我理解的数据结构(一)—— 数组(Array)
我理解的数据结构(一)—— 数组(Array)
首先,我是一个phper,但是毕竟php是一个脚本语言,如果使用脚本语言去理解数据结构具有一定的局限性。因为脚本语言是不需要编译的,如果你的语法写的不错,可能执行起来会要比用一个更好的数据结构来的更快、更高效(在数据量不大的情况下)。而且数据结构是脱离任何一门语言存在的。所以,下面会选用java去更深入的理解数据结构。
注:这里不会去过多的解释java的语法。
一、定义一个数组的两种方式
int[] arr = new int[10];int[] arr = new int[] {10, 20, 30};
二、数组基础
- 数组的容量在数组一开始定义的时候就固定了。
- 数组最大的优点:根据索引快速查询。如:
arr[2]。 - 数组最好应用于“索引有语意”的情况下。
- 但并非所有有语意的索引都适用于数组:比如索引是一个人的身份证号,会开辟过大的空间,不现实。
- 下面会讨论数组“索引没有语意”的情况,基于java数组,二次封装属于我们自己的数组类,更深入的理解数组。
三、创建一个最基本的数组类
学习任何一个数据结构,
CRUD必不可少。下面,让我们来一起一步步完善属于我们自己的数组的增、删、改、查
```
public class Array {
// 数组的实际大小
private int size;
// 数组
private int[] data;
// 构造函数,根据传入的容纳量定义一个int类型的数组
public Array(int capacity) {
data = new int[capacity];
size = 0;
}
// 重载,没有传入容纳量,定义一个长度为10的int类型数组
public Array() {
this(10);
}
// 数组的实际大小
public int getSize() {
return size;
}
// 数组的容纳量
public int getCapacity() {
return data.length;
}
// 数组是否为空
public boolean isEmpty() {
return size == 0;
}
}
<h3>四、增</h3>
//往数组的任意位置插入
public void add(int index, int ele) {
// 数组已满
if (size == data.length) {
throw new IllegalArgumentException("add failed. arr is full");
}
// 插入的索引位不合法
if (index < 0 || index >= size) {
throw new IllegalArgumentException("add failed. index < 0 or index >= size");
}
// 从index向后的所有元素均向后赋值
for (int i = size - 1; i >= index; i--) {
data[i + 1] = data[i];
}
data[index] = ele;
size++;
}
// 第一个位置插入
public void addFirst(int ele) {
add(0, ele);
}
// 最后一个位置插入
public void addLast(int ele) {
add(size, ele);
}
<h3>五、查和改</h3>
// 查询index索引位置的元素
public int get(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("get failed. index is illegal");
}
return data[index];
}
// 查询ele元素的索引,不存在返回-1
public int find(int ele) {
for (int i = 0; i < size; i++) {
if (data[i] == ele) {
return i;
}
}
return -1;
}
// 更新Index的元素
public void set(int index, int ele) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("get failed. index is illegal");
}
data[index] = ele;
}
<h3>六、删</h3>
// 根据索引删除数组中的第一个ele,返回ele
public int remove(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("remove failed. index is illegal");
}
for (int i = index + 1; i < size; i++) {
data[i - 1] = data[i];
}
size--;
return data[index];
}
// 删除第一个元素
public int removeFirst() {
return remove(0);
}
// 删除最后一个
public int removeLast() {
return remove(size - 1);
}
// 删除指定元素
public void removeElement(int ele) {
int index = find(ele);
if (index != -1) {
remove(index);
}
}
<h3>七、包含和重写toString</h3>
Override
public String toString() {
StringBuffer res = new StringBuffer();
res.append(String.format("Array: size = %d, capacity = %d\n", size, data.length));
res.append("[");
for (int i = 0; i < size; i++) {
res.append(data[i]);
if (i != size - 1) {
res.append(", ");
}
}
res.append("]");
return res.toString();
}
// 查询数组中是否包含元素ele
public boolean contain(int ele) {
for (int i = 0; i < size; i++) {
if (data[i] == ele) {
return true;
}
}
return false;
}
<p><strong>注:</strong>通过以上方法我们已经创建了一个<strong>最最最最最</strong>基本的数组类(见下图)。当然,你也可以去添加一些自己需要的方法,例如:<code>removeAll</code>、<code>findAll</code>之类的。<br></p>
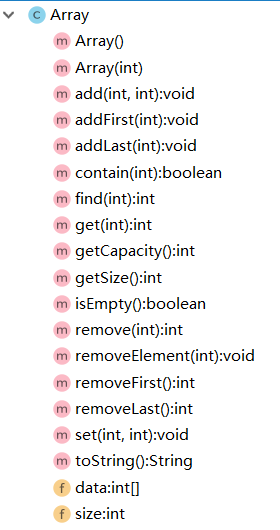
<blockquote>但是,我们现在的数组只支持int类型,太过局限。接下来,我们去给我们的数组升华一哈~</blockquote>
<h3>八、使用泛型让我们的数组支持“任意”数据类型</h3>
<blockquote>首先,为什么我要在<strong>任意</strong>这两个字加上引号,因为java的泛型不支持基本数据类型,只能是类的对象。<br>但是,这并不代表如果我们使用了泛型,就不可以使用基本数据类型了,因为每一个基本数据类型都有一个对应的<strong>包装类</strong>。<br>使用泛型的时候,我们只需要传入对应的包装类即可。</blockquote>
<h4>java的基本数据类型</h4>
<table>
<thead><tr>
<th align="center">基本数据类型</th>
<th align="center">包装类</th>
</tr></thead>
<tbody>
<tr>
<td align="center">boolean</td>
<td align="center">Boolean</td>
</tr>
<tr>
<td align="center">byte</td>
<td align="center">Byte</td>
</tr>
<tr>
<td align="center">char</td>
<td align="center">Char</td>
</tr>
<tr>
<td align="center">short</td>
<td align="center">Short</td>
</tr>
<tr>
<td align="center">int</td>
<td align="center">Int</td>
</tr>
<tr>
<td align="center">long</td>
<td align="center">Long</td>
</tr>
<tr>
<td align="center">float</td>
<td align="center">Float</td>
</tr>
<tr>
<td align="center">double</td>
<td align="center">Double</td>
</tr>
</tbody>
</table>
<h4>所以,我们的代码只需要进行极小的改动即可:</h4>
public class ArrayNew<E> {
// 数组的实际大小
private int size;
// 数组
private E[] data;
// 构造函数,根据传入的容纳量定义一个 E 类型的数组
public ArrayNew(int capacity) {
// 强转
data = (E[]) new Object[capacity];
size = 0;
}
// 重载,没有传入容纳量,定义一个长度为10的int类型数组
public ArrayNew() {
this(10);
}
// 数组的实际大小
public int getSize() {
return size;
}
// 数组的容纳量
public int getCapacity() {
return data.length;
}
// 数组是否为空
public boolean isEmpty() {
return size == 0;
}
// 往数组的任意位置插入
public void add(int index, E ele) {
// 数组已满
if (size == data.length) {
throw new IllegalArgumentException("add failed. arr is full");
}
// 插入的索引位不合法
if (index < 0 || index > size) {
throw new IllegalArgumentException("add failed. index < 0 or index > size");
}
// 从index向后的所有元素均向后赋值
for (int i = size - 1; i >= index; i--) {
data[i + 1] = data[i];
}
data[index] = ele;
size++;
}
// 第一个位置插入
public void addFirst(E ele) {
add(0, ele);
}
// 最后一个位置插入
public void addLast(E ele) {
add(size, ele);
}
// 查询index索引位置的元素
public E get(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("get failed. index is illegal");
}
return data[index];
}
// 查询ele元素的索引,不存在返回-1
public int find(E ele) {
for (int i = 0; i < size; i++) {
if (data[i].equals(ele)) {
return i;
}
}
return -1;
}
// 更新Index的元素
public void set(int index, E ele) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("get failed. index is illegal");
}
data[index] = ele;
}
// 根据索引删除数组中的第一个ele,返回ele
public E remove(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("remove failed. index is illegal");
}
E result = data[index];
for (int i = index + 1; i < size; i++) {
data[i - 1] = (data[i]);
}
// 空间释放,垃圾回收会自动回收
data[--size] = null;
return result;
}
// 删除第一个元素
public E removeFirst() {
return remove(0);
}
// 删除最后一个
public E removeLast() {
return remove(size - 1);
}
// 删除指定元素
public void removeElement(E ele) {
int index = find(ele);
if (index != -1) {
remove(index);
}
}
// 查询数组中是否包含元素ele
public boolean contain(E ele) {
for (int i = 0; i < size; i++) {
if (data[i].equals(ele)) {
return true;
}
}
return false;
}
@Override
public String toString() {
StringBuffer res = new StringBuffer();
res.append(String.format("Array: size = %d, capacity = %d\n", size, data.length));
res.append("[");
for (int i = 0; i < size; i++) {
res.append(data[i]);
if (i != size - 1) {
res.append(", ");
}
}
res.append("]");
return res.toString();
}
}
<p><strong>注:</strong>创建数组时,只需<code>ArrayNew<Student> arr = new ArrayNew<>(20);</code>即可。</p>
<h3>九、动态数组</h3>
<blockquote>
<strong>原理:</strong>其实,动态数组的原理非常简单,如果我们希望我们的数组具有可伸缩性,只需要我们在添加或者删除元素时判断<code>size</code>是否到达临界。然后去创建一个新<code>capacity</code>的数组,然后把旧数组的引用指向新数组即可。<br>所以,我们上述代码的改变极小,只需要改变<code>add</code>、<code>remove</code>即可。然后添加一个<code>resize</code>方法。</blockquote>
// 往数组的任意位置插入
public void add(int index, E ele) {
// 插入的索引位不合法
if (index < 0 || index > size) {
throw new IllegalArgumentException("add failed. index < 0 or index > size");
}
// 如果size == data.length,数组长度已满
if (size == data.length) {
resize(data.length * 2);
}
// 从index向后的所有元素均向后赋值
for (int i = size - 1; i >= index; i--) {
data[i + 1] = data[i];
}
data[index] = ele;
size++;
}
// 根据索引删除数组中的第一个ele,返回ele
public E remove(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("remove failed. index is illegal");
}
E result = data[index];
for (int i = index + 1; i < size; i++) {
data[i - 1] = (data[i]);
}
// 空间释放,垃圾回收会自动回收
data[--size] = null;
// 减小数组长度,不要浪费空间
if (size == data.length / 2 && size != 0) {
resize(size);
}
return result;
}
// 自动伸缩数组
private void resize(int newCapacity) {
E[] newData = (E[])new Object[newCapacity];
for (int i = 0; i < size; i++) {
newData[i] = data[i];
}
data = newData;
}
<h3>十、简单复杂度分析我们封装的数组</h3>
<blockquote>通过上面的分析和代码实现,我们封装了一个自己的数组,并且实现了一些数组<strong>最基本</strong>的功能,包括支持增、删、改、查、支持任意数据类型以及动态数组。那么我们就来分析一下我们自己封装数组的复杂度。</blockquote>
<table>
<thead><tr>
<th align="center">操作</th>
<th align="center">复杂度</th>
</tr></thead>
<tbody>
<tr>
<td align="center">增</td>
<td align="center">O(n)</td>
</tr>
<tr>
<td align="center">删</td>
<td align="center">O(n)</td>
</tr>
<tr>
<td align="center">改</td>
<td align="center">已知索引O(1);未知索引O(n)</td>
</tr>
<tr>
<td align="center">查</td>
<td align="center">已知索引O(1);未知索引O(n)</td>
</tr>
</tbody>
</table>
<p><strong>但是:</strong>在我们的数组中,增和删我们都调用了<code>resize</code>方法,如果<code>size < data.length</code>,其实我们执行<code>addLast</code>复杂度只是<code>O(1)</code>而已(<code>removeLast</code>同理)。所以,我们应该怎么去分析<code>resize</code>方法所带来的复杂度呢?</p>
<h3>十一、均摊复杂度和防止复杂度的震荡</h3>
<h4>(1)均摊复杂度</h4>
<blockquote>让我们拿 <strong>增</strong> 来举例</blockquote>
<table>
<thead><tr>
<th align="center">方法</th>
<th align="center">复杂度</th>
</tr></thead>
<tbody>
<tr>
<td align="center">addLast(ele)</td>
<td align="center">O(1)</td>
</tr>
<tr>
<td align="center">addFirst(ele)</td>
<td align="center">O(n)</td>
</tr>
<tr>
<td align="center">add(index, ele)</td>
<td align="center">O(n/2) = O(n)</td>
</tr>
<tr>
<td align="center">resize(newCapacity)</td>
<td align="center">O(n)</td>
</tr>
</tbody>
</table>
<p>其实,在执行<code>addLast</code>的时候,我们并不是每次都会触发<code>resize</code>方法,更多的时候,复杂度只是<code>O(1)</code>而已。<br><strong>比方说:</strong><br>当前的<code>capacity = 8</code>,并且每一次添加操作都使用<code>addLast</code>,第9次<code>addLast</code>操作,触发<code>resize</code>,总共17次基本操作(<code>resize</code>方法会进行8次操作,<code>addLast</code>方法进行9次操作)。平均,每次<code>addLast</code>操作,进行2次基本操作(17 / 9 ≈ 2)。<br><strong>假设:</strong><br><code>capacity = n</code>, <code>n + 1</code>次<code>addLast</code>,触发<code>resize</code>,总共进行了<code>2n + 1</code>次操作,平均每次<code>addLast</code>操作,进行了2次基本操作。</p>
<p><strong>这样均摊计算,时间复杂度是O(1)!</strong></p>
<h4>(2)防止复杂度的震荡</h4>
<blockquote>让我们来假设这样一种情况:<br>当<code>size == data.length</code>时,我们执行了<code>addLast</code>方法添加一个元素,这个时候我们需要去执行<code>resize</code>方法,此时,<code>addLast</code>的复杂度为<code>O(n)</code>。<br>然后,我去<code>removeLast</code>,此时的<code>removeLast</code>复杂度也是<code>O(n)</code>。<br>再然后,我再去执行<code>addLast</code>。<br>.<br>.<br>.</blockquote>
<p>有没有发现,在这样一种极端情况下,<code>addLast</code>和<code>removeLast</code>的复杂度变成了<code>O(n)</code>,其实,这个就是<strong>复杂度的震荡</strong>。</p>
<ul>
<li>
<p>为什么我们会产生这种震荡?</p>
<ul><li>
<code>add</code>情况下,我们去扩容数组无可厚非。但是<code>remove</code>情况下,我们立刻去缩容数组就有点不合适了。</li></ul>
</li>
<li>
<p>怎么去解决这种情况?</p>
<ul>
<li>因为我们之前采取的措施是<code>Eager</code>
</li>
<li>所以,我们采取一种<code>Lazy</code>的方式:当<code>size == data.length / 2</code>,我们不要立刻缩容,当<code>size == data.length / 4</code>时,我们才去缩容,就可以很好的解决这种震荡。</li>
</ul>
</li>
</ul>
<blockquote>具体代码如下,其实只是对<code>remove</code>进行了极小的改变</blockquote>
public E remove(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("remove failed. index is illegal");
}
E result = data[index];
for (int i = index + 1; i < size; i++) {
data[i - 1] = data[i];
}
// 空间释放,垃圾回收会自动回收
data[--size] = null;
// 减小数组长度,不要浪费空间,防止震荡
if (size == data.length / 4 && data.length / 2 != 0) {
resize(data.length / 2);
}
return result;
}
原文地址:https://segmentfault.com/a/1190000016064569我理解的数据结构(一)—— 数组(Array)的更多相关文章
- 数据结构之数组Array
数组Array 基本操作 Status InitArray(int dimm,...)//若维数dim和随后的各维长度合法,则构造相应的数组A,并返回OK Status DestroyArray() ...
- 算法与数据结构基础 - 数组(Array)
数组基础 数组是最基础的数据结构,特点是O(1)时间读取任意下标元素,经常应用于排序(Sort).双指针(Two Pointers).二分查找(Binary Search).动态规划(DP)等算法.顺 ...
- 表示集合的数据结构:数组(Array),对象(Object),Map和Set
Map和Set是ES6标准新增的数据类型 Map: 是一组键值对的结构,使用一个二维数组来初始化Map,例如: var m = new Map([['xiaohong',100],['xiaolan' ...
- 我理解的数据结构(二)—— 栈(Stack)
我理解的数据结构(二)-- 栈(Stack) 一.栈基础 栈是一种线性结构 相比较数组,栈对应的操作是数组的子集 只能从一端添加元素,也只能从同一端取出元素,这一端称为栈顶 栈是一种后进先出的数据结构 ...
- 我理解的数据结构(三)—— 队列(Queue)
我理解的数据结构(三)-- 队列(Queue) 一.队列 队列是一种线性结构 相比数组,队列对应的操作是数组的子集 只能从一端(队尾)添加元素,只能从另一端(队首)取出元素 队列是一种先进先出的数据结 ...
- Java-杂项:Java数组Array和集合List、Set、Map
ylbtech-Java-杂项:Java数组Array和集合List.Set.Map 1.返回顶部 1. 之前一直分不清楚java中的array,list.同时对set,map,list的用法彻底迷糊 ...
- javascript数组array
注意:1.array的length不是只读的.可以从数组的末尾移出项或者向数组中添加新项.看下面例子: var colors = ["red","yellow" ...
- Java ArrayList和Vector、LinkedList与ArrayList、数组(Array)和列表集合(ArrayList)的区别
ArrayList和Vector的区别ArrayList与Vector主要从二方面来说. 一.同步性: Vector是线程安全的,也就是说是同步的,而ArrayList是线程序不安全的,不是同步 ...
- go 数组(array)、切片(slice)、map、结构体(struct)
一 数组(array) go语言中的数组是固定长度的.使用前必须指定数组长度. go语言中数组是值类型.如果将数组赋值给另一个数组或者方法中参数使用都是复制一份,方法中使用可以使用指针传递地址. 声明 ...
随机推荐
- HDU - 3631 Shortest Path(Floyd最短路)
Shortest Path Time Limit: 1000MS Memory Limit: 32768KB 64bit IO Format: %I64d & %I64u SubmitStat ...
- 【bzoj1207】[HNOI2004]打鼹鼠
看了数据范围,想想这不暴力可以过?? DP #include<algorithm> #include<iostream> #include<cstdlib> ...
- Ruby Range类
创建: 2017/09/30
- bzoj1121[POI2008]激光发射器SZK(结论)
1121: [POI2008]激光发射器SZK Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 916 Solved: 759[Submit][Sta ...
- 记录第一次在egret项目中使用Puremvc
这几天跟着另一个前端在做一个小游戏,使用的是egret引擎和puremvc框架,这对于我来说还是个比较大的突破吧,特此记录下. 因为在此项目中真是的用到了mvc及面向对象编程,值得学习 记录第一次在e ...
- Android布局属性LayoutParams的理解
在一次笔试中搞混LayoutParams的用法,特来总结一番: LayoutParams继承于Android.View.ViewGroup.LayoutParams.LayoutParams相当于一个 ...
- Android 关于android.os.Build介绍
关于Build类的介绍 这个类为一个获取设备一些初始化信息的类,该类的主要信息都是通过一些static的字段获得: public static final String BOARD The name ...
- celery定时执行ansible api返回为空的问题
有两种方法解决这个问题,就是关闭assert:1.在celery 的worker启动窗口设置export PYTHONOPTIMIZE=1或打开celery这个参数-O OPTIMIZATION2.注 ...
- BZOJ 4310 二分+SA+RMQ
思路: 首先求出后缀数组和height数组,这样能得到本质不同的子串数目 这里利用:本质不同的子串=∑(Len−SA[i]−height[i])=∑(Len−SA[i]−height[i])利用SA[ ...
- flask web 表单验证 WTForms
简介 WTForms 是一个flask集成框架,或者说是库,用于处理浏览器表单提交的数据,它在flask-WTF的基础上扩展并添加了一些随手可得的精巧帮助函数,这些函数将会是在flask里使用表单更加 ...