Lucene全文检索(一)
全文检索的概念
1.从大量的信息中快速、准确的查找要的信息
2.收索的内容是文本信息
3.不是根据语句的意思进行处理的(不处理语义)
4.全面、快速、准确是衡量全文检索系统的关键指标。
5.搜索时英文不区分大小写,结果列表有相关度排序。
全文检索与数据库搜索的区别
1.数据库搜索
Eg: select * from article where content like ‘%here%’
结果where here
缺点:
1).搜索效果比较差
2).在搜索的结果中,有大量的数据被搜索出来,有很多数据是没有用的
3).查询速度在大量数据的情况下是很难做到快速的
2.全文检索
1).搜索结果按相关度排序,这意味着只有前几个页面对用户来说是比较有用的,其他的结果与用户想要的答案可能相差甚远。数据库搜索时做不到相关度排序的。
2).因为全文检索是采用索引的方式,所以在速度上肯定比数据库方式like要快。
3).所以数据库不能代替全文检索。
Lucene
Lucene:全文检索只是一个概念,而具体实现有很多框架,lucene是其中的一种。
Lucene结构图

说明:
1.索引库中的索引数据是在磁盘上存在的,我们用Directory这个类来描述。
2.我们可以通过API来实现对索引库的增、删、改、查的操作
3.在索引库中各种数据形式可以抽象出一种数据格式Document
4.Document的结构为:Document(List<Field>)
5.Field里存放一个键值对。键值对都为字符串的形式。
6.对索引库中索引的操作实际上也是对Document的操作。
Lucene入门案例
1.搭建工程环境,并导入所需的jar包,至少需要以下四个jar包
lucene-core-3.1.0.jar(核心包)
lucene-analyzers-3.1.0.jar(分词器)
lucene-highlighter-3.1.0.jar(高亮器)
lucene-memory-3.1.0.jar(高亮器)
2.建立索引
步骤:
1)创建IndexWriter对象
2)把JavaBean转化为Document
3)利用IndexWriter.addDocument方法增加索引
4)关闭资源
Eg:
package cn.lsl.lucene.demo; import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test; /*
* 功能1:把一个文章放入索引库中
* */
public class LuceneDemo { @Test
public void testCreatIndex() throws IOException{
//1.获取文章内容
Article article = new Article();
article.setId(1);
article.setTitle("lucene");
article.setContent("提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。");
//把文章放入到索引库中
Directory directory = FSDirectory.open(new File("./indexDir")); //Directory 索引库
//分词器
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
//构造indexWriter对象
IndexWriter indexWriter = new IndexWriter(directory,analyzer,MaxFieldLength.LIMITED);
//把Article转化为Document
Document doc = new Document();
Field idField = new Field("id",article.getId().toString(), Store.YES, Index.NOT_ANALYZED);
Field titleField = new Field("title",article.getTitle(),Store.YES,Index.ANALYZED);
Field contentField = new Field("content",article.getContent(), Store.YES, Index.ANALYZED);
doc.add(idField);
doc.add(titleField);
doc.add(contentField);
indexWriter.addDocument(doc);
indexWriter.close();
}
}
原理图
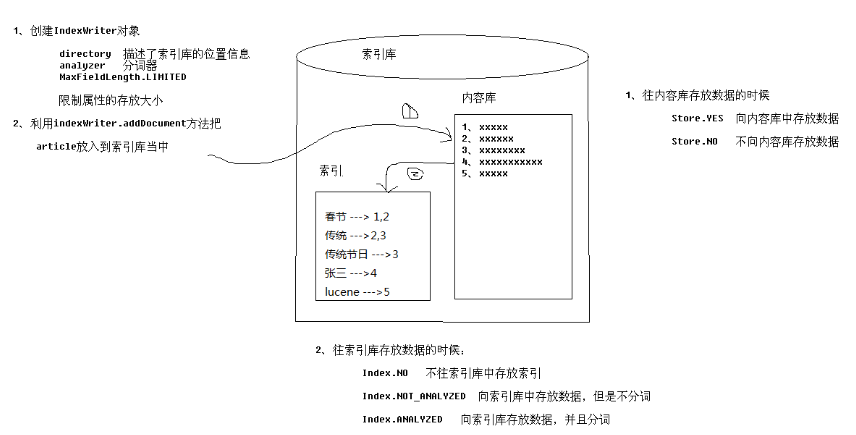
注:Store这个参数表明是否将内容存放到索引内容中
Index这个参数表明是否存放关键字到索引目录中。
3.进行搜索
步骤:
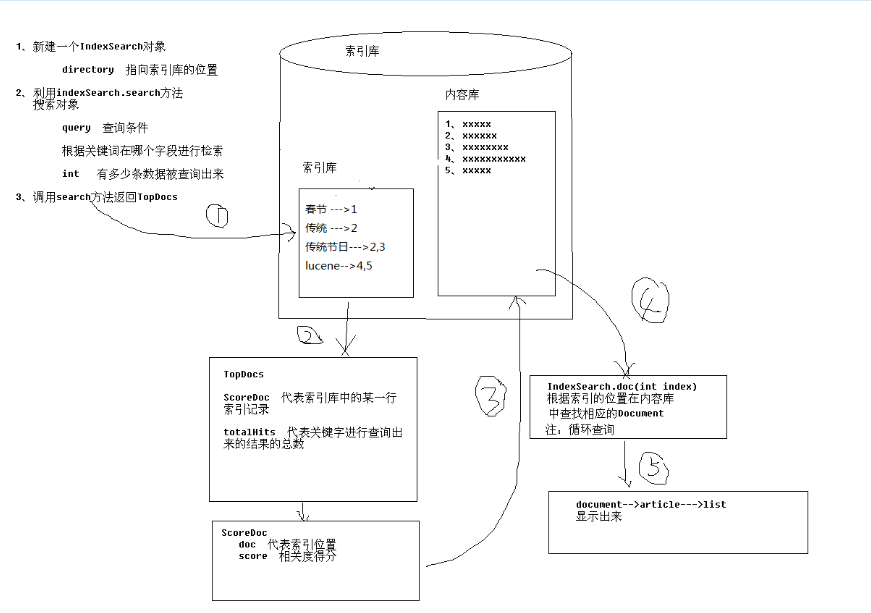
1)创建IndexSeacher对象
2)创建Query对象
3)进行搜索
4)获得总结果数和前N行记录ID列表
5)根据目录ID把列表Document转化为JavaBean并放入集合中
6)循环出要检索的内容
Eg:
package cn.lsl.lucene.demo; import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test; /*
* 功能:从索引库中把文章检索出来
* */
public class LuceneDemo { //从索引库中吧文章检索出来 @Test
public void testSearch() throws IOException, ParseException{
//1.创建IndexSearch对象
Directory directory = FSDirectory.open(new File("./indexDir"));
IndexSearcher indexSearcher = new IndexSearcher(directory);
//2.创建Query对象
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
QueryParser queryParser = new MultiFieldQueryParser(Version.LUCENE_30, new String[]{"title","content"},analyzer);
//参数为要检索的关键字
Query query = queryParser.parse("lucene");
//3.进行搜索
//query 搜索的条件, 显示N行记录,TopDocs 目录的结果
TopDocs topDocs = indexSearcher.search(query, 10);
//4.获取总记录数和前N行的目录ID列表
ScoreDoc[] scoreDocs = topDocs.scoreDocs; int count = topDocs.totalHits; //总记录数
System.out.println("总记录数:" + count); //5.根据目录的行ID获取每行的document,并吧Article放入集合中
List<Article> articleList = new ArrayList<Article>();
for (int i = 0; i < scoreDocs.length; i++) {
int index = scoreDocs[i].doc; //索引位置,即目录列表ID
float score = scoreDocs[i].score; //相关度得分
System.out.println("得分:"+ score);
Document document = indexSearcher.doc(index);
//把Document转化为Article
Article article = new Article();
article.setId(Integer.valueOf(document.get("id").toString()));
article.setTitle(document.get("title"));
article.setContent(document.get("content"));
articleList.add(article);
} for (Article article : articleList) {
System.out.println("id:" + article.getId());
System.out.println("title:" + article.getTitle());
System.out.println("content:" + article.getContent());
}
}
}
原理图:
保持数据库与索引库同步
在一个系统中,如果索引功能存在,那么数据库和索引库应该是同时存在的。这个时候需要保证索引库的数据和数据库中的数据保持一致性。可以在对数据库进行增删改查操作的同时对索引库也进行相应的操作。这样就可以保持数据库与索引库的一致性。
Lucene的增删改查及API详解
创建工具类:
LuceneConfig.java
package cn.lsl.lucene.util; import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version; public class LuceneConfig {
public static Analyzer analyzer;
public static Directory directory;
static{
try {
analyzer = new StandardAnalyzer(Version.LUCENE_30);
directory = FSDirectory.open(new File("./indexDir"));
} catch (IOException e) {
e.printStackTrace();
}
}
}
注意:LuceneConfig这个类对Directory和Analyzer进行了包装。
因为在创建IndexWriter时,需要用到这两个类,而管理索引库的操作也都要用到IndexWriter这个类,所以我们对Directory和Analyzer进行了包装
LuceneUtils.java
package cn.lsl.lucene.util; import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength; public class LuceneUtils {
public static IndexWriter indexWriter; private LuceneUtils(){} public static IndexWriter getIndexWriter() throws Exception {
if(indexWriter == null){
indexWriter = new IndexWriter(LuceneConfig.directory,LuceneConfig.analyzer,MaxFieldLength.LIMITED);
}
return indexWriter;
}
}
LuceneUtils类对创建IndexWriter进行了封装
因为在一个索引库中只能存在一个IndexWriter对象。(同一个索引库只能有一个IndexWriter进行操作)
所以我们这里采用了单例的模式进行了封装。
DocumentUtils.java
(把JavaBean封装成Document和把Document封装成JavaBean的过程。)
package cn.lsl.lucene.util; import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.util.NumericUtils;
import cn.lsl.lucene.demo.Article; public class DocumentUtils {
public static Document article2Document(Article article){
Document document = new Document();
Field idField = new Field("id",article.getId().toString(), Store.YES, Index.NOT_ANALYZED);
Field titleField = new Field("title",article.getTitle(), Store.YES, Index.ANALYZED);
Field contentField = new Field("content",article.getContent(), Store.YES, Index.ANALYZED);
document.add(idField);
document.add(titleField);
document.add(contentField);
return document;
} public static Article document2Article(Document document){
Article article = new Article();
article.setId(Integer.valueOf(document.get("id")));
article.setTitle(document.get("title"));
article.setContent(document.get("content"));
return article;
}
}
什么情况下使用Index.NOT_ANALYZED
当这个属性的值代表的是一个不可分割的整体,例如ID
什么情况下使用Index.ANALYZED
当这个属性的值代表是一个可分割的整体
LuceneManager.java(增删改查例子)
package cn.lsl.lucene.manager; import java.util.ArrayList;
import java.util.List; import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.util.Version;
import org.junit.Test; import cn.lsl.lucene.demo.Article;
import cn.lsl.lucene.util.DocumentUtils;
import cn.lsl.lucene.util.LuceneConfig;
import cn.lsl.lucene.util.LuceneUtils; public class LuceneManager { @Test
public void testCreateIndex() throws Exception{
IndexWriter indexWriter = LuceneUtils.getIndexWriter();
Article article = new Article();
article.setId(1);
article.setTitle("lucene");
article.setContent("全文检索");
Document doc = DocumentUtils.article2Document(article);
indexWriter.addDocument(doc);
indexWriter.close();
} @Test
public void testUpdateIndex() throws Exception{
IndexWriter indexWriter = LuceneUtils.getIndexWriter();
Term term = new Term("id","1");
Article article = new Article();
article.setId(1);
article.setTitle("baidu");
article.setContent("百度一下,你就知道");
/*term 关键字 用来进行删除的
* document 是用来进行增加的
* */
indexWriter.updateDocument(term, DocumentUtils.article2Document(article));
indexWriter.close();
} @Test
public void testDeleteIndex() throws Exception{
IndexWriter indexWriter = LuceneUtils.getIndexWriter();
//term 关键字
Term term = new Term("id","1");
indexWriter.deleteDocuments(term);
indexWriter.close();
} @Test
public void testQueryIndex() throws Exception{
IndexSearcher indexSearcher = new IndexSearcher(LuceneConfig.directory); List<Article> articleList = new ArrayList<Article>();
QueryParser queryParser = new MultiFieldQueryParser(Version.LUCENE_30, new String[]{"title","content"}, LuceneConfig.analyzer);
Query query = queryParser.parse("lucene");
TopDocs topDocs = indexSearcher.search(query, 10); //索引库
ScoreDoc[] scoreDocs = topDocs.scoreDocs;//索引库数组
int count = topDocs.totalHits; //总记录数
for (int i = 0; i < scoreDocs.length; i++) {
int index = scoreDocs[i].doc; //得到相关的索引
float score = scoreDocs[i].score; //相关度得分
Document document = indexSearcher.doc(index);
Article article = DocumentUtils.document2Article(document);
articleList.add(article);
} for (Article article : articleList) {
System.out.println(article.getId());
System.out.println(article.getTitle());
System.out.println(article.getContent());
}
}
}
Lucene全文检索(一)的更多相关文章
- Apache Lucene(全文检索引擎)—创建索引
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- Lucene全文检索技术
Lucene全文检索技术 今日大纲 ● 搜索的概念.搜索引擎原理.倒排索引 ● 全文索引的概念 ● 使用Lucene对索引进行CRUD操作 ● Lucene常用API详解 ● ...
- 使用Lucene全文检索并使用中文版和高亮显示
使用Lucene全文检索并使用中文版和高亮显示 中文分词需要引入 中文分词发的jar 包,咱们从maven中获取 <!-- lucene中文分词器 --> <dependency&g ...
- lucene全文检索基础
全文检索是一种将文件中所有文本与检索项匹配的文字资料检索方法.比如用户在n个小说文档中检索某个关键词,那么所有包含该关键词的文档都返回给用户.那么应该从哪里入手去实现一个全文检索系统?相信大家都听说过 ...
- lucene 全文检索工具的介绍
Lucene:全文检索工具:这是一种思想,使用的是C语言写出来的 1.Lucene就是apache下的一个全文检索工具,一堆的jar包,我们可以使用lucene做一个谷歌和百度一样的搜索引擎系统 2. ...
- Lucene 全文检索 Lucene的使用
Lucene 全文检索 Lucene的使用 一.简介: 参考百度百科: http://baike.baidu.com/link?url=eBcEVuUL3TbUivRvtgRnMr1s44nTE7 ...
- Lucene全文检索_分词_复杂搜索_中文分词器
1 Lucene简介 Lucene是apache下的一个开源的全文检索引擎工具包. 1.1 全文检索(Full-text Search) 1.1.1 定义 全文检索就是先分词创建索引,再执行搜索的过 ...
- Lucene 全文检索
基于 lucene 8 1 Lucene简介 Lucene是apache下的一个开源的全文检索引擎工具包. 1.1 全文检索(Full-text Search) 全文检索就是先分词创建索引,再执行搜索 ...
- Apache Lucene(全文检索引擎)—分词器
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- lucene全文检索---打酱油的日子
检索内容,一般的程序员第一时间想到的是sql的like来做模糊查询,其实这样的搜索是比较耗时的.已经有lucene帮我们 封装好了,lucene采用的是分词检索等策略. 1.lucene中的类描述 I ...
随机推荐
- MS SQL Server递归查询
原文:MS SQL Server递归查询 刚才在论坛上看到网友一个要求.参考如下,Insus.NET分析一下,可以使用MS SQL Server的递归查询,得到结果.准备一张表: 根据网友提供的数据, ...
- NET Framework 4.5 五个新特性
.NET Framework 4.5 五个新特性 Framework 4.5 已经开发了几个项目了,想去研究一下VS 2015 里面的跨平台..不过好像4.5内核新特性还没搞明白呢还是先看看4.5内核 ...
- c#-Artificial Intelligence Class
NET Artificial Intelligence Class http://www.codeproject.com/KB/recipes/aforge_neuro/neuro_src.zip
- IE6下jquery ajax报error的原因
用jquery ajax()方法,在其他浏览都通过,IE7以上都通过,唯独在ie6不行. 我这边的解决方案是:必须保证ajax里面的所有数字为小写,ie6对大小写敏感. 错误: $.ajax({ ur ...
- Sql Server 存储过程中查询数据无法使用 Union(All)
原文:Sql Server 存储过程中查询数据无法使用 Union(All) 微软Sql Server数据库中,书写存储过程时,关于查询数据,无法使用Union(All)关联多个查询. 1.先看一段正 ...
- 在vi中使用perltidy格式化perl代码
格式优美的perl代码不但让人赏心悦目,并且能够方便阅读. perltidy的是sourceforge的一个小项目,在我们写完乱七八糟的代码后,他能像变魔术一样把代码整理得漂美丽亮,快来体验一下吧!! ...
- C# 对Outlook联系人的增、删、查
原文:C# 对Outlook联系人的增.删.查 [转] 注:定义变量 Outlook.Application myOlApp = new Outlook.ApplicationClass(); Out ...
- String 的intern() 方法说明
1.说明 Java中string.intern()方法调用会先去字符串常量池中查找相应的字符串,如果字符串不存在,就会在字符串常量池中创建该字符串然后再返回. 2.源码说明 public native ...
- solr主从复制
solr主从复制 最近的开发工作涉及到两个模块“任务”和“日周报”.关系是日周报消费任务,因为用户在写日周报的时候,需要按一定的规则筛选当前用户的任务,作为日周报的一部分提交.整个项目采用类似于Orc ...
- ubuntu下使用openocd+jlink进行STM32开发调试
安装openocd就不用多说了,使用 apt-get install openocd 这个命令就可以做到. 对于使用stm32w系列的MCU,需要下载新的openocd-0.7及以上版本才能支持.0. ...