Spark Core核心----RDD常用算子编程
1、RDD常用操作2、Transformations算子3、Actions算子4、SparkRDD案例实战
1、Transformations算子(lazy)
含义:create a new dataset from an existing on 从已经存在的创建一个新的数据集
RDDA---------transformation----------->RDDB
map:map(func)
将func函数作用到数据集的每一个元素上,生成一个新的分布式的
数据集返回
例子:1
data = [1, 2, 3, 4, 5]
rdd1 = sc.parallelize(data)
rdd2 = rdd1.map(lambda x:x*2)
print(rdd2.collect())
例子2:
a = sc.parallelize(["dog","tiger","lion","cat","panther","eagle"]).map(lambda x:(x,1))
print(a.collect())结果:

filter(过滤)filter(func)
选出所有func返回值为true的元素,生成一个新的分布式数据集返回
例子:
RDDA = sc.parallelize([1, 2, 3, 4, 5]).map(lambda x:x*2).filter(lambda x:x>5)
print(RDDA.collect())结果:

flatMap() flatMap(func)
输入的item能够被map到0或者多个items输出,返回值是一个Sequence (拆分)
data = ["hello spark","hello word","hello word"]
RDD = sc.parallelize(data)
print(RDD.flatMap(lambda line:line.split(" ")).collect())结果
groupByKey()(把相同的key的数据分发到一起)
data = ["hello spark", "hello word", "hello word"]
RDD = sc.parallelize(data)
RDD2 = RDD.flatMap(lambda line:line.split(" ")).map(lambda x:(x,1))
RDD3 = RDD2.groupByKey()
print(RDD3.map(lambda x:{x[0]:list(x[1])}).collect())结果
reduceByKey(把相同的key的数据分发到一起,并进行相应的计算)
data = ["hello spark", "hello word", "hello word"]
RDD = sc.parallelize(data)
RDD2 = RDD.flatMap(lambda line: line.split(" ")).map(lambda x: (x, 1))
RDD3 = RDD2.reduceByKey(lambda a,b:a+b)
print(RDD3.collect())结果
sortByKey()默认按照key值升序排列
data = ["hello spark", "hello word", "hello word"]
RDD = sc.parallelize(data)
RDD2 = RDD.flatMap(lambda line: line.split(" ")).map(lambda x: (x, 1))
RDD3 = RDD2.reduceByKey(lambda a, b: a + b)
sortRDD = RDD3.sortByKey()
sortRDD.collect()结果
加False参数降序排列

实现按照数字排序
使用map交换一下顺序

union连接(把RDD连接起来)
a = sc.parallelize([1, 2, 3])
b = sc.parallelize([4, 5, 6])
a.union(b).collect()结果
distinct(去除重复)
a = sc.parallelize([1, 2, 3])
b = sc.parallelize([4, 3, 3])
a.union(b).distinct().collect()结果
join(内连接,左外连接,右外连接)
a = sc.parallelize([("A","a1"),("C","c1"),("D","d1"),("F","f1"),("F","f2")])
b = sc.parallelize([("A","a2"),("C","c2"),("C","c3"),("E","e1")])
a.join(b).collect() # 内连接
a.rightOuterJoin(b).collect() # 右外连接
a.leftOuterJoin(b).collect() # 左外连接
a.fullOuterJoin(b).collect() # 全连接内连接:
得到两者key值相同的值的集合
右外连接:以右表key为基准进行连接

左外连接:以左表以右表key为基准进行连接

全连接:左右连接的并集所有的都出来

2、Actions算子
含义:return a value to the driver program after running acomputation on the dataset
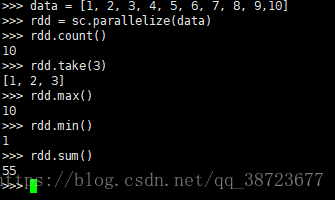
data = [1, 2, 3, 4, 5, 6, 7, 8, 9,10]
rdd = sc.parallelize(data)
rdd.count() # 数量
rdd.take(3) # 前几个
rdd.max() # 最大值
rdd.min() # 最小值
rdd.sum() # 求和
rdd.reduce(lambda x,y:x+y) # 求和
rdd.foreach(lambda x:print(x)) #foreach遍历
rdd.saveAsTextFile #写入文件系统结果:


Spark Core核心----RDD常用算子编程的更多相关文章
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- spark——详解rdd常用的转化和行动操作
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark第三篇文章,我们继续来看RDD的一些操作. 我们前文说道在spark当中RDD的操作可以分为两种,一种是转化操作(trans ...
- Spark学习之路(四)—— RDD常用算子详解
一.Transformation spark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 fu ...
- Spark 系列(四)—— RDD常用算子详解
一.Transformation spark 常用的 Transformation 算子如下表: Transformation 算子 Meaning(含义) map(func) 对原 RDD 中每个元 ...
- 4.RDD常用算子之transformations
RDD Opertions transformations:create a new dataset from an existing one RDDA --> RDDB ...
- 理解Spark的核心RDD
http://www.infoq.com/cn/articles/spark-core-rdd/
- spark core (二)
一.Spark-Shell交互式工具 1.Spark-Shell交互式工具 Spark-Shell提供了一种学习API的简单方式, 以及一个能够交互式分析数据的强大工具. 在Scala语言环境下或Py ...
- spark学习(10)-RDD的介绍和常用算子
RDD(弹性分布式数据集,里面并不存储真正要计算的数据,你对RDD的操作,他会在Driver端转换成Task,下发到Executor计算分散在多台集群上的数据) RDD是一个代理,你对代理进行操作,他 ...
- Spark Streaming核心概念与编程
Spark Streaming核心概念与编程 1. 核心概念 StreamingContext Create StreamingContext import org.apache.spark._ im ...
随机推荐
- 【路径规划】 Optimal Trajectory Generation for Dynamic Street Scenarios in a Frenet Frame (附python代码实例)
参考与前言 2010年,论文 Optimal Trajectory Generation for Dynamic Street Scenarios in a Frenet Frame 地址:https ...
- CSS 样式清单整理
1.文字超出部分显示省略号 单行文本的溢出显示省略号(一定要有宽度) p{ width:200rpx; overflow: hidden; text-overflow:ellipsis; white- ...
- YARN调度器(Scheduler)详解
理想情况下,我们应用对Yarn资源的请求应该立刻得到满足,但现实情况资源往往是有限的,特别是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能的到相应的资源.在Yarn中,负责给应用分配资 ...
- 公有云上构建云原生 AI 平台的探索与实践 - GOTC 技术论坛分享回顾
7 月 9 日,GOTC 2021 全球开源技术峰会上海站与 WAIC 世界人工智能大会共同举办,峰会聚焦 AI 与云原生两大以开源驱动的前沿技术领域,邀请国家级研究机构与顶级互联网公司的一线技术专家 ...
- MySQL检查与性能优化示例脚本
最近在玩python,为了熟悉一下python,写了个mysql的检查与性能优化建议的脚本. 虽然,真的只能算是一个半成残次品.也拿出来现眼一下. 不过对于初学者来说,还是有一定的参考价值的.比如说如 ...
- 记一次Hvv中遇到的API接口泄露而引起的一系列漏洞
引言 最近朋友跟我一起把之前废弃的公众号做起来了,更名为鹿鸣安全团队,后面陆续会更新个人笔记,有趣的渗透经历,内网渗透相关话题等,欢迎大家关注 前言 Hvv中的一个很有趣的漏洞挖掘过程,从一个简单的A ...
- DataGridView 显示行号与背景颜色
实现的方式有好几种.之前使用的是下面这种在RowPostPaint事件中实现,效率不高.每次改变控件尺寸时都会执行 private void MsgGridView_RowPostPaint(obje ...
- Nginx负载均衡反向代理服务器
1.第一步先在IIS中创建多个网站,分别用不同的端口号.这里创建两个网站端口号分别8084.8085,在Nginx配置中会用到.测试两个网站能正常访问. 2.配置Nginx 1)增加负载均衡请求列表 ...
- tomcat与springmvc 结合 之---第19篇 springmvc 加载.xml文件的bean 过程
writedby 张艳涛,看springmvc 的源码太难了,怎么办, 这篇文章主要分析了看透springmvc的第9章结尾的 如何解析xml 命名空间标签 <?xml version=&quo ...
- JS 实现一个 LRU 算法
LRU 是 Least Recently Used 的缩写,即最近最少使用,是一种常用的页面置换算法,选择内存中最近最久未使用的页面予以淘汰. 可用的 NodeJS 库见node-lru-cache ...