Accord.Net中决策树
Accord.Net中决策树
决策树介绍
决策树是一类机器学习算法,可以实现对数据集的分类、预测等。具体请阅读我另一篇博客(http://www.cnblogs.com/twocold/p/5424517.html)。
Accord.Net
Accord.Net(http://accord-framework.net/)是一个开源的.Net环境下实现的机器学习算法库。并且还包括了计算机视觉、图像处理、数据分析等等许多算法,并且基本上都是用C#编写的,对于.Net程序员十分友好。代码在Github托管,并且现在仍在维护中。(https://github.com/accord-net/framework)。此处不再具体介绍,有兴趣的可以去官网或者Github下载文档和代码深入了解。此处只简单介绍决策树部分的实现和使用方法。
决策树结构
决策树、顾名思义,肯定是一个和树结构,作为最基础的数据结构之一,我们深知树结构的灵活性。那么Accord.Net是如何实现这种结构的呢?看类图
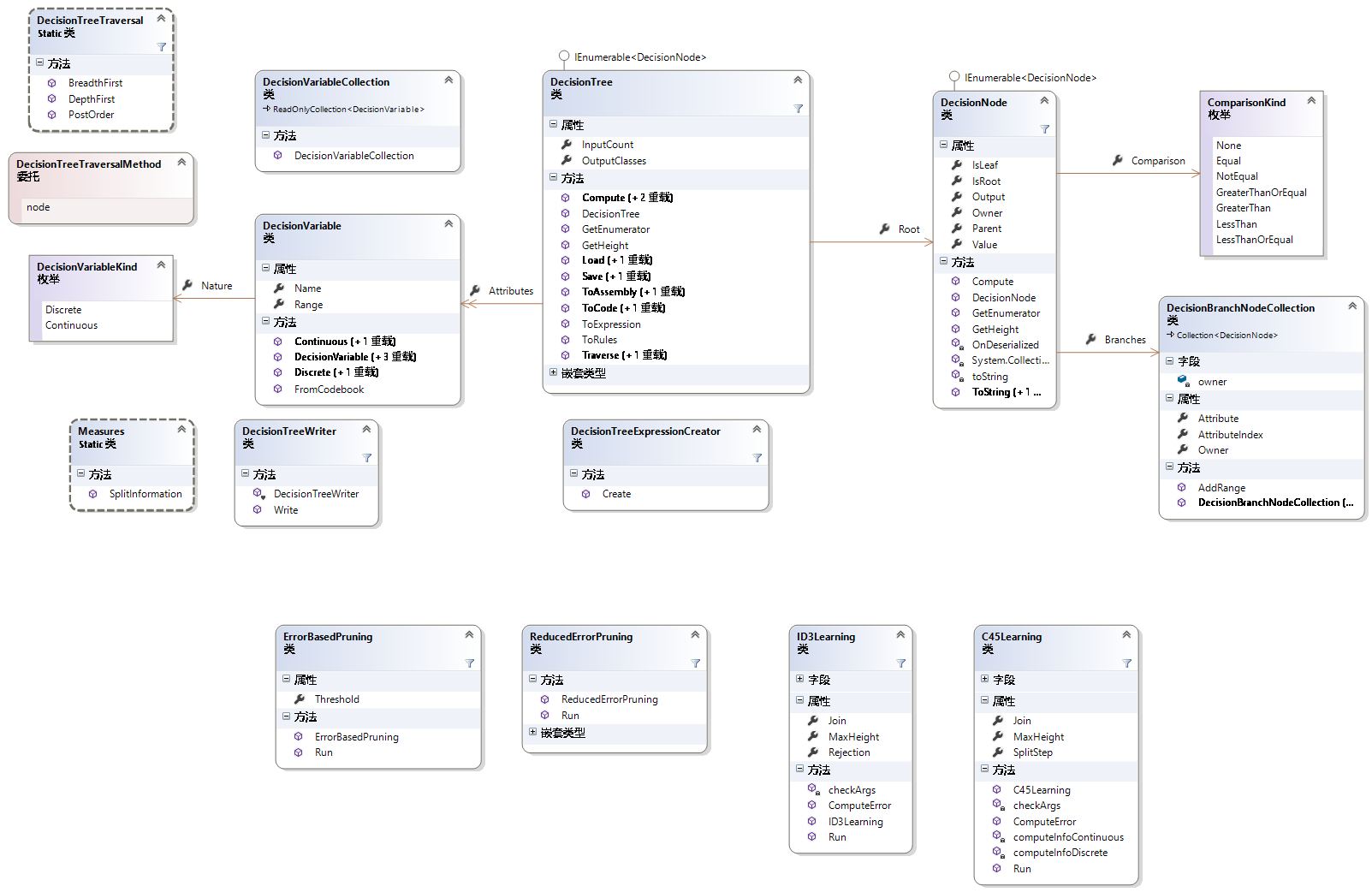
首先观察树结构中最重要的一个结构,Node类的类图如下:

简单介绍下主要属性方法。
|
属性 |
含义 |
|
IsLeaf |
是否为叶子节点 |
|
IsRoot |
是否为根节点 |
|
Output |
指示结点的类别信息(叶子节点可用) |
|
Value |
为非根节点时,表示其父节点分割特征的值 |
|
Branches |
为非叶子节点时,表示其子结点的集合 |
还有树结构:

|
属性、方法 |
含义 |
|
Root |
根节点 |
|
Attributes |
标识各个特征的信息(连续、离散、范围) |
|
InputCount |
特征个数 |
|
OutputClasses |
输出类别种数 |
|
Compute() |
计算出某一样本的类别信息 |
|
Load(),Save() |
将决策树存储到文件或者读出 |
|
ToAssembly() |
存储到dll程序集中 |
还有其他依赖项就不再逐一介绍了,Accord的官方文档里都有更加清晰的讲解。
主要想要说的是ID3Learning和C45Learning两个类。这是Accord.Net实现的两个决策树学习(训练)算法,ID3算法和C4.5算法(ID为Iterative Dichotomiser的缩写,迭代二分器;C是Classifier的缩写,即第4.5代分类器)。后面会介绍两者的区别。
决策树学习算法:
这里以一个经典的打网球的例子,介绍ID3算法的学习过程。要理解下面的代码可能需要对决策树的学习过程有个基本的了解,可以参考开头给出的链接学习下决策树的基本概念。
|
Mitchell's Tennis Example |
|||||
|
Day |
Outlook |
Temperature |
Humidity |
Wind |
PlayTennis |
|
D1 |
Sunny |
Hot |
High |
Weak |
No |
|
D2 |
Sunny |
Hot |
High |
Strong |
No |
|
D3 |
Overcast |
Hot |
High |
Weak |
Yes |
|
D4 |
Rain |
Mild |
High |
Weak |
Yes |
|
D5 |
Rain |
Cool |
Normal |
Weak |
Yes |
|
D6 |
Rain |
Cool |
Normal |
Strong |
No |
|
D7 |
Overcast |
Cool |
Normal |
Strong |
Yes |
|
D8 |
Sunny |
Mild |
High |
Weak |
No |
|
D9 |
Sunny |
Cool |
Normal |
Weak |
Yes |
|
D10 |
Rain |
Mild |
Normal |
Weak |
Yes |
|
D11 |
Sunny |
Mild |
Normal |
Strong |
Yes |
|
D12 |
Overcast |
Mild |
High |
Strong |
Yes |
|
D13 |
Overcast |
Hot |
Normal |
Weak |
Yes |
|
D14 |
Rain |
Mild |
High |
Strong |
No |
首先,为了后面进一步构造决策树,我们需要把上面的数据简化一下,以字符串存储和进行比较会消耗大量的内存空间,并且降低效率。考虑到所有特征都为离散特征,可以直接用最简单的整型表示就行,只要保存下数字和字符串的对应关系就行。Accord.Net用了CodeBook来实现,这里也就不具体介绍了。然后需要对树的一些属性进行初始化,比如特征的个数(InputCount),类别数(OutputClasses)。还有每个特征可能的取值个数。接下来就可以利用上面codebook转义过的样本数据进行构造了。
下面贴出ID3算法中递归方法的伪代码,大致讲解下其实现逻辑(注:此代码删去了很多细节,因此无法运行,只大概了解其实现逻辑。)。

/// <summary>
/// 决策树学习的分割构造递归方法
/// </summary>
/// <param name="root">当前递归结点</param>
/// <param name="input">输入样本特征</param>
/// <param name="output">样本对应类别</param>
/// <param name="height">当前结点层数</param>
private void split(DecisionNode root, int[][] input, int[] output, int height)
{
//递归return条件 //1.如果output[]都相等,就是说当前所有样本类别相同,则递归结束。结点标记为叶子节点,output值标识为样本类别值 double entropy = Statistics.Tools.Entropy(output, outputClasses); if (entropy == 0)
{
if (output.Length > 0)
root.Output = output[0];
return;
} //2.如果当前路径上所有特征都用过一次了,也就是说现在所有样本在所有特征上取值相同,也就没法划分了;递归结束。结点标记为叶子节点,output值标识为样本类别值最多的那个 //这个变量存储的是还未使用的特征个数
int candidateCount = attributeUsageCount.Count(x => x < 1); if (candidateCount == 0)
{
root.Output = Statistics.Tools.Mode(output);
return;
} // 如果需要继续分裂,则首先寻找最优分裂特征,
// 存储剩余所有可以特征的信息增益大小
double[] scores = new double[candidateCount];
// 循环计算每个特征分裂时的信息增益存储到scores里 Parallel.For(0, scores.Length, i => {
scores[i] = computeGainRatio(input, output, candidates[i],
entropy, out partitions[i], out outputSubs[i]);
} // 获取到最大信息增益对应的特征
int maxGainIndex = scores.Max();
// 接下来 需要按照特征的值分割当前的dataset,然后传递给子节点 递归
DecisionNode[] children = new DecisionNode[maxGainPartition.Length]; for (int i = 0; i < children.Length; i++)
{
int[][] inputSubset = input.Submatrix(maxGainPartition[i]); split(children[i], inputSubset, outputSubset, height + 1); // 递归每个子节点 } root.Branches.AddRange(children); }
此代码仅为方便理解,具体实现细节请自行下载Accord源代码阅读,相信您会有不少收获。
C4.5的实现与ID3算法流程基本相同,有几个不同之处
1) 在选择最优分割特征时,ID3算法采用的是信息增益,C4.5采用的是增益率。
2) C4.5支持连续型特征,因此,在递归进行之前,要采用二分法计算出n-1个候选划分点,将这些划分点当做离散变量处理就和ID3过程一致了。同样是因为连续型变量,这样一条路径下连续型特征可以多次用来分割,而离散型特征每个只能用一次。
3) C4.5支持缺失值的处理,遗憾的是Accord中并没有加入这一特性。
Accord.Net中还给出了简单的剪枝算法,有兴趣可以自行阅读。
以上面的打网球例子,这里给出Accord.Net中构造和训练决策树的代码示例。
//数据输入 存储为DataTable
DataTable data = new DataTable("Mitchell's Tennis Example");
data.Columns.Add("Day");
data.Columns.Add("Outlook");
data.Columns.Add("Temperature");
data.Columns.Add("Humidity");
data.Columns.Add("Wind");
data.Columns.Add("PlayTennis"); data.Rows.Add("D1", "Sunny", "Hot", "High", "Weak", "No");
data.Rows.Add("D2", "Sunny", "Hot", "High", "Strong", "No");
data.Rows.Add("D3", "Overcast", "Hot", "High", "Weak", "Yes");
data.Rows.Add("D4", "Rain", "Mild", "High", "Weak", "Yes");
data.Rows.Add("D5", "Rain", "Cool", "Normal", "Weak", "Yes");
data.Rows.Add("D6", "Rain", "Cool", "Normal", "Strong", "No");
data.Rows.Add("D7", "Overcast", "Cool", "Normal", "Strong", "Yes");
data.Rows.Add("D8", "Sunny", "Mild", "High", "Weak", "No");
data.Rows.Add("D9", "Sunny", "Cool", "Normal", "Weak", "Yes");
data.Rows.Add("D10", "Rain", "Mild", "Normal", "Weak", "Yes");
data.Rows.Add("D11", "Sunny", "Mild", "Normal", "Strong", "Yes");
data.Rows.Add("D12", "Overcast", "Mild", "High", "Strong", "Yes");
data.Rows.Add("D13", "Overcast", "Hot", "Normal", "Weak", "Yes");
data.Rows.Add("D14", "Rain", "Mild", "High", "Strong", "No");
// 创建一个CodeBook对象,用于将data中的字符串“翻译”成整型
Codification codebook = new Codification(data,
"Outlook", "Temperature", "Humidity", "Wind", "PlayTennis");
// 将data中的样本特征数据部分和类别信息分别转换成数组
DataTable symbols = codebook.Apply(data);
int[][] inputs = Matrix.ToArray<double>(symbols, "Outlook", "Temperature", "Humidity", "Wind");
int[] outputs = Matrix.ToArray<int>(symbols, "PlayTennis");
//分析得出每个特征的信息,如,每个特征的可取值个数。
DecisionVariable[] attributes = DecisionVariable.FromCodebook(codebook, "Outlook", "Temperature", "Humidity", "Wind"); int classCount = 2; //两种可能的输出,打网球和不打 //根据参数初始化一个树结构
DecisionTree tree = new DecisionTree(attributes, classCount); // 创建一个ID3训练方法
ID3Learning id3learning = new ID3Learning(tree); // 训练该决策树
id3learning.Run(inputs, outputs); //现在即可使用训练完成的决策树预测一个样本,并借助codebook“翻译”回来
string answer = codebook.Translate("PlayTennis",tree.Compute(codebook.Translate("Sunny", "Hot", "High", "Strong")));
贴一张利用决策树做的小例子。

Accord.Net中决策树的更多相关文章
- 决策树简单介绍(二) Accord.Net中决策树的实现和使用
决策树介绍 决策树是一类机器学习算法,可以实现对数据集的分类.预测等.具体请阅读我另一篇博客(http://www.cnblogs.com/twocold/p/5424517.html). Accor ...
- Spark中决策树源码分析
1.Example 使用Spark MLlib中决策树分类器API,训练出一个决策树模型,使用Python开发. """ Decision Tree Classifica ...
- 决策树在sklearn中的实现
1 概述 1.1 决策树是如何工作的 1.2 构建决策树 1.2.1 ID3算法构建决策树 1.2.2 简单实例 1.2.3 ID3的局限性 1.3 C4.5算法 & CART算法 1.3.1 ...
- 决策树之 CART
继上篇文章决策树之 ID3 与 C4.5,本文继续讨论另一种二分决策树 Classification And Regression Tree,CART 是 Breiman 等人在 1984 年提出的, ...
- Accord.NET_Naive Bayes Classifier
我们这个系列主要为了了解并会使用Accord.NET中机器学习有关算法,因此主要关注的是算法针对的的问题,算法的使用.所以主要以代码为主,通过代码来学习,在脑海中形成一个轮廓.下面就言归正传,开始贝叶 ...
- day-7 一个简单的决策树归纳算法(ID3)python编程实现
本文介绍如何利用决策树/判定树(decision tree)中决策树归纳算法(ID3)解决机器学习中的回归问题.文中介绍基于有监督的学习方式,如何利用年龄.收入.身份.收入.信用等级等特征值来判定用户 ...
- sklearn中随机森林的参数
一:sklearn中决策树的参数: 1,criterion: ”gini” or “entropy”(default=”gini”)是计算属性的gini(基尼不纯度)还是entropy(信息增益),来 ...
- 决策树原理实例(python代码实现)
决策数(Decision Tree)在机器学习中也是比较常见的一种算法,属于监督学习中的一种.看字面意思应该也比较容易理解,相比其他算法比如支持向量机(SVM)或神经网络,似乎决策树感觉“亲切”许多. ...
- Spark2.0机器学习系列之3:决策树
概述 分类决策树模型是一种描述对实例进行分类的树形结构. 决策树可以看为一个if-then规则集合,具有“互斥完备”性质 .决策树基本上都是 采用的是贪心(即非回溯)的算法,自顶向下递归分治构造. 生 ...
随机推荐
- 它们偷偷干了啥?教你监督APP的运行
由于Android系统的开放性,很多APP都会在后台运行各种我们不知道的权限,不仅泄露我们隐私,也给系统本身带来极大安全隐患.而且现在很普遍的是,在安装APP时它总会索取特别多的权限,又是拍照又是地理 ...
- android studio 报错,google后无果
你可能在环境变量中配置了adk的环境变量,同时eclipse可studio公用一个avd,在两个之间切换时过出错
- iOS 获取当前时间以及计算年龄(时间差)
获取当前时间 NSDate *now = [NSDate date]; NSLog(@"now date is: %@", now); NSCalendar *calendar = ...
- (转载)QT中PRO文件写法的详细介绍,很有用,很重要!
版权声明:本文为博主原创文章,未经博主允许不得转载. 在QT中,有一个工具qmake可以生成一个makefile文件,它是由.pro文件生成而来的,.pro文件的写法如下: 1. 注释从“#”开始,到 ...
- js显示时间
function nowTime(){ var data= new Date(); var y=data.getFullYear(); var m=parseInt(data.getMonth())+ ...
- 阿里巴巴 web前端性能优化进阶路
Web前端性能优化WPO,相信大多数前端同学都不会陌生,在各自所负责的站点页面中,也都会或多或少的有过一定的技术实践.可以说,这个领域并不缺乏成熟技术理论和技术牛人:例如Yahoo的web站点性能优化 ...
- 浅谈数据库技术,磁盘冗余阵列,IP分配,ECC内存,ADO,DAO,JDBC
整理-----数据库技术,磁盘冗余阵列,IP分配, ECC内存,ADO, DAO,JDBC 1.MySQL MySQL是最受欢迎的开源SQL数据库管理系统,它由 MySQL AB开发.发布和支持.My ...
- iframe - 基本用法
· 用target的值,指向iframe框架的name值. <body> <form id="form1" runat="server"> ...
- fzu 1911 C. Construct a Matrix
C. Construct a Matrix Time Limit: 1000ms Case Time Limit: 1000ms Memory Limit: 32768KB Special Judge ...
- Boost Thread学习笔记
thread自然是boost::thread库的主 角,但thread类的实现总体上是比较简单的,前面已经说过,thread只是一个跨平台的线程封装库,其中按照所使用的编译选项的不同,分别决定使用 W ...