目链接:https://www.ybtoj.com.cn/contest/115/problem/2 题目大意 给出一个包含字母变量和若干种同级操作符的后缀表达式.求一个等价的表达式满足该表达 ...
- P4345-[SHOI2015]超能粒子炮·改【Lucas定理,类欧】
正题 题目链接:https://www.luogu.com.cn/problem/P4345 题目大意 \(T\)组询问,给出\(n,k\)求 \[\sum_{i=0}^{k}\binom{n}{i} ...
- 三、mybatis多表关联查询和分布查询
前言 mybatis多表关联查询和懒查询,这篇文章通过一对一和一对多的实例来展示多表查询.不过需要掌握数据输出的这方面的知识.之前整理过了mybatis入门案例和mybatis数据输出,多表查询是在前 ...
- 【vue】两个页面间传参 - props
目录 Step1 设置可以 props 传递数据 Step2 跳转前页面中传递数据 Step3 跳转后的页面接收数据 从 A 页面跳转到 B 页面, 参数/数据通过 props 传递到 B 页面,这种 ...
- Go语言核心36讲(Go语言基础知识一)--学习笔记
01 | 工作区和GOPATH 从 Go 1.5 版本的自举(即用 Go 语言编写程序来实现 Go 语言自身),到 Go 1.7 版本的极速 GC(也称垃圾回收器),再到 2018 年 2 月发布的 ...
- 从单体迈向 Serverless 的避坑指南
作者 | 不瞋 导读:用户需求和云的发展两条线推动了云原生技术的兴起.发展和大规模应用.本文将主要讨论什么是云原生应用,构成云原生应用的要素是什么,什么是 Serverless 计算,以及 Serve ...
- Java中JDK、JRE和JVM三者之间有什么区别和联系?Java基础!
任何语言或软件都需要一个运行环境.正如人想生活在空气中,鱼想生活在水中一样,喜荫植物不能暴露在阳光下,任何物体个体的存在都离不开其所需的环境,编程语言也是一样的. 接下来就详细描述一下Java中JDK ...
- redis学习笔记-02 list列表类型命令
一.lpush key value1 value2 value3 value4(命令将一个或多个值插入到列表头部. 如果 key 不存在,一个空列表会被创建并执行 LPUSH 操作) lpush k1 ...
- 洛谷2387 NOI2014魔法森林(LCT维护最小生成树)
本题是运用LCT来维护一个最小生成树. 是一个经典的套路 题目中求的是一个\(max(a_i)+max(b_i)\)尽可能小的路径. 那么这种的一个套路就是,先按照一维来排序,然后用LCT维护另一维 ...
- 这么多TiDB负载均衡方案总有一款适合你
[是否原创]是 [首发渠道]TiDB 社区 前言 分布式关系型数据库TiDB是一种计算和存储分离的架构,每一层都可以独立地进行水平扩展,这样就可以做到有的放矢,对症下药. 从TiDB整体架构图可以看到 ...