【paddle学习】词向量
http://spaces.ac.cn/archives/4122/ 关于词向量讲的很好

那么,字向量、词向量这些,真的没有任何创新了吗?有的,从运算上来看,基本上就是通过研究发现,one hot型的矩阵相乘,就像是相当于查表,于是它直接用查表作为操作(获取词向量),而不写成矩阵再运算,这大大降低了运算量。再次强调,降低了运算量不是因为词向量的出现,而是因为把one hot型的矩阵运算简化为了查表操作。这是运算层面的。思想层面的,就是它得到了这个全连接层的参数之后,直接用这个全连接层的参数作为特征,或者说,用这个全连接层的参数作为字、词的表示,从而得到了字、词向量,最后还发现了一些有趣的性质,比如向量的夹角余弦能够在某种程度上表示字、词的相似度。
如果把字向量当做全连接层的参数(这位读者,我得纠正,不是“当做”,它本来就是),那么这个参数你还没告诉我怎么得到呢!答案是:我也不知道怎么得来呀。神经网络的参数不是取决你的任务吗?你的任务应该问你自己呀,怎么问我来了?你说Word2Vec是无监督的?那我再来澄清一下。
这样看,问题就比较简单了,我也没必要一定要用语言模型来训练向量吧?对呀,你可以用其他任务,比如文本情感分类任务来有监督训练。因为都已经说了,就是一个全连接层而已,后面接什么,当然自己决定。当然,由于标签数据一般不会很多,因此这样容易过拟合,因此一般先用大规模语料无监督训练字、词向量,降低过拟合风险。注意,降低过拟合风险的原因是可以使用无标签语料预训练词向量出来(无标签语料可以很大,语料足够大就不会有过拟合风险),跟词向量无关,词向量就是一层待训练参数,有什么本事降低过拟合风险?
word2Vec数学原理:
给定n个权值作为n个叶子节点,构造一颗二叉树,若它的带权路径长度达到最小,则称这样的二叉树为最优二叉树,也称为Huffman树
Huffman树的构造:

word2Vec用到Huffman编码,它把训练语料中的词当成叶子节点,其在语料中出现的次数当作权值,通过构造相应的Huffman树来对每一个词进行Huffman编码。在word2vec源码中将权值较大的孩子节点编码为1,较小的孩子节点编码为0
n-gram模型:

 n-gram模型认为一个词出现的概率只与它前面的n-1个词相关,在语料中统计各个词串出现的次数以及平滑处理,存储计算好的概率值,当需要计算一个句子的概率时,只需要找到相关的概率参数,连乘即可
n-gram模型认为一个词出现的概率只与它前面的n-1个词相关,在语料中统计各个词串出现的次数以及平滑处理,存储计算好的概率值,当需要计算一个句子的概率时,只需要找到相关的概率参数,连乘即可


 与n-gram相比,语言模型不需要实现计算并保存所有的概率值,而是通过直接计算来获取,且通过选取合适的模型可使得参数的个数远小于n-gram中模型参数的个数(语言模型和n-gram都是通过上下文预测当前词的概率)
与n-gram相比,语言模型不需要实现计算并保存所有的概率值,而是通过直接计算来获取,且通过选取合适的模型可使得参数的个数远小于n-gram中模型参数的个数(语言模型和n-gram都是通过上下文预测当前词的概率)
神经概率语言模型

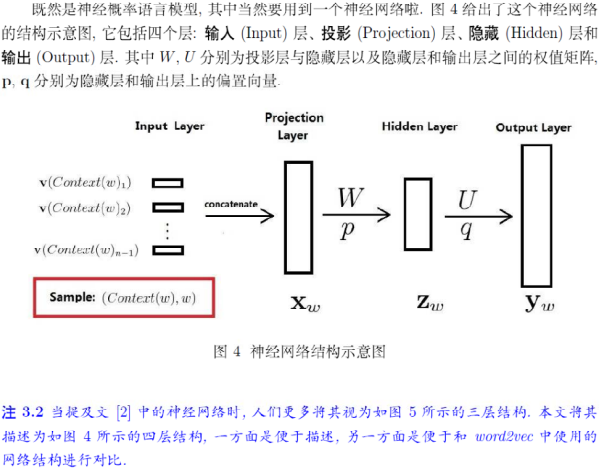


投影层向量:将输入层的n-1个词向量按顺序首尾相接地拼起来形成。隐藏层的激活函数是双曲正切函数。对隐藏层的输出做softmax归一化,即得概率。训练神经概率语言模型时,词向量只是一个副产品。投影层向量$X_w$, 作为隐层的输入,隐层的输出为$Z_w = tanh(WX_w + p)$, 在输出层得到$y_w = UZ_w + q$, 对$y_w$由softmax输出概率。神经概率语言模型的大部分计算集中在隐藏层和输出层的矩阵向量运算,以及输出层上的softmax归一化运算。优化主要是针对这一部分进行的。






CBOW模型
CBOW模型通过一个词的上下文(各N个词)预测当前词,结构:输入层,投影层,输出层。输出层对应一颗Huffman树,叶子节点为语料中出现过的词,各词在语料中出现的次数作为权值。
目标函数
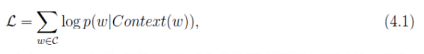
网络结构


神经概率语言模型与CBOW模型的区别:1、从输入层到投影层的操作,前者是通过拼接,后者通过累加求和; 2、前者有隐藏层,后者无隐藏层; 3、前者输出层是线性结构,后者是树形结构。

Hierarchical softmax思想
CBOW目标函数推导过程:对于词典中的任意词,Huffman树中存在一条从根节点到词对应叶节点的路径,路径上每个分支为一次二分类,每一次分类产生一个概率,这些概率连乘起来,即得到目标函数(关于投影向量$X_w$和所有sigmoid函数的未知参数的函数),$p(w|Context(w)) = \prod_{j = 2}^{l^w}p(d_j^w|X_w, \theta^w_{j - 1})$ .推导出来的梯度是目标函数关于投影层上向量(输入上下文中各词向量的和)的梯度,直接利用该梯度来迭代求解输入的各词向量。

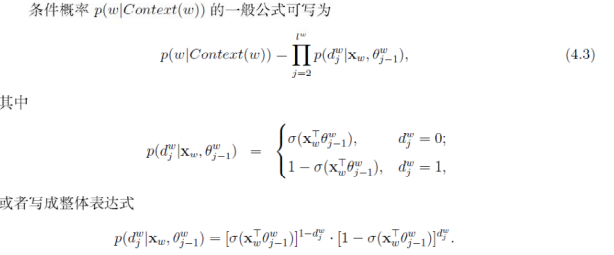



skip-gram模型
Skip-gram的方法中,用一个词预测其上下文。
目标函数
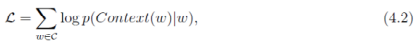
网络结构:输入层只含当前样本的中心词的词向量,所以投影是恒等投影,没有存在的必要,其余和CBOW模型相同




若干源码细节



由于某些高频词提供的有用信息很少,给定一个词频阈值,词w将以某个概率被舍弃


对于一个给定的行,设它包含T个词,则可以得到T个训练样本,因为每个词都对应一个样本,CBOW投影时,词向量直接相加求和,如果是首尾相连,则可能需要补充填充向量,因为一行中首、尾的词,可能其前后的词数不足

逻辑回归中的参数向量是零初始化,词典中每个词的词向量是随机初始化

结合Word2vec数学原理一起看 http://kexue.fm/archives/4299/
http://kexue.fm/usr/uploads/2017/04/2833204610.pdf
https://www.zhihu.com/question/44832436
基于Word2vec的语义分析:
https://zhuanlan.zhihu.com/p/21457407
如何吹比:
https://www.nowcoder.com/discuss/36851?type=0&order=0&pos=13&page=1
作者:haolexiao
链接:https://www.nowcoder.com/discuss/36851?type=0&order=0&pos=13&page=1
来源:牛客网
Hierarchical Softmax的缺点:如果我们的训练样本里的中心词w是一个很生僻的词,那么该词对应的叶子节点深度很大,模型比较复杂。
负采样:比如我们有一个训练样本,中心词是 w,它周围上下文共有
w,它周围上下文共有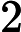
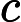 2c个词,记为
2c个词,记为
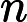
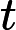

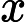
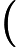
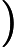 context(w)。由于这个中心词w,的确和context(w)相关存在,因此它是一个真实的正例。通过Negative Sampling采样,我们得到neg个和w不同的中心词
context(w)。由于这个中心词w,的确和context(w)相关存在,因此它是一个真实的正例。通过Negative Sampling采样,我们得到neg个和w不同的中心词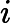

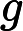 wi,i=1,2,..neg,这样context(w)和$w_i$就组成了neg个并不真实存在的负例。利用这一个正例和neg个负例,我们进行二元逻辑回归,得到负采样对应每个词$w_i$对应的模型参数$\theta_{i}$,和每个词的词向量。
wi,i=1,2,..neg,这样context(w)和$w_i$就组成了neg个并不真实存在的负例。利用这一个正例和neg个负例,我们进行二元逻辑回归,得到负采样对应每个词$w_i$对应的模型参数$\theta_{i}$,和每个词的词向量。
问题:1)如何通过一个正例和neg个负例进行二元逻辑回归呢? 2)如何进行负采样呢?
(context(w),w_i) i=1,2,..neg$ 。为了统一描述,我们将正例定义为 w0。
w0。 在逻辑回归中,我们的正例应该期望满足:
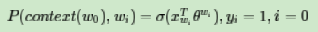 左式x的下标应该是i
左式x的下标应该是i
我们的负例期望满足:
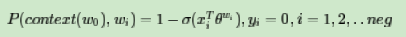
我们期望可以最大化下式:
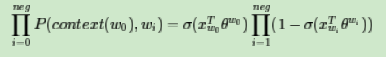
此时模型的似然函数为:
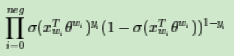 左式上标为$y_i$和$1-y_i$
左式上标为$y_i$和$1-y_i$
对应的对数似然函数为:

负采样方法:
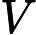 V,那么我们就将一段长度为1的线段分成V份,每份对应词汇表中的一个词。当然每个词对应的线段长度是不一样的,高频词对应的线段长,低频词对应的线段短。每个词w的线段长度由下式决定:
V,那么我们就将一段长度为1的线段分成V份,每份对应词汇表中的一个词。当然每个词对应的线段长度是不一样的,高频词对应的线段长,低频词对应的线段短。每个词w的线段长度由下式决定: 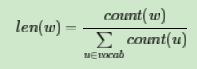
在word2vec中,分子和分母都取了3/4次幂如下:
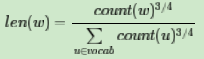
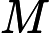 M等份,这里
M等份,这里 M>>V,这样可以保证每个词对应的线段都会划分成对应的小块。而M份中的每一份都会落在某一个词对应的线段上。在采样的时候,我们只需要从M个位置中采样出neg个位置就行,此时采样到的每一个位置对应到的线段所属的词就是我们的负例词。 M取值默认为$
M>>V,这样可以保证每个词对应的线段都会划分成对应的小块。而M份中的每一份都会落在某一个词对应的线段上。在采样的时候,我们只需要从M个位置中采样出neg个位置就行,此时采样到的每一个位置对应到的线段所属的词就是我们的负例词。 M取值默认为$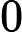
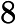 10^8$。
10^8$。 如何对sentence和phrase生成向量表示? 最直观的思路,对于phrase和sentence,我们将组成它们的所有word对应的词向量加起来,作为短语向量,句向量。在参考文献[34]中,验证了将词向量加起来的确是一个有效的方法,但事实上还有更好的做法。
Le和Mikolov在文章《Distributed Representations of Sentences and Documents》[20]里介绍了sentence vector,这里我们也做下简要分析。
先看c-bow方法,相比于word2vec的c-bow模型,区别点有:
- 训练过程中新增了paragraph id,即训练语料中每个句子都有一个唯一的id。paragraph id和普通的word一样,也是先映射成一个向量,即paragraph vector。paragraph vector与word vector的维数虽一样,但是来自于两个不同的向量空间。在之后的计算里,paragraph vector和word vector累加或者连接起来,作为输出层softmax的输入。在一个句子或者文档的训练过程中,paragraph id保持不变,共享着同一个paragraph vector,相当于每次在预测单词的概率时,都利用了整个句子的语义。
- 在预测阶段,给待预测的句子新分配一个paragraph id,词向量和输出层softmax的参数保持训练阶段得到的参数不变,重新利用梯度下降训练待预测的句子。待收敛后,即得到待预测句子的paragraph vector。
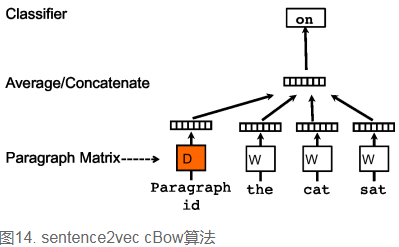
sentence2vec相比于word2vec的skip-gram模型,区别点为:在sentence2vec里,输入都是paragraph vector,输出是该paragraph中随机抽样的词。
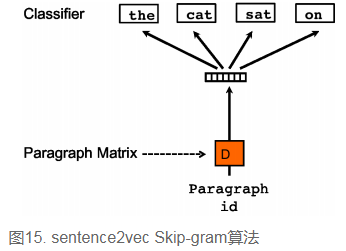
词向量的改进
- 学习词向量的方法主要分为:Global matrix factorization和Shallow Window-Based。Global matrix factorization方法主要利用了全局词共现,例如LSA;Shallow Window-Based方法则主要基于local context window,即局部词共现,word2vec是其中的代表;Jeffrey Pennington在word2vec之后提出了GloVe,它声称结合了上述两种方法,提升了词向量的学习效果。它与word2vec的更多对比请点击GloVe vs word2vec,GloVe & word2vec评测。
- 目前通过词向量可以充分发掘出“一义多词”的情况,譬如“快递”与“速递”;但对于“一词多义”,束手无策,譬如“苹果”(既可以表示苹果手机、电脑,又可以表示水果),此时我们需要用多个词向量来表示多义词。
http://www.flickering.cn/ads/2015/02/%E8%AF%AD%E4%B9%89%E5%88%86%E6%9E%90%E7%9A%84%E4%B8%80%E4%BA%9B%E6%96%B9%E6%B3%95%E4%BA%8C/
【paddle学习】词向量的更多相关文章
- word2vec生成词向量原理
假设每个词对应一个词向量,假设: 1)两个词的相似度正比于对应词向量的乘积.即:$sim(v_1,v_2)=v_1\cdot v_2$.即点乘原则: 2)多个词$v_1\sim v_n$组成的一个上下 ...
- 词向量(one-hot/SVD/NNLM/Word2Vec/GloVe)
目录 词向量简介 1. 基于one-hot编码的词向量方法 2. 统计语言模型 3. 从分布式表征到SVD分解 3.1 分布式表征(Distribution) 3.2 奇异值分解(SVD) 3.3 基 ...
- word2vec预训练词向量
NLP中的Word2Vec讲解 word2vec是Google开源的一款用于词向量计算 的工具,可以很好的度量词与词之间的相似性: word2vec建模是指用CBoW模型或Skip-gram模型来计算 ...
- 第一节——词向量与ELmo(转)
最近在家听贪心学院的NLP直播课.都是比较基础的内容.放到博客上作为NLP 课程的简单的梳理. 本节课程主要讲解的是词向量和Elmo.核心是Elmo,词向量是基础知识点. Elmo 是2018年提出的 ...
- 斯坦福NLP课程 | 第1讲 - NLP介绍与词向量初步
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- NLP教程(2) | GloVe及词向量的训练与评估
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- 词向量word2vec(图学习参考资料)
介绍词向量word2evc概念,及CBOW和Skip-gram的算法实现. 项目链接: https://aistudio.baidu.com/aistudio/projectdetail/500940 ...
- 学习笔记TF018:词向量、维基百科语料库训练词向量模型
词向量嵌入需要高效率处理大规模文本语料库.word2vec.简单方式,词送入独热编码(one-hot encoding)学习系统,长度为词汇表长度的向量,词语对应位置元素为1,其余元素为0.向量维数很 ...
- NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,不过这个项目其实是有两部分组成的,一部分是这篇文章介绍的 fastText 文本分类(paper: ...
随机推荐
- redis 内存管理与数据淘汰机制(转载)
原文地址:http://www.jianshu.com/p/2f14bc570563?from=jiantop.com 最大内存设置 默认情况下,在32位OS中,Redis最大使用3GB的内存,在64 ...
- mysql启动错误排查-无法申请足够内存
一般情况下mysql的启动错误还是很容易排查的,但是今天我们就来说一下不一般的情况.拿到一台服务器,安装完mysql后进行启动,启动错误如下: 有同学会说,哥们儿你是不是buffer pool设置太大 ...
- python算法-快速排序
快速排序: 学习快速排序,要先复习下递归: 递归的2个条件: 1. 函数自己调用自己 2.有一个退出的条件 练习:基于递归下一个函数,计算n!并且求出当n等于10的值. n!=n * n-1*…..* ...
- Java日志实战及解析
Java日志实战及解析 日志是程序员必须掌握的基础技能之一,如果您写的软件没有日志,可以说你没有成为一个真正意义上的程序员. 为什么要记日志? • 监控代码 • 变量变化情况, ...
- tomcat的管理(manager)报错403
管理tomcat的时候遇到了以下问题: 1.刚开始需要用户名密码,不知道用户名和密码是什么,但是输入什么都不正确. 解决办法: 自己在tomcat-users.xml中按格式添加用户 conf文件夹里 ...
- BZOJ2780 [Spoj]8093 Sevenk Love Oimaster 【广义后缀自动机】
题目 Oimaster and sevenk love each other. But recently,sevenk heard that a girl named ChuYuXun was dat ...
- 【2018.12.10】NOI模拟赛3
题目 WZJ题解 大概就是全场就我写不过 $FFT$ 系列吧……自闭 T1 奶一口,下次再写不出这种 $NTT$ 裸题题目我就艹了自己 -_-||| 而且这跟我口胡的自创模拟题 $set1$ 的 $T ...
- 【2018.10.20】CXM笔记(思维)
1. 给你个环状字符串,问从哪个地方拆开能使它的字典序最小. 先预处理任意子串的哈希值. 然后枚举拆点,将它与当前最优的拆点比较谁更优(就是从哪拆的字典序更小),具体方法是二分+哈希找出两串最长的相同 ...
- 高通android7.0刷机工具使用介绍
刷机工具安装 1. 安装QPST.WIN.2.7 Installer-00448.3 2. 安装python2.7,并配置其环境变量 刷机方法 1.将编译后的刷机文件拷贝到如下目录:SC20_CE_p ...
- 【POJ3415】Common Substrings(后缀数组,单调栈)
题意: n<=1e5 思路: 我的做法和题解有些不同 题解是维护A的单调栈算B的贡献,反过来再做一次 我是去掉起始位置不同这个限制条件先算总方案数,再把两个串内部不合法的方案数减去 式子展开之后 ...