02_利用numpy解决线性回归问题
02_利用numpy解决线性回归问题
一、引言
上一节我们说到了torch和tf的功能,以及两者的区别。但是为了更好地去让大家体会框架的强大,我们首先不使用框架实现一个小demo。由于只是引入,因此,我们在这里使用一个比较简单的线性回归算法来讲解。
穿插一个广告,如果你对统计机器学习不是特别熟悉的话,建议你也简单看看,不说学会那些数学公式的推导,但是得知道那些算法是干啥的,我这里也有全套的视频和资料,链接在此:https://www.cnblogs.com/nickchen121/p/11686958.html
你都来学习框架了,接下来的所有内容我都默认你有一定的Python基础、数学基础、统计机器学习基础、深度学习基础,如果你有哪些不太会,我的博客里都有,可以自己去补一补,如果不喜欢我的,可以去bilibili找几个视频看,你都不喜欢?那就自己造一个出来。
二、线性回归简单介绍
2.1 线性回归三要素
由于现在统计机器学习一般也称为机器学习,但是真正的机器学习是包括是深度学习的,所以,接下来讲的机器学习这四个字你别太追究它原有的意义,大概知道是啥就行。
在机器学习中,我们知道,每一个算法简单点讲其实无非就是三个要素:一个输入、一个模型、一个输出,而线性回归属于机器学习算法,也是如此。输入就是一大堆的数据,输出就是我们想要的结果,而模型就是通过输入数据得出一个输出结果。举个例子吧。
现在我们这里有两组数据:
3.043 = w*x_2+b
\]
这两组数据中,输入是\(x_1\)和\(x_2\),模型就是一个函数\(f=y=w*x_i+b\),输出就是\(1.567\)和\(3.043\)。知道这三个东西有什么用呢?有很大的用,我们可以看到我们这个函数有两个未知变量\(w\)和\(b\),如果我们把这个输入看作是房子的面积,输出看成房子的价格,如果我们通过某种方法求出了\(w\)和\(b\),我们就可以立即通过另外一个房子的面积\(x_3\)得知这个房子的价格。当然咯,实际情况不会这么简单,你别较真了。
那么问题来了,我们如何去求出\(w\)和\(b\)呢?有些耍些小聪明的同学马上会说到,这么简单地问题,我口算一下不就出来了嘛!\(w\approx{1.5}, b\approx{0.06}\),然而这其实离精确求解差远了,如果这不是求解房价,而是求解股价的问题,那可就差之毫厘谬以千里了。
在这里重点声明一遍,我们举这么简单的例子只是为了让你明白使用框架和不使用框架的好处,所以一些细节莫钻牛角尖,学东西要明白重点。
2.2 损失函数
上面说到了,我们给出了一个函数模型\(f_{(w,b)}\),其中\(w\)和\(b\)是函数\(f\)的位置变量,我们现在的目的就是通过已有的输入和输出求解出这两个变量。
为了得出这两个变量,我们这里引入一个专业术语损失(loss)函数,其实我很想写loss函数,因为有人也把它称作代价函数,但是相信有一定基础的人你一定明白,毕竟只是个名字而已,难道我叫吴彦祖我就是吴彦祖了?所以接下来所有的有多个名字的专业术语我都用我了解到的那个名字。
那么损失函数是什么意思呢?其实,顾名思义,就是一个损失,也就是一个差值,什么差值呢?就是我们假设未知变量\(w\)和\(b\)已知,简单点吧,我们假设\(w=b=0\),然后我们根据这个未知变量就可以精准化我们的模型\(f\),然后再通过这个模型以及输入和输出便可以得到一个预测值\(\hat{y}=w*x+b\),由于我们的\(w\)和\(b\)是假设的,因此预测值\(\hat{y}\)和真实值\(y\)之间有一定的差值,这个差值就是损失,而对\(N\)个数据而言,总损失就是
\]
而损失函数指的是对损失的一种扩展,比如线性回归中最常使用的损失函数就是均方误差函数,如下:
\]
2.3 梯度下降
上面我们得到了一个均方误差的损失函数,然而可想而知,这个误差应该是越小越好,因此我们的目标就是最小化这个误差。上述这个损失函数,其实是一种凸函数,在凸优化理论中,可以使用梯度下降的方法来最小化这个凸函数,而当这个凸函数处于最小值时,此时的\(w\)和\(b\)也就是最优值,也就让\(\hat{y}\)和\(y\)的值更接近。
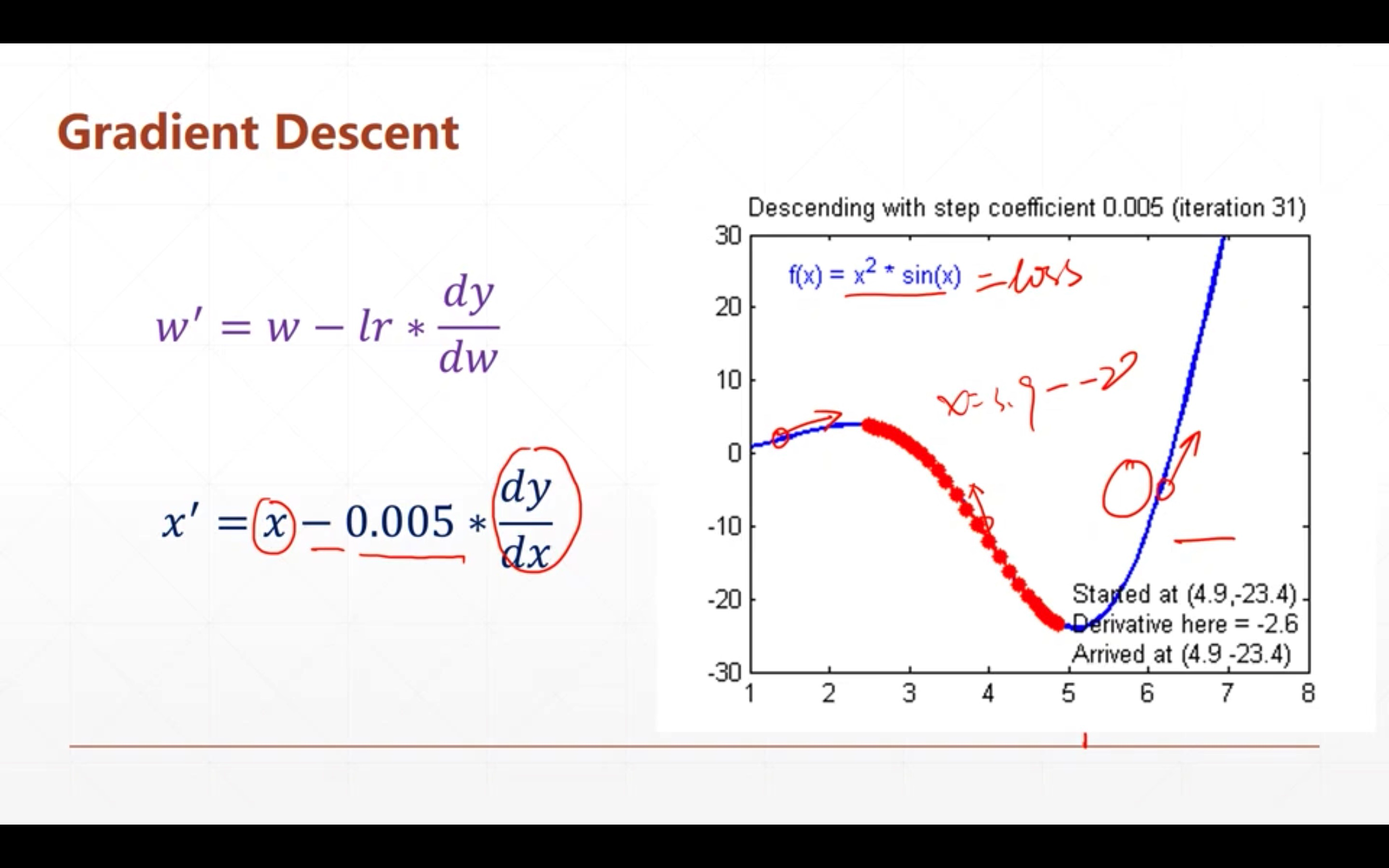
上述所示的函数就是一种凸函数,而该函数的最小值也显而易见。但是我们不能通过眼睛判断该函数的最小值,而可以通过梯度下降算法。这个算法的流程也很简单,就是按照某一点在x轴上的梯度的反方向一直前进即可。针对我们上述的\(w\)和\(b\)变量,则是:
b' = b - lr*\frac{\partial{loss}}{\partial{b}}
\]
从上式我们可以看到有一个\(lr\),其实很好理解,梯度的求解可能是一个很大的值。如上图,如果在\(x=3\)时梯度值为30,那么\(x\)按照梯度的反方向前进就变成了\(33\),很明显直接远离了最小值,因此可以通过控制\(lr\)的大小控制当\(x\)在某一点的移动范围,\(lr\)大一点则前进的快,\(lr\)小一点则前进的慢。
三、解决线性回归问题的五个步骤
从上面一节我们可以看出线性回归的流程简单点可以分为5个步骤:
- 初始化未知变量\(w=b=0\)
- 得到损失函数\(loss = \frac{1}{N}\sum_{i=1}^N{(\hat{y_i}-y_i)}^2\)
- 利用梯度下降算法更新得到\(w', b'\)
- 重复步骤3,利用\(w', b'\)得到新的更优的\(w', b'\),直至\(w', b'\)收敛
- 最后得到函数模型\(f=w'*x+b'\)
四、利用Numpy实战解决线性回归问题
步骤1代码:略
步骤2代码:计算训练数据的均方误差
def compute_error_for_line_given_points(b, w, points):
"""
y = wx + b, 计算训练数据的均方误差
:param b: 参数b,初始为0
:param w: 参数w,初始为0
:param points: 训练数据,100个二元组,如[(1,2),...,(100,200)]
:return: 均方误差
"""
total_error = 0 # 定义误差初始值
# 计算训练数据的总误差
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
# 计算总误差
total_error += ((y - w * x + b)) ** 2
return total_error / float(len(points)) # 返回均方误差
步骤3代码:计算梯度并更新w和b
def step_gradient(b_current, w_current, points, learning_rate):
"""
计算梯度并更新w和b
:param b_current: 更新前的b
:param w_current: 更新前的w
:param points: 训练数据,100个二元组,如[(1,2),...,(100,200)]
:param learning_rate: 学习速率
:return: 更新后的w和b
"""
b_gradient = 0
w_gradient = 0
N = float(len(points))
# 更新梯度
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
# grad_b = 2(w * x + b - y),b的求偏导结果
b_gradient += (2 / N) * ((w_current * x + b_current) - y) # update b
# grad_w = 2(w * x + b - y) * x,w的求偏导结果
w_gradient += (2 / N) * x * ((w_current * x + b_current) - y) # update w
# 更新后的w和b
new_b = b_current - (learning_rate * b_gradient)
new_w = w_current - (learning_rate * w_gradient)
return [new_b, new_w] # 返回更新后的w和b
步骤4代码:循环训练并更新w和b(此处我们循环训练1000次,而不是让参数收敛)
def gradient_descent_runner(points, starting_b, starting_w, learning_rate, num_iterations):
"""
循环训练并更新w和b
:param points: 数据
:param starting_b: b的初始值
:param starting_w: w的初始值
:param learning_rate: 学习速率
:param num_iterations: 训练次数
:return: 返回训练好的w和b
"""
b = starting_b
w = starting_w
# 循环更新w和b
for i in range(num_iterations):
b, w = step_gradient(b, w, points, learning_rate)
return [b, w] # 返回训练好的b和w
# 循环更新w和b
for i in range(num_iterations):
b,w = step_gradient(b,w,points,learning_rate)
return [b,w] # 返回训练好的b和w
步骤5代码:最后得到函数模型\(f=w'*x+b'\)
五、总结
本篇文章讲解了机器学习中较为简单的线性回归算法,虽然很多细节没有涉及到,例如噪声的处理和正则化问题、方差和偏差问题、多元特征回归……
但是本篇文章的核心目的还是想让大家能够利用numpy实现线性回归模型,从最后的代码中可以看出,利用numpy我们就是在把前面的各种数学语言一个一个实现,求误差、求偏导、求梯度,这还只是最简单的回归问题,如果更复杂呢?我们也这样,怕是能让你秃头。
也因此,我们不得不引出我们接下来要讲的框架,他有什么好处,他的好处就是把我们上面的是三个函数封装好了,你需要做的仅仅只是调个函数,传个参数即可。
02_利用numpy解决线性回归问题的更多相关文章
- 03_利用pytorch解决线性回归问题
03_利用pytorch解决线性回归问题 目录 一.引言 二.利用torch解决线性回归问题 2.1 定义x和y 2.2 自定制线性回归模型类 2.3 指定gpu或者cpu 2.4 设置参数 2.5 ...
- 机器学习中梯度下降法原理及用其解决线性回归问题的C语言实现
本文讲梯度下降(Gradient Descent)前先看看利用梯度下降法进行监督学习(例如分类.回归等)的一般步骤: 1, 定义损失函数(Loss Function) 2, 信息流forward pr ...
- 利用闭包解决for循环里onclick事件不能捕捉实时i值问题
问题描述 我们都知道,如果我们对于一组元素(相同的标签)同时进行onclick事件处理的时候(在需要获取到索引的时候),一般是写一个for循环,但是onclick是一个异步调用的,所以会带来一个问题, ...
- 利用Readability解决网页正文提取问题
分享: 利用Readability解决网页正文提取问题 做数据抓取和分析的各位亲们, 有没有遇到下面的难题呢? - 如何从各式各样的网页中提取正文!? 虽然可以用SS为各种网站写脚本做解析, 但是 ...
- 利用gulp解决微信浏览器缓存问题
做了好多项目,这次终于要解决微信浏览器缓存这个令人头疼的问题了.每次上传新的文件,在微信浏览器中访问时,总要先清除微信的缓存,实在麻烦,在网上搜罗了很多解决办法,终于找到了方法:利用gulp解决缓存问 ...
- 利用Json_encode解决中文问题
利用Json_encode解决中文问题 public function return_json($data=array()){ echo json_encode($data ...
- 利用Filter解决跨域请求的问题
1.为什么出现跨域. 很简单的一句解释,A系统中使用ajax调用B系统中的接口,此时就是一个典型的跨域问题,此时浏览器会出现以下错误信息,此处使用的是chrome浏览器. 错误信息如下: jquery ...
- 利用NSProxy解决NSTimer内存泄漏问题
之前写过一篇利用RunTime解决由NSTimer导致的内存泄漏的文章,最近和同事讨论觉得这样写有点复杂,然后发现有NSProxy这么好用的根类,根类,根类,没错NSProxy与NSObject一样是 ...
- 利用dynamic解决匿名对象不能赋值的问题
原文:利用dynamic解决匿名对象不能赋值的问题 关于匿名对象 匿名对象是.Net Framework 3.0提供的新类型,例如: }; 就是一个匿名类,搭配Linq,可以很灵活的在代码中组合数据, ...
随机推荐
- 「NGK每日快讯」11.20日NGK公链第17期官方快讯!
- 【目标检测】用Fast R-CNN训练自己的数据集超详细全过程
目录: 一.环境准备 二.训练步骤 三.测试过程 四.计算mAP 寒假在家下载了Fast R-CNN的源码进行学习,于是使用自己的数据集对这个算法进行实验,下面介绍训练的全过程. 一.环境准备 我这里 ...
- .net使用CSRedis操作Redis缓存的简单笔记(新手教程)
0.介绍 .NET Core or .NET Framework 4.0+ client for Redis and Redis Sentinel (2.8) and Cluster. Include ...
- HashMap什么时候进行扩容?
Threshold:table数组元素个数size的大小超过threshold且且Node<K,V>[] table数组长度没有超过64时时table数组扩容.当hashmap中的元素个数 ...
- Using Sqoop to import from db2 to hadoop
参考 : https://stackoverflow.com/questions/23933481/db2-data-import-into-hadoop sqoop import - ...
- javaMail (java代码发送邮件)
第一在邮件账户设置开启以下两个 需要发送短信获取 授权码. 代码如下: package com.hjb.javaMail; import javax.mail.*; import javax.mai ...
- 创建AD域之后设置DNS服务访问外网
AD域内需要有DNS服务器,用于解析域内的计算机名,域内的计算解析公网的域名需要设置一个转发器(Forwarder). 一定要设置好自己的默认网关.DNS因为部署在AD服务器上,直接loopback地 ...
- Docker 概述(一)
1-1 虚拟化技术发展史 在虚拟化技术出现之前,如果我们想搭建一台服务器,我们需要做如下的工作: 购买一台硬件服务器:在硬件服务器上安装配置操作系统系统:在操作系统之上配置应用运行环境:部署并运行应用 ...
- Markdown(1)介绍
一.简介 Markdown 是一种轻量级标记语言,通过简单的标记语法使纯文本内容具有一定格式,使用户可以用易读易写的纯文本格式编写文档. Markdown 语言在 2004 由约翰·格鲁伯(英 ...
- 《C++ Primer》笔记 第1章 开始
输出运算符<< 的计算结果就是其左侧运算对象 std::endl 结束当前行,并将与设备关联的缓冲区中的内容刷到设备中. 程序员常常在调试时添加打印语句.这类语句应该保证"一直& ...