tidyverse生态链
library(tidyverse)
mpg
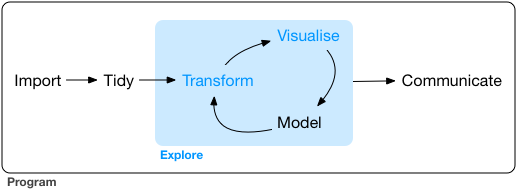
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy))
数据 : ggplot 的数据集必须是一个数据框,这里我们的数据是 mpg
图形属性映射:将数据变量映射到图形中,我们这里使用 aes(x = displ, y = hwy) 把 x 坐标映射到排气量,y 坐标映射到每公里耗油量
几何对象 : geom 代表几何对象,比如我们这里想画散点图,就用 geom_point 来生成散点图
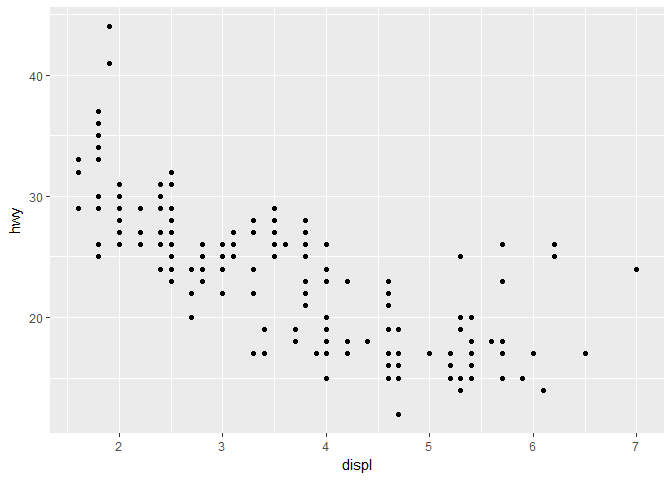
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy, color = class))
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(~ class)
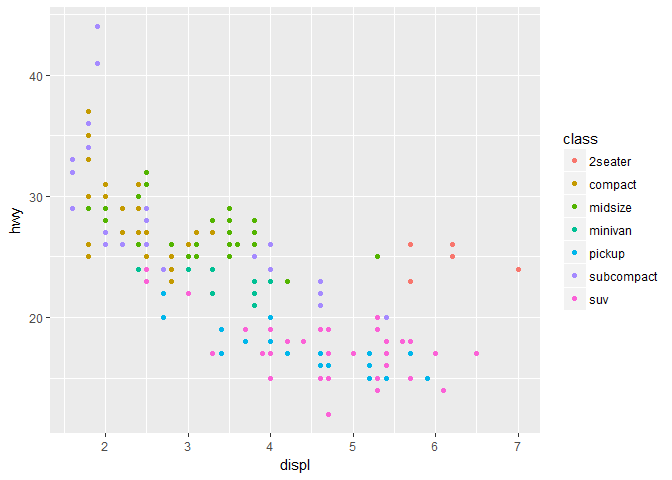
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
geom_smooth(mapping = aes(x = displ, y = hwy))
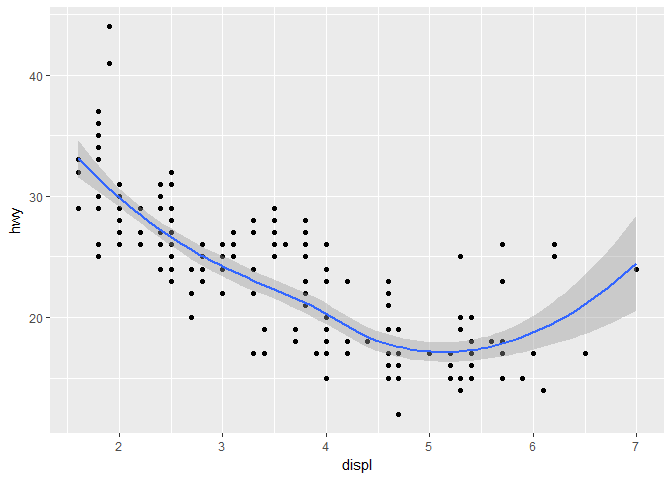
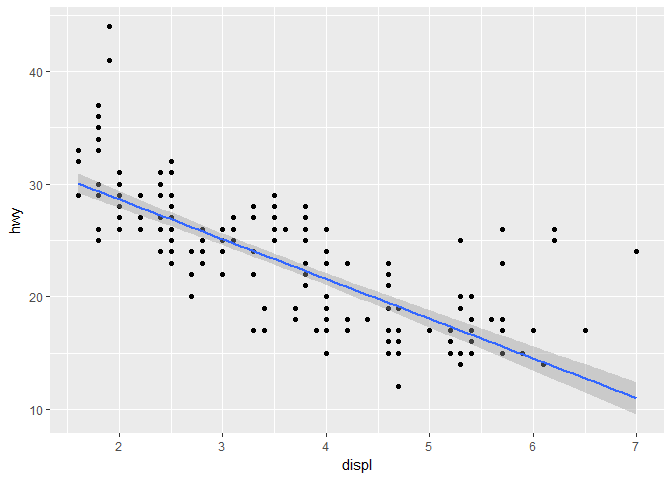
ggplot(mpg , aes(x = displ, y = hwy)) +
geom_point() +
geom_smooth(method = "lm")
mpg %>% filter(displ >=5 , hwy < 20)
mpg %>% filter(displ >=5 , hwy < 20) %>% arrange(desc(year) , hwy)
mpg %>% filter(displ >=5 , hwy < 20) %>% arrange(desc(year) , hwy) %>% select(model)
mpg %>% mutate(ave_displ= displ / cyl) %>% select(ave_displ)
var(mpg %>% mutate(ave_displ= displ / cyl) %>% select(ave_displ))
mpg %>% group_by(class) %>% summarise(mean(displ) , mean(hwy))
tidyverse生态链的更多相关文章
- 运营或生态链没做好,APP质量再高有个鸟用(下)
上篇文章已经阐述了对于一款产品卖不卖作,事实上非常依赖于运营的打造和生态链的建立,这里能够解释为什么很多优秀的游戏产品功底非常好,但開始并不卖作,仅仅有碰到一家肯出力推的渠道游戏才迅速火了起来.这是不 ...
- 浅谈API网关(API Gateway)如何承载API经济生态链
序言 API经济生态链已经在全球范围覆盖, 绝大多数企业都已经走在数字化转型的道路上,API成为企业连接业务的核心载体, 并产生巨大的盈利空间.快速增长的API规模以及调用量,使得企业IT在架构上.模 ...
- TCL、华星光电和中环股份,如何在一条生态链上领跑?
聚众智.汇众力.采众长. "我们决心用五年时间,将TCL科技和TCL实业做到真正的世界500强,将智能终端.半导体显示.半导体光伏三大核心产业力争做到全球领先,将半导体材料等其他产业做到中国 ...
- 【计理05组01号】R 语言基础入门
R 语言基本数据结构 首先让我们先进入 R 环境下: sudo R 赋值 R 中可以用 = 或者 <- 来进行赋值 ,<- 的快捷键是 alt + - . > a <- c(2 ...
- X86上搭建交叉工具链,来给龙芯笔记本编译本地工具链(未完待续)
故事的背景是,我买了一台龙芯2F的笔记本来装B. 为什么说是装B呢?因为不但操作系统是Linux,而且CPU还是龙芯的. 一般人有这么酷的装备吗?简直是装B大圣啊. 这里一定要申明一点,本人不是IT技 ...
- OA发展史:由点到生态
在当今无边界组织的商业背景下,企业与员工关系已经转化为联盟关系,以往通过工作场所.劳动合同等约束的形式已经逐步弱化,管理行为空前复杂,OA正是将一个个散点整合起来的看不见的手.那么,推动OA发展的核心 ...
- Rust这种新型的语言注定火不起来,功能太强大(特性太多),还不如用成熟稳定强大的C/C++,而且生态不行、所以恶性循环
这种新型的语言注定火不起来,功能太强大(特性太多),还不如用成熟稳定强大的C/C++,,而Golang足够简单,入门快,编译快,性能也强悍,解决了服务端开发人员的痛点,,注定被大多数人接受... go ...
- Modelarts与无感识别技术生态总结(浅出版)
[摘要] Modelarts技术及相关产业已成为未来AI与大数据重点发展行业模式之一,为了促进人工智能领域科学技术快速发展,modelarts现状及生态前景成为研究热点.笔者首先总结modelarts ...
- 阿里云吴天议:云原生SDWAN 应用 构建智能化云原生SDWAN生态
2019年11月16日 SDWAN 大会在北京正式召开.阿里云网络资深产品专家吴天议先生继阿里云网络研究员祝顺民先生发表了对云原生SDWAN的进化与展望之后(原文请见https://bit.ly/2K ...
随机推荐
- 移动智能设备功耗优化系列--前言(NVIDIA资深project师分享)
本文是嵌入式企鹅圈原创团队成员.NVIDIA资深开发project师Terry发表的第一篇文章,其将对"移动智能设备功耗优化"这个专题展开一个系列的总结分享. Terry毫无保留地 ...
- 1.求整数最大的连续0的个数 BinaryGap Find longest sequence of zeros in binary representation of an integer.
求整数最大的连续0的个数 A binary gap within a positive integer N is any maximal sequence of consecutive zeros t ...
- 3.3-ISDN
3.3-ISDN 综合业务数字网ISDN(Integrated Services Digital Network): ISDN主要有两种接口类型:分为BRI(2B+D=2×64+16K ...
- [C++] 自己主动关闭右下角弹窗
近期腾讯.迅雷等各种client,都越发喜欢在屏幕的右下角弹框了. 有骨气的人当然能够把这些软件卸载了事,可是这些client在某些情况下却又还是实用的.怎么办呢? 作为码农,自己实现一个自己主动关闭 ...
- js 实现对ajax请求面向对象的封装
AJAX 是一种用于创建高速动态网页的技术.通过在后台与server进行少量数据交换.AJAX 能够使网页实现异步更新.这意味着能够在不又一次载入整个网页的情况下,对网页的某部分进行 ...
- OpenStack二三事(2)
使用devstack在virtualbox上安装openstack还真是比較麻烦,到处都是坑.近期碰到的坑是在tempest上,在执行verify-tempest-config时,代码中import了 ...
- SOA究竟是个啥
SOA(Service-Oriented Architecture),中文全称:面向服务的架构. SOA让把系统分离成不同的服务,使用接口来进行数据交互,终于达到整合系统的目的. 专业的词总是让人懵懵 ...
- 2015南阳CCPC H - Sudoku 数独
H - Sudoku Description Yi Sima was one of the best counselors of Cao Cao. He likes to play a funny g ...
- eclipse高亮选中属性以及更改颜色
1.显示: 1.1.工具栏里有个黄色小笔的图标,点一下就好了 1.2.打开对话框windows->preference,在左上角输入mark Occurrencs 把右边都选 ...
- Android.mk添加第三方jar包(转载)
转自:www.cnblogs.com/hopetribe/archive/2012/04/23/2467060.html LOCAL_PATH:= $(call my-dir)include $(CL ...