[AI开发]基于DeepStream的视频结构化解决方案
视频结构化的定义
利用深度学习技术实时分析视频中有价值的内容,并输出结构化数据。相比数据库中每条结构化数据记录,视频、图片、音频等属于非结构化数据,计算机程序不能直接识别非结构化数据,因此需要先将这些数据转换成有结构格式,用于后续计算机程序分析。视频结构化最常见的流程为:目标检测、目标分类(属性识别)、目标跟踪、目标行为分析。最后的目标行为分析严格来讲不属于视频结构化的范畴,可以算作前面每个环节结果的应用。由于现实生产过程中,一个完整的应用系统总会存在“目标行为分析”这个过程(否则光得到基础数据不能加以利用),所以本篇文章将其包含进来。
目标检测
对单张图片中感兴趣的目标进行识别、定位,注意两点,一个是检测的对象是静态图片,二是不但需要识别目标的类别,还需要给出目标在原图片中的坐标值,通常以(left, top, width, height)的形式给出。注意目标检测仅仅给出目标大概位置坐标(一个矩形区域),它跟图像分割不同,后者定位更加具体,能够给出图片中单个目标的轮廓边界。
目标分类(属性识别)
通常目标被检测出来之后,会进行二次(多次)推理,识别出目标更加具体的属性,比如小轿车的颜色、车牌子奥迪还是奔驰等等。对于人来讲,可以二次推理出人的性别、年龄、穿着、发型等等外貌属性。这个环节主要对检测出来的目标进行更加具体的属性识别。
目标跟踪
前面两个环节操作的对象是静态单张图片,而视频有时序性,前后两帧中的目标有关联关系。目标跟踪就是为了将视频第N帧中的目标和第N+1帧中的同一目标关联起来,通常做法是给它们赋予同一个ID。经过目标跟踪环节后,理论情况下,一个目标从进入视频检测范围到离开,算法赋予该目标的ID固定不变。但是现实生产过程中,由于各种原因,比如目标被遮挡、目标漏检(第N帧检测到,第N+1帧没检测到)、跟踪算法自身准确性等等原因,系统并不能锁定视频中同一个目标的ID。目标ID不能锁定,会造成目标行为分析不准的问题,后面会提到。
目标行为分析
视频中目标被跟踪到,赋予唯一ID之后,我们可以记录目标在视频检测范内的运动轨迹(二维坐标点集合),通过分析目标轨迹点数据,我们可以做很多应用。比如目标是否跨域指定区域、目标运动方向、目标运动速度、目标是否逗留(逗留时长)、目标是否密集等等。该应用多存在于安防、交通视频分析领域。
目标检测算法
常见基于深度学习神经网络的目标检测算法有3种,SSD、YOLO以及Faster-RCNN,具体请搜索网络,介绍文章非常多了。三者各有优劣,遵循一个原则:速度快的准确性不好,很多目标检测不准,很多小目标检测不到、容易漏检等;准确性好的速度不快,可能达不到实时检测的要求,或者需要更高的硬件条件。鱼和熊掌不可兼得,牺牲速度可以换来准确性。这三种常见目标检测算法,综合性比较好的是YOLO(现在已经是YOLO V3版本),准确性、小目标检测、检测速度上都可以接受。SSD速度快,我在RTX 2080 的GPU上,能够检测32路1080P高清实时流,但是YOLO V3勉强可以跑到16路。Faster-RCNN准确性更好,但是速度太慢,如果你有很好的GPU硬件支持,或者单台服务器要求检测视频路数比较少,可以采用Faster-RCNN。下图第一张是SSD算法效果,第二张是YOLO V3的算法效果,两者模型都是采用同样的数据集训练而成,可以很明显看到,后者比前者效果好很多(忽略图中速度值)。

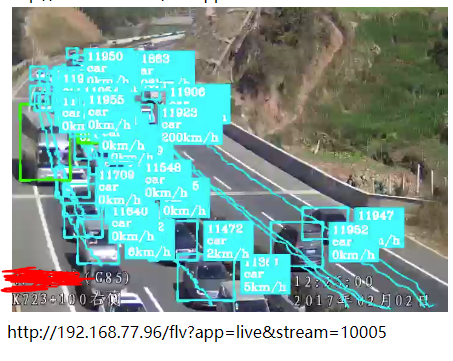
需要注意的是,不管是何种算法,它们的检测效果受数据集质量影响非常大,数据集数量不够、标注质量不高,都会严重影响最终检测结果。做深度学习应用型系统,数据集的重要性非常明显。
视频结构化处理流程框架
前面说到过,视频结构化包含多个环节,各个环节相连而成,形成一个Pipeline的结构。在实际生产过程中,我们还需要有视频流接入的环节,它负责接收视频流数据,由于网络接收到的视频数据是编码过后的格式,我们还需要解码的环节,将原始视频数据解码成一张张RGB格式的图片(这之前可能还需要颜色空间转换,将YUV格式转换成RGB),之后将单帧图片送给推理模型进行推理,返回推理结果。
很明显,视频结构化是一个数据流式的处理过程,如果对GStreamer框架比较熟悉的人可能或想到,GStreamer非常适合做这件事情。这里是GStreamer的官网:https://gstreamer.freedesktop.org/,跟FFmpeg类似,它主要用于音视频多媒体程序开发,但是两个侧重点不同,GStreamer中将多媒体处理流程中的每个环节都封装成单个的插件,每个插件负责不同的任务,比如有接收视频流的、有负责编解码的、有颜色空间转换的等等,这些常用插件都已经有现成非常成熟的,不需要自己开发。插件和插件之间通过某个协议进行连接,最终形成一个完整的Pipeline。目前来看,使用FFmpeg的人明显多余GStreamer。在我们这个应用场景中,GStreamer非常适合我们,Nvidia官方推出的智能视频分析SDK DeepStream也是基于GStreamer开发而成,Nvidia为我们准备好了现成的插件,有负责推理的,有负责目标跟踪的,还有负责图片叠加和显示的。我们在使用DeepStream的同时,也可以使用GStreamer中已有的其他插件,他们可以无缝集成,非常方便。
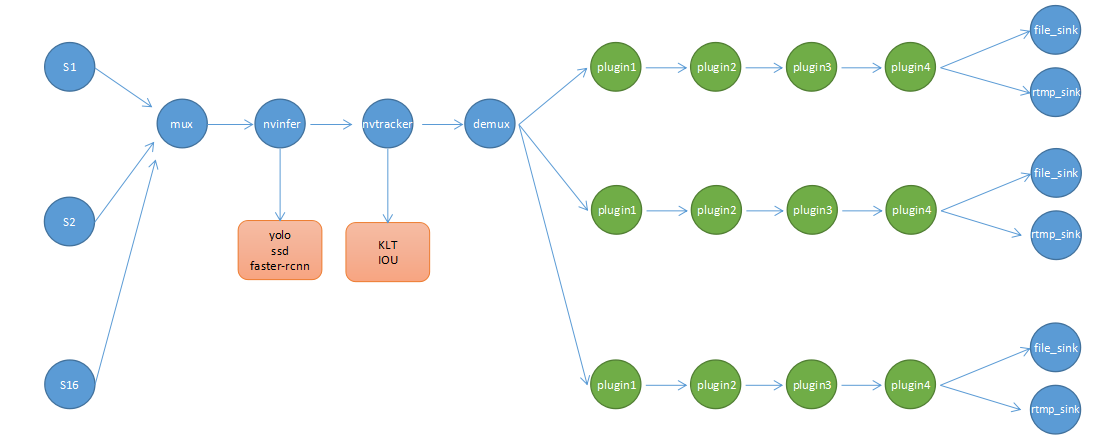
这里必须要提一下,GStreamer是C语言开发的,而我们知道C语言并非面向对象,如果要用到面向对象的特性必须采取其他措施,GStreamer就是使用了GObject那一套东西,GObject又是什么呢?它是一套在C中使用面向对象编程的规范。如果已经非常熟悉主流面向对象语言的人,再去接收GObject这种编程风格,会要疯掉,反人类(我这样觉得)。下图是采用DeepStream SDK开发视频结构化的Pipeline,简单示意,并非真实生产中的结构:
使用DeepStream 做视频结构化应用的好处
如果你用的推理硬件是Nvidia出的,比如Tesla系列显卡、Geforce系列显卡等等,那么使用DeepStream SDK的好处有:
(1)内置推理加速插件nvinfer,注意普通深度学习模型(caffe、tensorflow等)在没有经过tensorRT加速之前,速度是上不来的。而DeepStream内置的nvinfer推理插件不断支持各种目标检测算法(SSD、YOLO、Faster-RCNN)以及各种深度学习框架模型(自由切换),内部还自带tensorRT INT8/FP16加速功能,不需要你做额外操作;
(2)内置目标跟踪插件nvtracker,目前DeepStream 3.0提供两种跟踪算法,一种基于IOU的,这种算法简单,但是快;另外一种KLT算法,准确但是相对来讲慢一些,而且由于这个算法是跑在CPU上,基于KLT的跟踪算法对CPU占用相对大一些;
(3)内置其他比较有用的插件,比如用于视频叠加(目标方框叠加到视频中)的nvosd、硬件加速解码插件nvdec_h264,专门采用GPU加速的解码插件,还有其他颜色转换的插件。
(4)提供跟视频处理有关的各种元数据类型以及API,方便你扩展自己的元数据类型,元数据在GStreamer中是一个很重要的概念。
使用DeepStream SDK的前提是要先掌握GStreamer的基本用法,否则就是抓瞎,前者其实就是后者的一堆插件集合,方便供你构建视频推理Pipeline。当然,你还需要一些CUDA编程的基础知识。
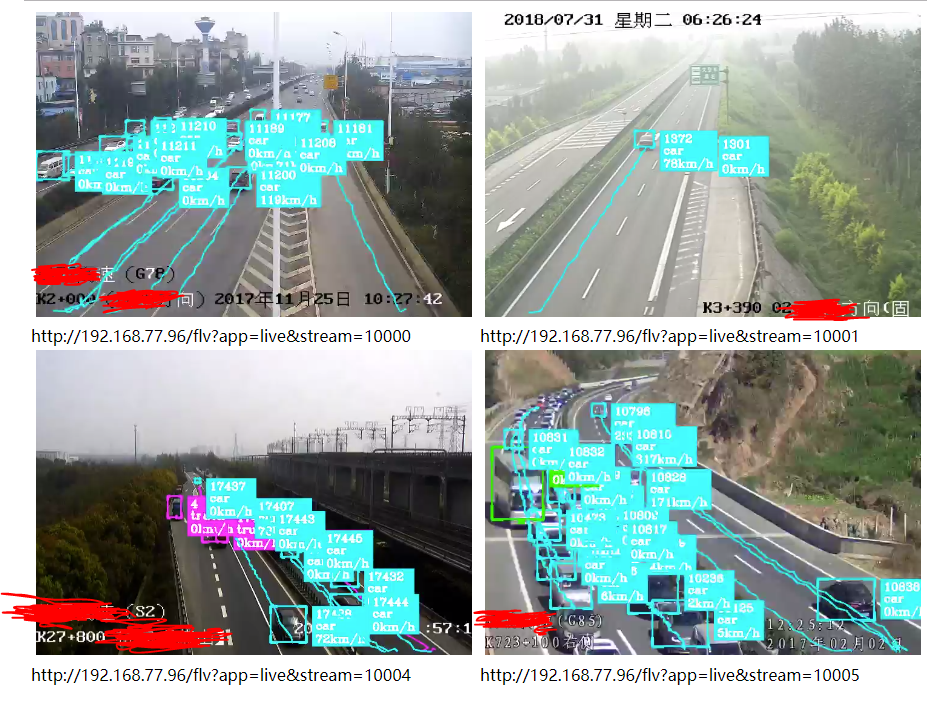
下面提供一个基于YOLO V3 16路1080P高清视频实时目标检测、跟踪、叠加、目标行为判断、结构化数据上报 应用系统截图(截取其中4路图像),由于某些原因,不再做过多的技术细节介绍了。

[AI开发]基于DeepStream的视频结构化解决方案的更多相关文章
- [AI开发]零代码分析视频结构化类应用结构设计
视频结构化类应用涉及到的技术栈比较多,而且每种技术入门门槛都较高,比如视频接入存储.编解码.深度学习推理.rtmp流媒体等等.每个环节的水都非常深,单独拿出来可以写好几篇文章,如果没有个几年经验基本很 ...
- [AI开发]视频结构化类应用的局限性
算法不是通用的,基于深度学习的应用系统不但做不到通用,即使对于同一类业务场景,还需要为每个场景做定制.特殊处理,这样才能有可能到达实用标准.这种局限性在计算机视觉领域的应用中表现得尤其突出,本文介绍基 ...
- 视频结构化 AI 推理流程
「视频结构化」是一种 AI 落地的工程化实现,目的是把 AI 模型推理流程能够一般化.它输入视频,输出结构化数据,将结果给到业务系统去形成某些行业的解决方案. 换个角度,如果你想用摄像头来实现某些智能 ...
- VP视频结构化框架
完成多路视频并行接入.解码.多级推理.结构化数据分析.上报.编码推流等过程,插件式/pipe式编程风格,功能上类似英伟达的deepstream和华为的mxvision,但底层核心不依赖复杂难懂的gst ...
- VideoPipe可视化视频结构化框架开源了!
完成多路视频并行接入.解码.多级推理.结构化数据分析.上报.编码推流等过程,插件式/pipe式编程风格,功能上类似英伟达的deepstream和华为的mxvision,但底层核心不依赖复杂难懂的gst ...
- DeepLearning.ai学习笔记(三)结构化机器学习项目--week2机器学习策略(2)
一.进行误差分析 很多时候我们发现训练出来的模型有误差后,就会一股脑的想着法子去减少误差.想法固然好,但是有点headlong~ 这节视频中吴大大介绍了一个比较科学的方法,具体的看下面的例子 还是以猫 ...
- [AI开发]基于深度学习的视频多目标跟踪实现
据我目前了解掌握,多目标跟踪大概有两种方式: Option1 基于初始化帧的跟踪,在视频第一帧中选择你的目标,之后交给跟踪算法去实现目标的跟踪.这种方式基本上只能跟踪你第一帧选中的目标,如果后续帧中出 ...
- DeepLearning.ai学习笔记(三)结构化机器学习项目--week1 机器学习策略
一.为什么是ML策略 如上图示,假如我们在构建一个喵咪分类器,数据集就是上面几个图,训练之后准确率达到90%.虽然看起来挺高的,但是这显然并不具一般性,因为数据集太少了.那么此时可以想到的ML策略有哪 ...
- 基于oracle的sql(结构化查询语言)指令
创建表空间 create tablespace 表空间名 datafile '存储路径(c:\a\a.dbf)' size 200m autoextend on next 10m maxsize un ...
随机推荐
- Folding UVA - 1630
题目 ans[i][j]表示由原串第i个字符到第j个字符组成的子串的最短折叠长度如果从i到j本身可以折叠,长度就是本身长度或折叠后的长度的最小值***此处参考:http://blog.csdn.net ...
- Cake slicing UVA - 1629
UVA - 1629 ans[t][b][l][r]表示t到b行,l到r列那一块蛋糕切好的最小值d[t][b][l][r]表示t到b行,l到r列区域的樱桃数,需要预处理 #include<cst ...
- LIS 2015百度之星初赛2 HDOJ 5256 序列变换
题目传送门 题意:中文题面 分析:LIS(非严格):首先我想到了LIS,然而总觉得有点不对:每个数先减去它的下标,防止下面的情况发生:(转载)加入序列是1,2,2,2,3,这样求上升子序列是3,也就是 ...
- PT2264解码心得
PT2264解码心得 最近闲暇时间在琢磨无线RF解码程序,正好在数码之家论坛中翻出大佬的解码程序(http://bbs.mydigit.cn/read.php?tid=245739),于是乎,慢慢学习 ...
- node入门(三)——gulp运用实例
在上一篇<node入门(二)——gulpfile.js初探>中,我们知道了(看懂入门二及其参考资料)怎么运用gulp来更高效的开发,现在来示范一下. 在package.json里面配置好d ...
- abp zero mysql版正式发布
AbpZero-MySql aspnet-zero-1.12.0的mysql版本来啦.跟mssql版一样的功能,一样的代码. 获取源码
- T4308 数据结构判断
https://www.luogu.org/record/show?rid=2143639 题目描述 在世界的东边,有三瓶雪碧. ——laekov 黎大爷为了虐 zhx,给 zhx 出了这样一道题.黎 ...
- ios 微信环境 axios请求 status 0
做了一个支付页面,调用post请求但是请求status 0,出现这个的原因居然是https的网页请求http的数据. 但是这个再ios里面不会报错,安卓正常. 记录一下客户端的这个特征!
- vmware桥接模式下主机有多个网卡导致虚拟机网络不通
桥接模式下,vmware会绑定一个物理网卡,因此有多个物理网卡时就要注意当前绑定的物理网卡.打开如下vmware菜单 可以看到VMnet0是桥接模式用的,然后他可以选择绑定一个物理网卡,注意要正确选择 ...
- Failure to transfer org.apache.maven.plugins:maven-compiler-plugin:jar:2.5.1
Mac上写了一段基于Maven的java代码. 上传Git后,在windows上pull下来,eclipse里面各种错误. ArtifactTransferException:Failure to t ...