论文阅读:Deformable ConvNets v2
论文地址:http://arxiv.org/abs/1811.11168
作者:pprp
时间:2019年5月11日
0. 摘要
DCNv1引入了可变形卷积,能更好的适应目标的几何变换。但是v1可视化结果显示其感受野对应位置超出了目标范围,导致特征不受图像内容影响(理想情况是所有的对应位置分布在目标范围以内)。
为了解决该问题:提出v2, 主要有
- 扩展可变形卷积,增强建模能力
- 提出了特征模拟方案指导网络培训:feature mimicking scheme
结果:性能显著提升,目标检测和分割效果领先。
1. 简介
Geometric variations due to scale, pose, viewpoint and part deformation present a major challenge in object recognition and detection.
目标检测一个主要挑战:尺度,姿势,视角和部件变形引起的几何变化
v1 引入两个模块:
- Deformable Convolution : 可变形卷积
- 通过相对普通卷积基础上添加的偏移解决
- Deformable RoI pooling : 可变形 RoI pooling
- 在RoI pooling 中的bin学习偏移
为了理解可变形卷积,进行了可视化操作:
samples for an activation unit tend to cluster around the object on which it lies.
激活单元样本点聚集在目标附近
但是覆盖范围不够精确,超出the area of interest
由此提出DCNv2, 具有增强建模的能力,可用于学习可变形卷积
with enhanced modeling power for learning deformable convolutions.
添加了两种互补的模式:
- 更广泛应用可变形卷积,在更多层上使用可变形卷积
- 在原有基础上不仅加上偏移(offset),而且加上幅值(amplitude)的控制
为了充分利用可变形卷积提取的信息,吸取知识蒸馏的手段,进行培训。
- 教师网络:R-CNN, 针对裁剪内容进行分类的一个网络,防止学习不在目标范围以外的内容
- 学生网络:Faster R-CNN
2. 可变形卷积行为分析
2.1 空间支持可视化
可视化三个内容:
- 有效感受野 : 可视化感受野
- 有效采样位置: 对采样点求梯度,然后可视化
- 误差界限显著性区域 : 参考显著性分析理论,进行可视化
2.2 可变形网络空间支持
Faster R-CNN中Conv1-Conv4使用在Head中的,Conv5使用在Classification network上

ResNet-50 Conv5里边的3$\times$3的卷积层都使用可变形卷积替换。Aligned RoI pooling 由 Deformable RoI Pooling取代,当offset学习率设置为0,那么Deformable RoI Pooling就退化为Aligned RoI Pooling。 ps: 这是V1中的操作。

从中观察到:
- 常规卷积可以一定程度上模拟几何变化,通过网络权重做到的
- 可变形卷积模拟几何变化能力显著提升,但是不够精确。
3. 更多可变形卷积层
v2 中进行改进的部分主要有三点
3.1 使用更多的可变形卷积
在Conv3, Conv4, Conv5中所有的3$\times$3的卷积层全部被替换掉。对于pascal voc简单数据集,堆叠三层以上就会饱和。
3.2 在DCNv1基础(添加offset)上添加幅值参数
回顾一下DCNv1:

R 是相当于3$\times$3的kernel, \(p_0\)是当前中心点,\(p_n\)枚举每一个点。
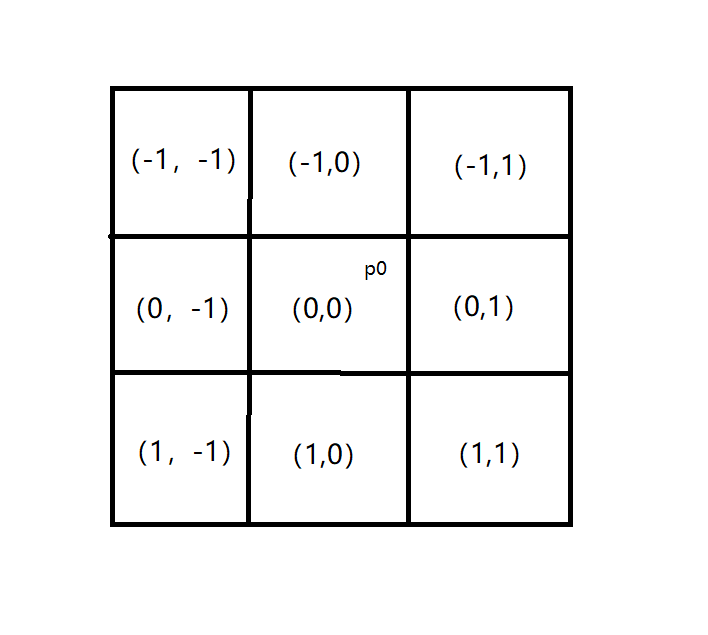
可见,在普通卷积基础上,offset \(\Delta p_n\)是主要改进点。
那DCNv2主要改了哪些地方?
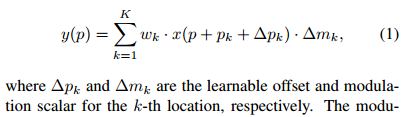
在v1基础上,添加了\(\Delta m_k\), 一个控制幅值变化的量。
ROI pooling是如何改进的?
先看Faster R-CNN中的ROI Pooling:
然后先看DCNv1的Deformable RoI Pooling


主要是添加了offset fields \(\Delta p_{ij}\) 来控制偏移部分。
DCNv2的Deformable RoI Pooling也是将幅值引入,如下图:

类似的也添加了幅值变量,在训练的过程中进行学习。
3.3 R-CNN Feature Mimicking
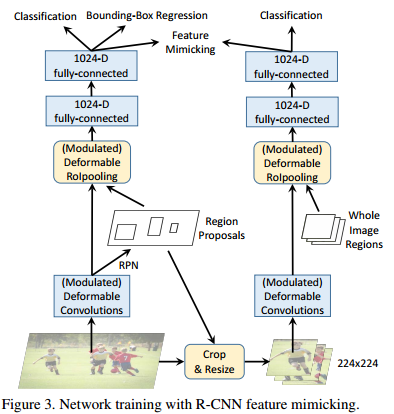
采用了类似知识蒸馏的方法,用一个R-CNN分类网络作为teacher network 帮助Faster R-CNN更好收敛到目标区域内。
得到ROI之后,在原图中抠出这个ROI,resize到224x224,再送到一个RCNN中进行分类,这个RCNN只分类,不回归。然后,主网络fc2的特征去模仿RCNN fc2的特征,实际上就是两者算一个余弦相似度,1减去相似度作为loss即可
代码
GitHub几个源码
<https://github.com/msracver/Deformable-ConvNets> 官方提供的版本,有DeepLab, Faster R-CNN, FPN, R-FCN等。源码使用的是mxnet。
https://github.com/open-mmlab/mmdetection 集成了可变形卷积,源码使用的是pytorch。
- https://github.com/ChunhuanLin/deform_conv_pytorch 测试deform_conv_V1的准确度的demo.py,源码使用的是pytorch。
- https://github.com/4uiiurz1/pytorch-deform-conv-v2一个简单版本的DCNv2 ,源码使用的是pytorch
https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0 Pytorch 1.0 最新的完整的DCNv2
参考文献
https://blog.csdn.net/u013841196/article/details/80713314
http://arxiv.org/abs/1811.11168
https://www.cnblogs.com/jiujing23333/p/10059612.html
https://www.jianshu.com/p/23264e17d860
论文阅读:Deformable ConvNets v2的更多相关文章
- 论文阅读笔记四十:Deformable ConvNets v2: More Deformable, Better Results(CVPR2018)
论文源址:https://arxiv.org/abs/1811.11168 摘要 可变形卷积的一个亮点是对于不同几何变化的物体具有适应性.但也存在一些问题,虽然相比传统的卷积网络,其神经网络的空间形状 ...
- 论文笔记:Deformable ConvNets v2: More Deformable, Better Results
概要 MSRA在目标检测方向Beyond Regular Grid的方向上越走越远,又一篇大作推出,相比前作DCN v1在COCO上直接涨了超过5个点,简直不要太疯狂.文章的主要内容可大致归纳如下: ...
- 论文阅读笔记三十八:Deformable Convolutional Networks(ECCV2017)
论文源址:https://arxiv.org/abs/1703.06211 开源项目:https://github.com/msracver/Deformable-ConvNets 摘要 卷积神经网络 ...
- Deformable ConvNets
Deformable ConvNets 论文 Deformable Convolutional Networks(arXiv:1703.06211) CNN受限于空间结构,具有较差的旋转不变性,较弱的 ...
- YOLO 论文阅读
YOLO(You Only Look Once)是一个流行的目标检测方法,和Faster RCNN等state of the art方法比起来,主打检测速度快.截止到目前为止(2017年2月初),YO ...
- BERT 论文阅读笔记
BERT 论文阅读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 由 @快刀切草莓君 ...
- Action4D:人群和杂物中的在线动作识别:CVPR209论文阅读
Action4D:人群和杂物中的在线动作识别:CVPR209论文阅读 Action4D: Online Action Recognition in the Crowd and Clutter 论文链接 ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
随机推荐
- 有关_meta内容(持续更新)
假设在models里创建了一个类:UserInfo model.UserInfo._meta.app_label #获取该类所在app的app名称 model.UserInfo._meta.model ...
- Django_图片的上传下载显示配置
图片上传的配置 image = models.ImageField(upload_to='org/%Y/%m',...) upload_to默认是上传到项目的'MEDIA_ROOT/org/%Y/%m ...
- php cli传递参数的方法
php cli传递参数的方法 <pre>$options = "f:g:"; $opts = getopt( $options ); print_r($opts); & ...
- python防止sql注入的方法
python防止sql注入的方法: 1. 使用cursor.execute(sql, args)的参数位: sql_str = "select * from py_msgcontrol.py ...
- 2019年广东省赛gdccpc回顾
本次比赛状态一般般,热身赛单人挂机爆零让自己慌了一整天. 开题直接抓E题入手,准备交题后关机(辣鸡云桌面),开机后又告诉我要关机,心急连交两发结果都WA了,最后靠队员提醒救了回来.心态还算稳住了.后面 ...
- Deepin 15.11 install nvidia dirver[mei you an zhuang shu ru fa]
1.firstly, exec: sudo vim /etc/modprobe.d/blacklist-nouveau.conf[create], and input [blacklist nouve ...
- IDEA设置方法注释生成模板
1.在项目设置里面找到Editor-Live Templates(默认设置里没有这个),然后点击右边的+号,选择Template Group,创建模板组,我这里起名叫Silentdoer: 2.选中自 ...
- 异常查错java.net.SocketException: Connection reset
用httpclient访问后台接口报错java.net.SocketException: Software caused connection abort: recv failed,百度了一圈都说是由 ...
- C++实现2048小游戏
代码如下: #define _CRT_SECURE_NO_WARNINGS//去掉编译器内部扩增问题 #include<stdio.h> #include<stdlib.h> ...
- python使用ORM之如何调用多对多关系
在models.py中,我创建了两张表,他们分别是作者表和书籍表,且之间的关系是多对多. # 书 class Book(models.Model): id = models.AutoField(pri ...