缓存系统redis操作、mongdb、memeche
mongdb :默认数据持久化,存在内存的同时也向硬盘写数据。
redis:可配置数据持久化,默认数据在内存中
memeche:only support 内存模式
redis操作 https://www.cnblogs.com/javastack/p/9854489.html
缓存数据库介绍
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,泛指非关系型的数据库,随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
NoSQL数据库的四大分类
NoSQL数据库的四大分类表格分析
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value)[3] | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。[3] | Key 指向 Value 的键值对,通常用hash table来实现[3] | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据[3] |
| 列存储数据库[3] | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库[3] | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库[3] | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。[3] |
redis
介绍
redis是业界主流的key-value nosql 数据库之一。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis优点
异常快速 : Redis是非常快的,每秒可以执行大约110000设置操作,81000个/每秒的读取操作。
支持丰富的数据类型 : Redis支持最大多数开发人员已经知道如列表,集合,可排序集合,哈希等数据类型。
这使得在应用中很容易解决的各种问题,因为我们知道哪些问题处理使用哪种数据类型更好解决。操作都是原子的 : 所有 Redis 的操作都是原子,从而确保当两个客户同时访问 Redis 服务器得到的是更新后的值(最新值)。
- MultiUtility工具:Redis是一个多功能实用工具,可以在很多如:缓存,消息传递队列中使用(Redis原生支持发布/订阅),在应用程序中,如:Web应用程序会话,网站页面点击数等任何短暂的数据;
安装Redis环境
$sudo apt-get update
$sudo apt-get install redis-server
启动 Redis
$redis-server
查看 redis 是否还在运行
$redis-cli
redis 127.0.0.1:6379>
redis 127.0.0.1:6379> ping
PONG
#!/usr/bin/env python
# Author:Zhangmingda
import redis
r = redis.Redis(host='192.168.11.5',port=6379)
r.set('name','zhangmingda') print(r.get('name'))
redis-cli
#!/usr/bin/env python
# Author:Zhangmingda
import redis pool = redis.ConnectionPool(host='192.168.11.5',port=6379)
r = redis.Redis(connection_pool=pool)
r.set('age','22') print(r.get('age'))
连接池
Redis API使用
redis-py 的API的使用可以分类为:
- 连接方式
- 连接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
连接方式
1、操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
|
1
2
3
4
5
|
import redis r = redis.Redis(host='10.211.55.4', port=6379)r.set('foo', 'Bar')print r.get('foo') |
2、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
操作
1. String操作get
redis中的String在在内存中按照一个name对应一个value来存储。如图:

set(name, value, ex=None, px=None, nx=False, xx=False)
|
1
2
3
4
5
6
|
在Redis中设置值,默认,不存在则创建,存在则修改参数: ex,过期时间(秒) px,过期时间(毫秒) nx,如果设置为True,则只有name不存在时,当前set操作才执行 xx,如果设置为True,则只有name存在时,岗前set操作才执行 |
setnx(name, value)
|
1
|
设置值,只有name不存在时,执行设置操作(添加) |
setex(name, value, time)
|
1
2
3
|
# 设置值# 参数: # time,过期时间(数字秒 或 timedelta对象)
|
psetex(name, time_ms, value)
|
1
2
3
|
# 设置值# 参数: # time_ms,过期时间(数字毫秒 或 timedelta对象) |
mset(*args, **kwargs)
|
1
2
3
4
5
|
批量设置值如: mset(k1='v1', k2='v2') 或 mget({'k1': 'v1', 'k2': 'v2'}) |
get(name)
|
1
|
获取值 |
mget(keys, *args)
|
1
2
3
4
5
|
批量获取如: mget('ylr', 'wupeiqi') 或 r.mget(['ylr', 'wupeiqi']) |
getset(name, value)
|
1
|
设置新值并获取原来的值 |
getrange(key, start, end)
|
1
2
3
4
5
6
|
# 获取子序列(根据字节获取,非字符)# 参数: # name,Redis 的 name # start,起始位置(字节) # end,结束位置(字节)# 如: "武沛齐" ,0-3表示 "武" |
setrange(name, offset, value)
|
1
2
3
4
|
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)# 参数: # offset,字符串的索引,字节(一个汉字三个字节) # value,要设置的值 |
setbit(name, offset, value)将字符的二进制位进行更改,0/1
192.168.11.5:6379> set name 'alex'
OK
192.168.11.5:6379> get name
"alex"
192.168.11.5:6379> get name
"alex"
192.168.11.5:6379> setbit name 6 1 //将name字符的二进制的第六位
(integer) 0
192.168.11.5:6379> get name
"clex"
字符'a的第六位为0,改为一就是字符‘c’

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# 对name对应值的二进制表示的位进行操作# 参数: # name,redis的name # offset,位的索引(将值变换成二进制后再进行索引) # value,值只能是 1 或 0# 注:如果在Redis中有一个对应: n1 = "foo", 那么字符串foo的二进制表示为:01100110 01101111 01101111 所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1, 那么最终二进制则变成 01100111 01101111 01101111,即:"goo"# 扩展,转换二进制表示: # source = "武沛齐" source = "foo" for i in source: num = ord(i) print bin(num).replace('b','') 特别的,如果source是汉字 "武沛齐"怎么办? 答:对于utf-8,每一个汉字占 3 个字节,那么 "武沛齐" 则有 9个字节 对于汉字,for循环时候会按照 字节 迭代,那么在迭代时,将每一个字节转换 十进制数,然后再将十进制数转换成二进制 11100110 10101101 10100110 11100110 10110010 10011011 11101001 10111101 10010000 -------------------------- ----------------------------- ----------------------------- 武 沛 齐 |
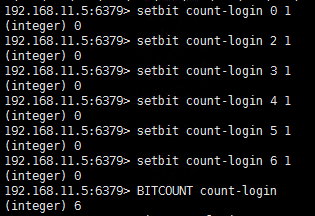
setbit用途举例,用最省空间的方式,存储在线用户数及分别是哪些用户在线
所有的用户登录的时候都对这个name的自己所在的位置进行一下签到(setbit 自己所在位置 设置为1),然后统计。
192.168.11.5:6379> setbit count-login 0 1
(integer) 0
192.168.11.5:6379> setbit count-login 2 1
(integer) 0
192.168.11.5:6379> setbit count-login 3 1
(integer) 0
192.168.11.5:6379> setbit count-login 4 1
(integer) 0
192.168.11.5:6379> setbit count-login 5 1
(integer) 0
192.168.11.5:6379> setbit count-login 6 1
(integer) 0
192.168.11.5:6379> BITCOUNT count-login
(integer) 6
测试redis setbit功能
getbit(name, offset)
|
1
|
# 获取name对应的值的二进制表示中的某位的值 (0或1) |
bitcount(key, start=None, end=None)
|
1
2
3
4
5
|
# 获取name对应的值的二进制表示中 1 的个数# 参数: # key,Redis的name # start,位起始位置 # end,位结束位置 |
strlen(name)
|
1
|
# 返回name对应值的字节长度(一个汉字3个字节) |
incr(self, name, amount=1)
|
1
2
3
4
5
6
7
|
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。# 参数: # name,Redis的name # amount,自增数(必须是整数)# 注:同incrby |
incrbyfloat(self, name, amount=1.0)
|
1
2
3
4
5
|
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。# 参数: # name,Redis的name # amount,自增数(浮点型) |
decr(self, name, amount=1)
|
1
2
3
4
5
|
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。# 参数: # name,Redis的name # amount,自减数(整数) |
append(key, value)
|
1
2
3
4
5
|
# 在redis name对应的值后面追加内容# 参数: key, redis的name value, 要追加的字符串 |
缓存系统redis操作、mongdb、memeche的更多相关文章
- 缓存系统——redis数据库
缓存系统有:mongodb.redis(速度更快).memcache 学习memcached 参考:http://www.cnblogs.com/wupeiqi/articles/5132791.ht ...
- 高性能缓存系统Redis安装与使用
在互联网后台架构中,需要应付高并发访问数据库,很多时候都会在数据库上层增加一个缓存服务器来保存经常读写的数据以减少数据库压力,可以使用LVS.Memcached或Redis,Memcached和Red ...
- Redis操作string
Redis简介: ''' redis: 缓存,例如两个个程序A,B之间要进行数据共享,A可以把数据存在redis(内存里),其他程序都可以访问redis里的数据, 这样通过中间商redis就实现了两个 ...
- python对缓存(memcached,redis)的操作
1.Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的 ...
- Memcache,Redis,MongoDB(数据缓存系统)方案对比与分析
mongodb和memcached不是一个范畴内的东西.mongodb是文档型的非关系型数据库,其优势在于查询功能比较强大,能存储海量数据.mongodb和memcached不存在谁替换谁的问题. 和 ...
- 02: Redis缓存系统
目录: 1.1 在centos6.5中安装Redis 1.2 Redis的简介及两种基本操作 1.3 Redis对string操作(第一类) 1.4 redis对Hash操作,字典格式(第二类) 1. ...
- Django缓存系统选择之Memcached与Redis的区别与性能对比
Django支持使用Memcached和Redis这两种流行的内存型数据库作为缓存系统.我们今天来看Memcached和Redis的区别和性能对比. redis和memcached的区别 1.Redi ...
- 缓存数据库-redis数据类型和操作(list)
转: 狼来的日子里! 奋发博取 缓存数据库-redis数据类型和操作(list) 一:Redis 列表(List) Redis列表是简单的字符串列表,按照插入顺序排序.你可以添加一个元素导列表的头部( ...
- 第三百节,python操作redis缓存-其他常用操作,用于操作redis里的数据name,不论什么数据类型
python操作redis缓存-其他常用操作,用于操作redis里的数据name,不论什么数据类型 delete(*names)根据删除redis中的任意数据类型 #!/usr/bin/env pyt ...
随机推荐
- SpringMVC学习笔记---依赖配置和简单案例实现
初识SpringMVC 实现步骤: 新建一个web项目 导入相关jar包 编写web.xml,注册DispatcherServlet 编写springmvc配置文件 接下来就是去创建对应的控制类 , ...
- [源码解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向传播
[源码解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向传播 目录 [源码解析] PyTorch 分布式(13) ----- Distribu ...
- 矩阵树定理&BEST定理学习笔记
终于学到这个了,本来准备省选前学来着的? 前置知识:矩阵行列式 矩阵树定理 矩阵树定理说的大概就是这样一件事:对于一张无向图 \(G\),我们记 \(D\) 为其度数矩阵,满足 \(D_{i,i}=\ ...
- Codeforces 1413F - Roads and Ramen(树的直径+找性质)
Codeforces 题目传送门 & 洛谷题目传送门 其实是一道还算一般的题罢--大概是最近刷长链剖分,被某道长链剖分与直径结合的题爆踩之后就点开了这题. 本题的难点就在于看出一个性质:最长路 ...
- Go知识点大纲
目录 1. 基本介绍 2. 安装及配置 3. 变量 4. 常量 5. 数据类型 5.1 numeric(数字) 5.2 string(字符串) 5.3 array(数组) 5.4 slice(切片) ...
- accomplish, accord
accomplish =achieve; accomplishment=achievement. accomplished: well educated/trained, skilled. skill ...
- 大数据学习day23-----spark06--------1. Spark执行流程(知识补充:RDD的依赖关系)2. Repartition和coalesce算子的区别 3.触发多次actions时,速度不一样 4. RDD的深入理解(错误例子,RDD数据是如何获取的)5 购物的相关计算
1. Spark执行流程 知识补充:RDD的依赖关系 RDD的依赖关系分为两类:窄依赖(Narrow Dependency)和宽依赖(Shuffle Dependency) (1)窄依赖 窄依赖指的是 ...
- 【XSS】再谈CSP内容安全策略
再谈CSP内容安全策略 之前每次都是想的很浅,或者只是个理论派,事实证明就是得动手实践 参考 CSP的用法 官方文档 通过设置属性来告诉浏览器允许加载的资源数据来源.可通过Response响应头来设置 ...
- 从源码看RequestMappingHandlerMapping的注册与发现
1.问题的产生 日常开发中,大多数的API层中@Controller注解和@RequestMapping注解都会被使用在其中,但是为什么标注了@Controller和@RequestMapping注解 ...
- 利用unordered_map维护关联数据
在leetcode上刷339题Evaluate Division(https://leetcode.com/problems/evaluate-division/#/description)时在脑中过 ...