Linux Hadoop2.7.3 安装(单机模式) 二
Linux Hadoop2.7.3 安装(单机模式) 一
Linux Hadoop2.7.3 安装(单机模式) 二
YARN是Hadoop 2.0中的资源管理系统,它的基本设计思想是将MRv1中的JobTracker拆分成了两个独立的服务:一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。
其中ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理。
创建一个words.txt 文件并上传
vi words.txt Hello World
Hello Tom
Hello Jack
Hello Hadoop
Bye hadoop
将words.txt上传到hdfs的根目录
/home/xupanpan/hadoop/hadoop/bin/hadoop fs -put /home/xupanpan/hadoop/word.txt /

1、配置etc/hadoop/mapred-site.xml:
mv /home/xupanpan/hadoop/hadoop/etc/hadoop/mapred-site.xml.template /home/xupanpan/hadoop/hadoop/etc/hadoop/mapred-site.xml
vim /home/xupanpan/hadoop/hadoop/etc/hadoop/mapred-site.xml
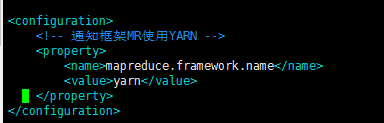
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2、配置etc/hadoop/yarn-site.xml:
vim /home/xupanpan/hadoop/hadoop/etc/hadoop/yarn-site.xml

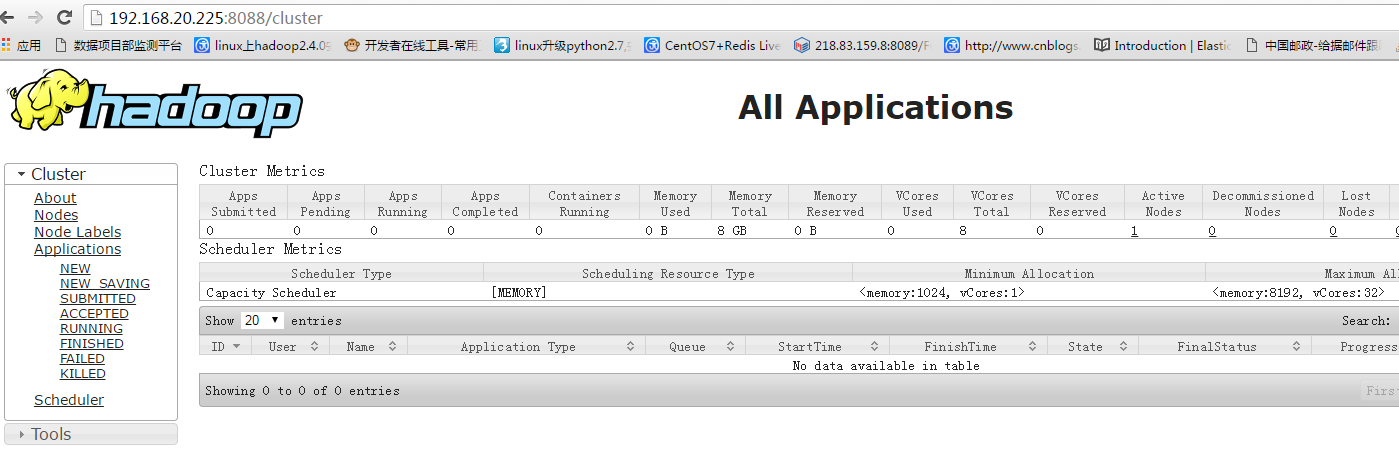
3、YARN的启动
/home/xupanpan/hadoop/hadoop/sbin/start-yarn.sh

http://192.168.20.225:8088/cluster
3、YARN的停止
sbin/stop-yarn.sh
现在我们的hdfs和yarn都运行成功了,我们开始运行一个WordCount的MP程序来测试我们的单机模式集群是否可以正常工作。
运行一个简单的MP程序
我们的MapperReduce将会跑在YARN上,结果将存在HDFS上:
用hadoop执行一个叫 hadoop-mapreduce-examples.jar 的 wordcount 方法,其中输入参数为 hdfs上根目录的words.txt 文件,而输出路径为 hdfs跟目录下的out目录,运行过程如下:
/home/xupanpan/hadoop/hadoop/bin/hadoop jar /home/xupanpan/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar wordcount hdfs://127.0.0.1:9000/word.txt hdfs://127.0.0.1:9000/out
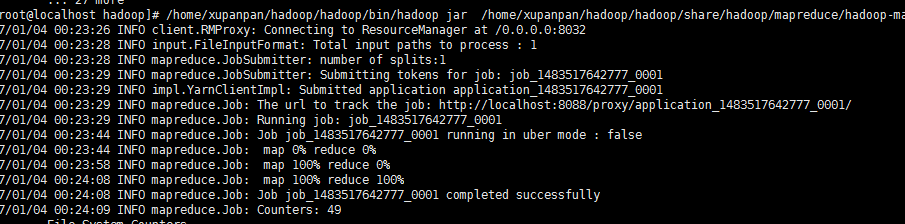


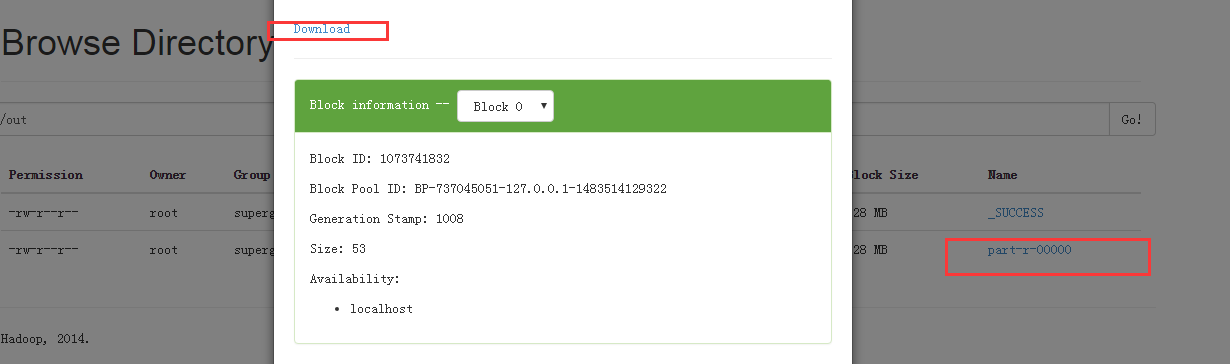

说明我们已经计算出了,单词出现的次数。
至此,我们Hadoop的单机模式搭建成功。
参考 http://blog.csdn.net/uq_jin/article/details/51451995
Linux Hadoop2.7.3 安装(单机模式) 二的更多相关文章
- Linux Hadoop2.7.3 安装(单机模式) 一
Linux Hadoop2.7.3 安装(单机模式) 一 Linux Hadoop2.7.3 安装(单机模式) 二 java环境安装 http://www.cnblogs.com/zeze/p/590 ...
- Ubuntu14.04下安装Hadoop2.5.1 (单机模式)
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-standalone-mode.html,转载请注明源地址. 欢迎关注我的个人博客:www.wuyudo ...
- Ubuntu 14.04下安装Hadoop2.4.0 (单机模式)
转自 http://www.linuxidc.com/Linux/2015-01/112370.htm 一.在Ubuntu下创建Hadoop组和hadoop用户 增加hadoop用户组,同时在该组里增 ...
- 一、Ubuntu14.04下安装Hadoop2.4.0 (单机模式)
一.在Ubuntu下创建hadoop组和hadoop用户 增加hadoop用户组,同时在该组里增加hadoop用户,后续在涉及到hadoop操作时,我们使用该用户. 1.创建hadoop用户组 2.创 ...
- Ubuntu14.04下安装Hadoop2.4.0 (单机模式)
一.在Ubuntu下创建hadoop组和hadoop用户 增加hadoop用户组,同时在该组里增加hadoop用户,后续在涉及到hadoop操作时,我们使用该用户. 1.创建hadoop用户组 2.创 ...
- Hadoop2.6.0安装—单机/伪分布
目录 环境准备 创建hadoop用户 更新apt 配置SSH免密登陆 安装配置Java环境 安装Hadoop Hadoop单机/伪分布配置 单机Hadoop 伪分布Hadoop 启动Hadoop 停止 ...
- linux centos7最小化安装桥接模式网络设置、xshell、xftf
一.网络连接设置1.桥接模式 使用电脑真实网卡,可以和自己的电脑连接,也可以和外部网络连接2.NAT模式 使用wmware network adapter vmnet8虚拟网卡,可以和自己的电脑连接, ...
- hadoop2.6.4 搭建单机模式
注(要先安装jdk,最好jdk版本>=1.7) 安装jdk http://www.cnblogs.com/zhangXingSheng/p/6228432.html 给普通用户添加su ...
- Linux中Postfix邮件安装配置(二)
本套邮件系统的搭建,从如何发邮件到收邮件到认证到虚拟用户虚拟域以及反病毒和反垃圾邮件等都有详细的介绍.在搭建过程中必须的参数解释以及原理都有告诉,这样才能更好地理解邮件系统. 卸载自带postfix ...
随机推荐
- linux 查找文件和搜索文件
按照文件名搜索 find . -name 'file name' grep -lr 'content' filepath
- iOS how to stop a scrolling scrollView
- (void)killScroll { CGPoint offset = scrollView.contentOffset; offset.y -= 1.0; [scrollView setCont ...
- IO总结
在电脑是新建一个文件夹 File file = new File("F:\\imgs"); File file = new File("F:/imgs"); 输 ...
- postman测试接口之POST提交本地文件数据
前言: 接口测试时,有时需要读取文件的数据:那么postman怎么添加一个文件作为参数呢? 实例: 接口地址: http://121.xxx.xxx.xxx:9003/marketAccount/ba ...
- weex scroller
今天学习了一下weex的 scroller.就简单地对其整理一下自己的学习笔记. <scroller>这个标签只能出现在列(column)上面, 只有当它自己的内容大于类似与PC父级的高度 ...
- Smack4.1注册新用户
更新了smack4.1后,发现之前的注册表单不能使用了,很多属性都不能使用. 发现4.1把帐号的出来都集中到 org.jivesoftware.smackx.iqregister.AccountMan ...
- XCode设置自己windows习惯的快捷键(比如Home、End键)
Xcode的preference(command+,)中可以设置Key Bindings.绑定自己习惯的快捷键.实测系统快捷键设置同样名字也可以生效,但操作比较繁琐这里就不介绍了. 1.打开Xcode ...
- Devexpress
1.隐藏最上面的GroupPanel gridView1.OptionsView.ShowGroupPanel=false; 2.得到当前选定记录某字段的值 sValue=Table.Rows[gri ...
- CentOS 7 防止端口自动关闭
tl;dr firewall-cmd --permanent --zone=public --add-port=2888/tcp firewall-cmd --reload #重新载入服务 永久配置f ...
- js数组操作总结
1.数组的检测 ECMAScript3 if(value instanceof Array){ //执行操作 } 假定单一全局环境,如果网页存在多个框架,多个window,Array具有不 ...