【Python】分析自己的博客 https://www.cnblogs.com/xiandedanteng/p/?page=XX,看每个月发帖量是多少
要执行下面程序,需要安装Beautiful Soup和requests,具体安装方法请见:https://www.cnblogs.com/xiandedanteng/p/8668492.html
# 分析自己的博客 https://www.cnblogs.com/xiandedanteng/p/?page=XX,看每个月发帖量是多少
from bs4 import BeautifulSoup
import requests
import re
user_agent='Mozilla/4.0 (compatible;MEIE 5.5;windows NT)'
headers={'User-Agent':user_agent}
dic={}; #定义个字典对象,存月份和个数
#把2013年8月以来的每个月都放进去
for i in range(8,13):
yearMonth="2013-"+"{:0>2d}".format(i)
dic[yearMonth]=0
for i in range(1,13):
yearMonth="2014-"+"{:0>2d}".format(i)
dic[yearMonth]=0
for i in range(1,13):
yearMonth="2015-"+"{:0>2d}".format(i)
dic[yearMonth]=0
for i in range(1,13):
yearMonth="2016-"+"{:0>2d}".format(i)
dic[yearMonth]=0
for i in range(1,13):
yearMonth="2017-"+"{:0>2d}".format(i)
dic[yearMonth]=0
for i in range(1,13):
yearMonth="2018-"+"{:0>2d}".format(i)
dic[yearMonth]=0
for i in range(1,12):
yearMonth="2019-"+"{:0>2d}".format(i)
dic[yearMonth]=0
for i in range(1,90):
html=requests.get('http://www.cnblogs.com/xiandedanteng/p/?page='+str(i),headers=headers)
soup= BeautifulSoup(html.text,'html.parser',from_encoding='utf-8');
for descDiv in soup.find_all(class_="postDesc2"):
rawInfo=descDiv.text #得到class="postDesc2"的div的内容
yearMonth=re.search(r'\d{4}-\d{2}',rawInfo).group() #用正则表达式去匹配年月并取其值
# 将年月存入字典,如果存在就在原基础上加一
if yearMonth in dic:
dic[yearMonth]=dic[yearMonth]+1
else:
dic[yearMonth]=1
# 打印字典,需要再放开
for item in dic.items():
print(item)
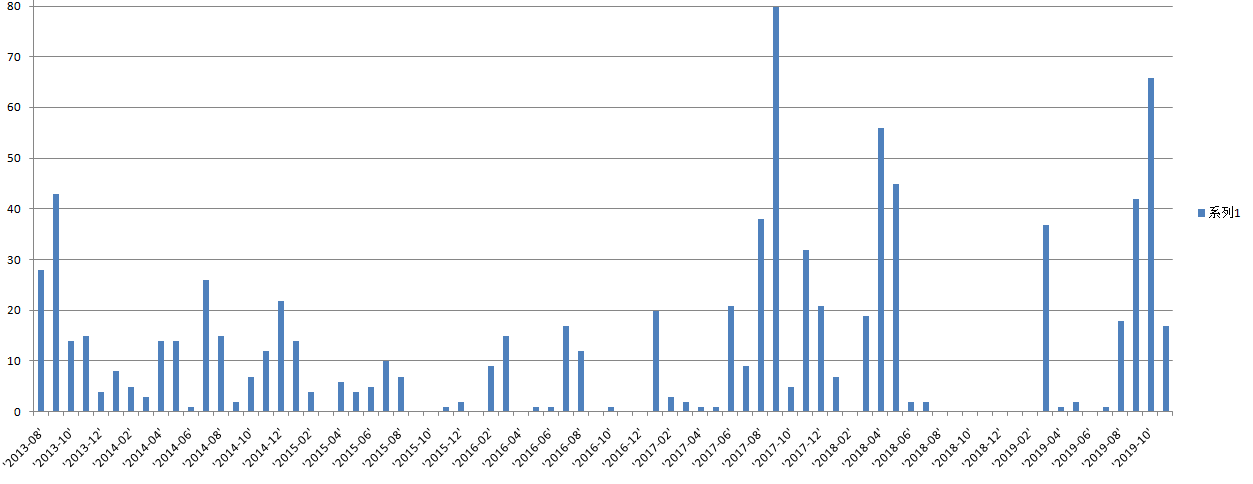
得到的结果是:
('2013-08', 28)
('2013-09', 43)
('2013-10', 14)
('2013-11', 15)
('2013-12', 4)
('2014-01', 8)
('2014-02', 5)
('2014-03', 3)
('2014-04', 14)
('2014-05', 14)
('2014-06', 1)
('2014-07', 26)
('2014-08', 15)
('2014-09', 2)
('2014-10', 7)
('2014-11', 12)
('2014-12', 22)
('2015-01', 14)
('2015-02', 4)
('2015-03', 0)
('2015-04', 6)
('2015-05', 4)
('2015-06', 5)
('2015-07', 10)
('2015-08', 7)
('2015-09', 0)
('2015-10', 0)
('2015-11', 1)
('2015-12', 2)
('2016-01', 0)
('2016-02', 9)
('2016-03', 15)
('2016-04', 0)
('2016-05', 1)
('2016-06', 1)
('2016-07', 17)
('2016-08', 12)
('2016-09', 0)
('2016-10', 1)
('2016-11', 0)
('2016-12', 0)
('2017-01', 20)
('2017-02', 3)
('2017-03', 2)
('2017-04', 1)
('2017-05', 1)
('2017-06', 21)
('2017-07', 9)
('2017-08', 38)
('2017-09', 80)
('2017-10', 5)
('2017-11', 32)
('2017-12', 21)
('2018-01', 7)
('2018-02', 0)
('2018-03', 19)
('2018-04', 56)
('2018-05', 45)
('2018-06', 2)
('2018-07', 2)
('2018-08', 0)
('2018-09', 0)
('2018-10', 0)
('2018-11', 0)
('2018-12', 0)
('2019-01', 0)
('2019-02', 0)
('2019-03', 37)
('2019-04', 1)
('2019-05', 2)
('2019-06', 0)
('2019-07', 1)
('2019-08', 18)
('2019-09', 42)
('2019-10', 66)
('2019-11', 17)
把这个文本拷贝到Notepad++里面,将括号替换掉,然后另存为csv文件。再用Excel打开文件生成图表如下:
工程下载:https://files.cnblogs.com/files/xiandedanteng/6.everyMonthMyblog20191104.rar
--END-- 2019年11月4日09:06:52
【Python】分析自己的博客 https://www.cnblogs.com/xiandedanteng/p/?page=XX,看每个月发帖量是多少的更多相关文章
- python学习大纲目录(转自alex博客https://www.cnblogs.com/alex3714/)
day01: 介绍.基本语法.流程控制 Python介绍 发展史 Python 2 or 3? 安装 Hello World程序 变量 用户输入 模块初识 .pyc是个什么鬼? 数据类型初识 数据运算 ...
- crontab 问题分析 - CSDN博客 https://blog.csdn.net/tengdazhang770960436/article/details/50997297
cd /mnt/tools/trunk/plugins/personas; python update_keywords.py crontab 问题分析 crontab 问题分析 - CSDN博客 ...
- python实现文章或博客的自动摘要(附java版开源项目)
python实现文章或博客的自动摘要(附java版开源项目) 写博客的时候,都习惯给文章加入一个简介.现在可以自动完成了!TF-IDF与余弦相似性的应用(三):自动摘要 - 阮一峰的网络日志http: ...
- Python课程设计 搭建博客
安装包Github地址 Python综合设计 233博客 注意还有个email文件是需要填入自己信息的,比如最高权限账号和要发送邮件的账号密码 请安装Python2.7环境,本服务器所用环境为 设置环 ...
- 用python爬虫监控CSDN博客阅读量
作为一个博客新人,对自己博客的访问量也是很在意的,刚好在学python爬虫,所以正好利用一下,写一个python程序来监控博客文章访问量 效果 代码会自动爬取文章列表,并且获取标题和访问量,写入exc ...
- mongodb丢失数据的原因剖析 - 迎风飘来的专栏 - CSDN博客 https://blog.csdn.net/yibing548/article/details/50844310
mongodb丢失数据的原因剖析 - 迎风飘来的专栏 - CSDN博客 https://blog.csdn.net/yibing548/article/details/50844310
- FFMPEG推流到RTMP服务器命令 - weixin_37897683的博客 - CSDN博客 https://blog.csdn.net/weixin_37897683/article/details/81225228
FFMPEG推流到RTMP服务器命令 - weixin_37897683的博客 - CSDN博客 https://blog.csdn.net/weixin_37897683/article/detai ...
- python抓取51CTO博客的推荐博客的全部博文,对标题分词存入mongodb中
原文地址: python抓取51CTO博客的推荐博客的全部博文,对标题分词存入mongodb中
- 新博客 https://k8gege.org
新博客 https://k8gege.org 于2019/12/3启用,忘了发 由于博客园长期被Google误报屏蔽,导致Firefox/Chrome等浏览器无法访问博客 发现将被Google误报的文 ...
随机推荐
- sql sever2008 R2 检测到索引可能已损坏。请运行 DBCC CHECKDB。
1.设置成单用户状态 USE MASTER ALTER DATABASE DBNAME SET SINGLE_USER; GO --DBNAME为修复的数据库名 2.执行修复语句,检查和修复数据库及索 ...
- Android笔记(二十一) Android中的Adapter
Android中有一些View是包含多个元素的,例如ListView,GridView等,为了给View的每一个元素都设置数据,就需要Adapter了. 常用的Adapter包括ArrayAdapte ...
- 快捷键和功能键、进入DOS命令行的方法、DOS命令讲解、java跨平台原理、JRE和JDK的定义、书写格式
快捷键和功能键A:键盘功能键* a:Tab* b:Shift* c:Ctrl* d:Alt* e:空格 * f:Enter* g:Window* h:上下左右键* i:PrtSc(PrintScree ...
- fs模块
fs.readdir(path, callback) 异步读取目录下文件 path - 文件路径. callback - 回调函数,回调函数带有两个参数err, files,err 为错误信息,fil ...
- keil mdk 菜单 “project” 崩溃问题解决
今天发现我的 Keil MDK5.28z win10系统上面,点击 Project 菜单立即崩溃.网上找到了解决方法 简单粗暴的处理方法:重装keil ,但是依然点击 project 崩溃. 通过搜索 ...
- 004_硬件基础电路_AD各层含义
- ElasticSearch 集群环境搭建,安装ElasticSearch-head插件,安装错误解决
ElasticSearch-5.3.1集群环境搭建,安装ElasticSearch-head插件,安装错误解决 说起来甚是惭愧,博主在写这篇文章的时候,还没有系统性的学习一下ES,只知道可以拿来做全文 ...
- Greenplum table 之 外部表
转载自: https://www.cnblogs.com/kingle-study/p/10552097.html 一.外部表介绍 Greenplum 在数据加载上有一个明显的优势,就是支持数据的并发 ...
- 【csp模拟赛九】--dfs3
这道题贪心错误:直接dfs就行,枚举新开一个还是往之前的里面塞 贪心代码(80): #include<cstdio> #include<algorithm> #include& ...
- P3688 [ZJOI2017] 树状数组 【二维线段树】
题目描述:这里有一个写挂的树状数组: 有两种共\(m\)个操作: 输入\(l,r\),在\([l,r]\)中随机选择一个整数\(x\)执行\(\text{Add}(x)\) 输入\(l,r\),询问执 ...