记录lucene.net的使用过程
之前公司要做一个信息展示的网站,领导说要用lucene.net来实现全文检索,类似百度的搜索功能,但是本人技术有限,只是基本实现搜索和高亮功能,特此记录;
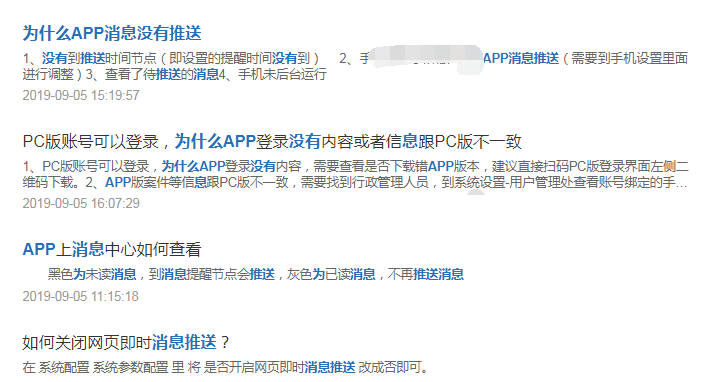
先看下页面效果,首先我搜索“为什么APP消息没有推送”,出来的结果如下图:
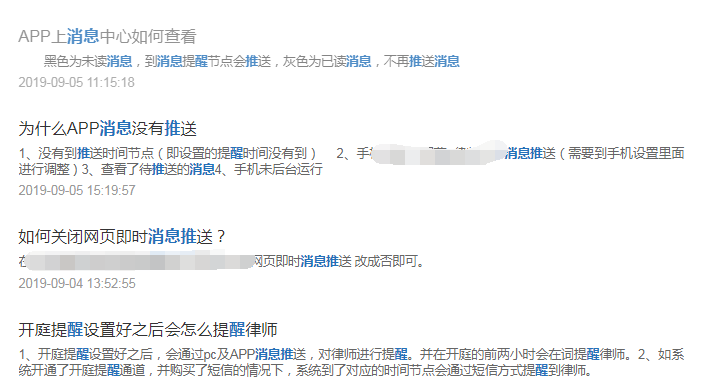
然后我再搜索“醒 消息 推”,出来结果如下图:
然后说下,我使用的是Lucene.net版本是2.9.22,盘古分词的版本是2.3.1,注意,版本lucene.net和盘古分词的版本一定要对上,之前我用Lucene.net3.0的版本,就一直有错误,后来换到低版本才没问题的;
接着是关键的类LuceneHelper,如下所示:
public class LuceneHelper
{
readonly LogHelper _logHelper = new LogHelper(MethodBase.GetCurrentMethod());
private LuceneHelper() { } #region 单例
private static LuceneHelper _instance = null;
private static readonly object Lock = new object();
/// <summary>
/// 单例
/// </summary>
public static LuceneHelper instance
{
get
{
lock (Lock)
{
if (_instance == null)
{
_instance = new LuceneHelper();
PanGu.Segment.Init(PanGuXmlPath);//使用盘古分词,一定要记得初始化
}
return _instance;
}
}
}
#endregion #region 分词测试 /// <summary>
/// 处理关键字为索引格式
/// </summary>
/// <param name="keywords"></param>
/// <returns></returns>
private string GetKeyWordsSplitBySpace(string keywords)
{
PanGuTokenizer ktTokenizer = new PanGuTokenizer();//使用盘古分词器来吧关键字分词
StringBuilder result = new StringBuilder();
ICollection<WordInfo> words = ktTokenizer.SegmentToWordInfos(keywords);
foreach (WordInfo word in words)
{
if (word == null)
{
continue;
}
//result.AppendFormat("{0}^{1}.0 ", word.Word, (int)Math.Pow(3, word.Rank));
result.AppendFormat("{0} ", word.Word);
}
return result.ToString().Trim();
}
#endregion #region 创建索引
/// <summary>
/// 创建索引
/// </summary>
/// <param name="datalist"></param>
/// <returns></returns>
public bool CreateIndex<T>(IList<T> datalist)
{
IndexWriter writer = null;
try
{
writer = new IndexWriter(directory_luce, analyzer, true, IndexWriter.MaxFieldLength.LIMITED);//false表示追加(true表示删除之前的重新写入)
//writer = new IndexWriter(directory_luce, null, true, IndexWriter.MaxFieldLength.LIMITED);//false表示追加(true表示删除之前的重新写入)
}
catch
{
writer = new IndexWriter(directory_luce, analyzer, true, IndexWriter.MaxFieldLength.LIMITED);//false表示追加(true表示删除之前的重新写入)
//writer = new IndexWriter(directory_luce, null, true, IndexWriter.MaxFieldLength.LIMITED);//false表示追加(true表示删除之前的重新写入)
}
foreach (var data in datalist)
{
CreateIndex<T>(writer, data);
}
writer.Optimize();
writer.Close();
return true;
} public bool CreateIndex<T>(IndexWriter writer, T data)
{
try
{ if (data == null) return false;
Document doc = new Document();
Type type = data.GetType(); //创建类的实例
//object obj = Activator.CreateInstance(type, true);
//获取公共属性
PropertyInfo[] Propertys = type.GetProperties();
for (int i = ; i < Propertys.Length; i++)
{
//Propertys[i].SetValue(Propertys[i], i, null); //设置值
PropertyInfo pi = Propertys[i];
string name = pi.Name;
object objval = pi.GetValue(data, null);
string value = objval == null ? "" : objval.ToString(); //值
if (name.ToLower() == "id" || name.ToLower() == "type")//id在写入索引时必是不分词,否则是模糊搜索和删除,会出现混乱
{
doc.Add(new Field(name, value, Field.Store.YES, Field.Index.NOT_ANALYZED));//id不分词
}
else if (name.ToLower() == "IsNewest".ToLower())
{
//doc.Add(new Field(name, value, Field.Store.NO, Field.Index.ANALYZED_NO_NORMS));//分词建索引,但是Field的值不像通常那样被保存,而是只取一个byte,这样节约存储空间
doc.Add(new Field(name, value, Field.Store.YES, Field.Index.NOT_ANALYZED));//IsNewest不分词
}
else if (name.ToLower() == "IsReqular".ToLower())
{
//doc.Add(new Field(name, value, Field.Store.NO, Field.Index.ANALYZED_NO_NORMS));//分词建索引,但是Field的值不像通常那样被保存,而是只取一个byte,这样节约存储空间
doc.Add(new Field(name, value, Field.Store.YES, Field.Index.NOT_ANALYZED));//IsReqular不分词
}
else
{
if (name.ToLower() == "Contents".ToLower())
{
value = GetNoHtml(value);//去除正文的html标签
}
doc.Add(new Field(name, value, Field.Store.YES, Field.Index.ANALYZED));//其他字段分词
}
}
writer.AddDocument(doc);
}
catch (System.IO.FileNotFoundException fnfe)
{
throw fnfe;
}
return true;
}
#endregion #region 在title和content字段中查询数据,该方法未使用,可能有错漏,我使用的是下面的分页查询的;
/// <summary>
/// 在title和content字段中查询数据
/// </summary>
/// <param name="keyword"></param>
/// <returns></returns>
public List<Questions> Search(string keyword)
{ string[] fileds = { "Title", "Contents" };//查询字段
//Stopwatch st = new Stopwatch();
//st.Start();
QueryParser parser = null;// new QueryParser(Lucene.Net.Util.Version.LUCENE_30, field, analyzer);//一个字段查询
parser = new MultiFieldQueryParser(version, fileds, analyzer);//多个字段查询
Query query = parser.Parse(keyword);
int n = ;
IndexSearcher searcher = new IndexSearcher(directory_luce, true);//true-表示只读
TopDocs docs = searcher.Search(query, (Filter)null, n);
if (docs == null || docs.totalHits == )
{
return null;
}
else
{
List<Questions> list = new List<Questions>();
int counter = ;
foreach (ScoreDoc sd in docs.scoreDocs)//遍历搜索到的结果
{
try
{
Document doc = searcher.Doc(sd.doc); string id = doc.Get("ID");
string title = doc.Get("Title");
string content = doc.Get("Contents"); string createdate = doc.Get("AddTime");
PanGu.HighLight.SimpleHTMLFormatter simpleHTMLFormatter = new PanGu.HighLight.SimpleHTMLFormatter("<font color=\"red\">", "</font>");
PanGu.HighLight.Highlighter highlighter = new PanGu.HighLight.Highlighter(simpleHTMLFormatter, new PanGu.Segment());
highlighter.FragmentSize = Int32.MaxValue;
content = highlighter.GetBestFragment(keyword, content);
string titlehighlight = highlighter.GetBestFragment(keyword, title);
if (titlehighlight != "") title = titlehighlight; Questions model = new Questions
{
ID = int.Parse(id),
Title = title,
Contents = content,
AddTime = DateTime.Parse(createdate)
}; list.Add(model);
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
counter++;
}
return list;
}
//st.Stop();
//Response.Write("查询时间:" + st.ElapsedMilliseconds + " 毫秒<br/>"); }
#endregion #region 在不同的分类下再根据title和content字段中查询数据(分页)
/// <summary>
/// 在不同的类型下再根据title和content字段中查询数据(分页)
/// </summary>
/// <param name="_type">分类,传空值查询全部</param>
/// <param name="keyword"></param>
/// <param name="PageIndex"></param>
/// <param name="PageSize"></param>
/// <param name="TotalCount"></param>
/// <returns></returns>
public List<Questions> Search(string _type,bool? _isnew,bool? _isreq ,string keyword, int PageIndex, int PageSize, out int TotalCount)
{
try
{
if (PageIndex < ) PageIndex = ;
//Stopwatch st = new Stopwatch();
//st.Start();
BooleanQuery bq = new BooleanQuery();
if (_type != "" && _type != "-100")
{
QueryParser qpflag = new QueryParser(version, "Type", analyzer);//一个字段查询
Query qflag = qpflag.Parse(_type);
bq.Add(qflag, Lucene.Net.Search.BooleanClause.Occur.MUST);//与运算
}
if (_isnew.HasValue)
{
QueryParser qpnew = new QueryParser(version, "IsNewest", analyzer);
Query qnew = qpnew.Parse(_isnew.Value.ToString());
bq.Add(qnew, Lucene.Net.Search.BooleanClause.Occur.MUST);
}
if (_isreq.HasValue)
{
QueryParser qpreq = new QueryParser(version, "IsReqular", analyzer);
Query qreq = qpreq.Parse(_isnew.Value.ToString());
bq.Add(qreq, Lucene.Net.Search.BooleanClause.Occur.MUST);
} string keyword2 = keyword;
if (keyword != "")
{ keyword = GetKeyWordsSplitBySpace(keyword); string[] fileds = { "Title", "Contents" };//查询字段
QueryParser parser = null;// new QueryParser(version, field, analyzer);//一个字段查询
parser = new MultiFieldQueryParser(version, fileds, analyzer);//多个字段查询
//parser.DefaultOperator = QueryParser.Operator.OR;
parser.SetDefaultOperator(QueryParser.Operator.OR);//这里QueryParser.Operator.OR表示并行结果,相当于模糊搜索,QueryParser.Operator.AND相当于精准搜索
Query queryKeyword = parser.Parse(keyword); bq.Add(queryKeyword, Lucene.Net.Search.BooleanClause.Occur.MUST);//与运算
} //TopScoreDocCollector collector = TopScoreDocCollector.Create(PageIndex * PageSize, false);
IndexSearcher searcher = new IndexSearcher(directory_luce, true);//true-表示只读 //Sort sort = new Sort(new SortField("AddTime", SortField.DOC, false)); //此处为结果排序功能,但是使用排序会影响搜索权重(类似百度搜索排名机制)
//TopDocs topDocs = searcher.Search(bq, null, PageIndex * PageSize, sort);
TopDocs topDocs = searcher.Search(bq, null, PageIndex * PageSize);
//searcher.Search(bq, collector);
if (topDocs == null || topDocs.totalHits == )
{
TotalCount = ;
return null;
}
else
{
int start = PageSize * (PageIndex - );
//结束数
int limit = PageSize;
ScoreDoc[] hits = topDocs.scoreDocs;
List<Questions> list = new List<Questions>();
int counter = ;
TotalCount = topDocs.totalHits;//获取Lucene索引里的记录总数 //Lucene.Net.Highlight.SimpleHTMLFormatter simpleHTMLFormatter = new Lucene.Net.Highlight.SimpleHTMLFormatter("<em class=\"hl-l-t-main\">", "</em>");
//Lucene.Net.Highlight.Highlighter highlighter = new Lucene.Net.Highlight.Highlighter(simpleHTMLFormatter,new Lucene.Net.Highlight.QueryScorer(bq)); foreach (ScoreDoc sd in hits)//遍历搜索到的结果
{
try
{
Document doc = searcher.Doc(sd.doc);
string id = doc.Get("ID");
string title = doc.Get("Title");
string content = doc.Get("Contents");
string updatetime = doc.Get("AddTime"); PanGu.HighLight.SimpleHTMLFormatter simpleHTMLFormatter = new PanGu.HighLight.SimpleHTMLFormatter("<em class=\"hl-l-t-main\">", "</em>");
PanGu.HighLight.Highlighter highlighter = new PanGu.HighLight.Highlighter(simpleHTMLFormatter, new Segment());//搜索关键字高亮显示,上面的高亮样式自己写
highlighter.FragmentSize = Int32.MaxValue; //这里如果值小于搜索内容的长度的话,会导致搜索结果被截断,因此设置最大,根据需求来吧
string contentHighlight = highlighter.GetBestFragment(keyword2, content);
string titleHighlight = highlighter.GetBestFragment(keyword2, title); //string titleHighlight = highlighter.GetBestFragment(analyzer, "Title", title); //string contentHighlight = highlighter.GetBestFragment(analyzer, "Contents", content); title = string.IsNullOrEmpty(titleHighlight) ? title : titleHighlight;
content = string.IsNullOrEmpty(contentHighlight) ? content : contentHighlight; var model = new Questions
{
ID = int.Parse(id),
Title = title,
Contents = content,
AddTime = DateTime.Parse(updatetime)
};
list.Add(model);
}
catch (Exception ex)
{
//这里可以写错误日志
}
counter++;
}
return list;
}
//st.Stop();
}
catch (Exception e)
{
TotalCount = ;
return null;
} } /// <summary>
/// 去除html标签
/// </summary>
/// <param name="StrHtml"></param>
/// <returns></returns>
public string GetNoHtml(string StrHtml)
{
string strText="";
if (!string.IsNullOrEmpty(StrHtml))
{
strText = System.Text.RegularExpressions.Regex.Replace(StrHtml, @"<[^>]+>", "");
strText = System.Text.RegularExpressions.Regex.Replace(strText, @"&[^;]+;", "");
strText = System.Text.RegularExpressions.Regex.Replace(strText, @"\\s*|\t|\r|\n", ""); }
return strText; }
#endregion #region 删除索引数据(根据id)
/// <summary>
/// 删除索引数据(根据id)
/// </summary>
/// <param name="id"></param>
/// <returns></returns>
public bool Delete(string id)
{
bool IsSuccess = false;
Term term = new Term("id", id);
//Analyzer analyzer = new StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_30);
//Version version = new Version();
//MultiFieldQueryParser parser = new MultiFieldQueryParser(version, new string[] { "name", "job" }, analyzer);//多个字段查询
//Query query = parser.Parse("小王"); //IndexReader reader = IndexReader.Open(directory_luce, false);
//reader.DeleteDocuments(term);
//Response.Write("删除记录结果: " + reader.HasDeletions + "<br/>");
//reader.Dispose(); IndexWriter writer = new IndexWriter(directory_luce, analyzer, false, IndexWriter.MaxFieldLength.LIMITED);
writer.DeleteDocuments(term); // writer.DeleteDocuments(term)或者writer.DeleteDocuments(query);
////writer.DeleteAll();
writer.Commit();
//writer.Optimize();//
IsSuccess = writer.HasDeletions();
writer.Close();
return IsSuccess;
}
#endregion #region 删除全部索引数据
/// <summary>
/// 删除全部索引数据
/// </summary>
/// <returns></returns>
public bool DeleteAll()
{
bool IsSuccess = true;
try
{
IndexWriter writer = new IndexWriter(directory_luce, analyzer, false, IndexWriter.MaxFieldLength.LIMITED);
writer.DeleteAll();
writer.Commit();
writer.Optimize();//
IsSuccess = writer.HasDeletions();
writer.Close();
}
catch
{
IsSuccess = false;
}
return IsSuccess;
}
#endregion #region directory_luce
private Lucene.Net.Store.Directory _directory_luce = null;
/// <summary>
/// Lucene.Net的目录-参数
/// </summary>
public Lucene.Net.Store.Directory directory_luce
{
get
{
if (_directory_luce == null) _directory_luce = Lucene.Net.Store.FSDirectory.Open(directory);
return _directory_luce;
}
}
#endregion #region directory
private System.IO.DirectoryInfo _directory = null;
/// <summary>
/// 索引在硬盘上的目录
/// </summary>
public System.IO.DirectoryInfo directory
{
get
{
if (_directory == null)
{
string dirPath = HttpContext.Current.Server.MapPath("/LuceneDic");
if (System.IO.Directory.Exists(dirPath) == false)
_directory = System.IO.Directory.CreateDirectory(dirPath);
else
_directory = new System.IO.DirectoryInfo(dirPath);
}
return _directory;
}
}
#endregion #region analyzer
private Analyzer _analyzer = null;
/// <summary>
/// 分析器
/// </summary>
public Analyzer analyzer
{
get
{
//if (_analyzer == null)
{
// _analyzer = new Lucene.Net.Analysis.PanGu.PanGuAnalyzer();//弃用盘古分词,感觉有点问题,测试下来没有自带分词好用,也有可能是好用的,但是之前用的高版本lucene.net,导致分词失效
_analyzer = new StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_29);
}
return _analyzer;
}
}
#endregion #region version
private static Lucene.Net.Util.Version _version = Lucene.Net.Util.Version.LUCENE_29;
/// <summary>
/// 版本号枚举类
/// </summary>
public Lucene.Net.Util.Version version
{
get
{
return _version;
}
}
#endregion
/// <summary>
/// 盘古分词的配置文件
/// </summary>
protected static string PanGuXmlPath
{
get
{
return HttpContext.Current.Server.MapPath("/PanGu/PanGu.xml");
}
}
}
然后是一些需要引用的DLL和盘古分词的字典文件等,如下所示:
至此Lucene.net的简单应用到此结束,谢谢!
记录lucene.net的使用过程的更多相关文章
- 记录sqoop同步失败问题解决过程,过程真的是很崎岖。(1月6日解决)
记录sqoop同步失败问题解决过程,过程真的是很崎岖.事发原因:最近突然出现sqoop export to mysql时频繁出错.看了下日志是卡在某条数据过不去了,看异常.看sqoop生成的mr并未发 ...
- step_by_step_记录deepin下curl安装过程
记录 deepin 下 curl 安装过程 wget https://curl.haxx.se/download/curl-7.55.1.tar.gz .tar.gz cd curl-/ ./conf ...
- 【Android实战】记录自学自己定义GifView过程,能同一时候支持gif和其它图片!【有用篇】
之前写了一篇博客.<[Android实战]记录自学自己定义GifView过程,具体解释属性那些事! [学习篇]> 关于自己定义GifView的,具体解说了学习过程及遇到的一些类的解释,然后 ...
- 记录手动签名APK的过程
记录手动签名APK的过程 前两天更新了华为平台上的APK,被驳回,原因是新APK签名和老的APK不一致,老用户安装会失败,用命令行安装会报如下的错误: harlanc@harlancdeMacBook ...
- 记录一下安装hexo的过程
记录一下安装hexo的过程 首先你的电脑需要安装node.js和Git 安装好Git之后需要配置本机与Github之间的ssh方便更新同步博客到Github上,在一个地方新建一个文件夹作为我们博客的根 ...
- 理解Lucene索引与搜索过程中的核心类
理解索引过程中的核心类 执行简单索引的时候需要用的类有: IndexWriter.Directory.Analyzer.Document.Field 1.IndexWriter IndexWr ...
- lucene 建立索引的过程
时间 -- :: CSDN博客 原文 http://blog.csdn.net/caohaicheng/article/details/ 看lucene主页(http://lucene.apach ...
- lucene建立索引的过程
建立索引过程 用户提交数据=>solr建立索引=>调用lucene包建立索引 官方建立索引和查询索引的例子如下: http://lucene.apache.org/core/4_10_3/ ...
- 记录一次OOM分析过程
工具: jstat jmap jhat 1.jstat查看gc情况 S0C.S1C.S0U.S1U:Survivor 0/1区容量(Capacity)和使用量(Used) EC.EU:Eden区容量和 ...
随机推荐
- .NET 5 = .NET Core vNext
Introducing .NET 5 .NET 5 = .NET Core vNext .NET 5 is the next step forward with .NET Core. The proj ...
- 阶段5 3.微服务项目【学成在线】_day03 CMS页面管理开发_09-修改页面-服务端-接口开发
需要写两个接口 api的接口内定义两个方法.修改的地方单独传了id @ApiOperation("根据页面id查询页面信息") public CmsPage findById(St ...
- Flutter 圆形/圆角头像图片
图片显示 1.本地图片 Image.asset加载项目资源包的图片 //先将图片拷贝到项目 images 目录中,然后在 pubspec.yaml文件配置文件相对路径到 assets Image.as ...
- 基于c开发的全命令行音频播放器
cmus是一个内置了音频播放器的强大的音乐文件管理器.用它的基于ncurses的命令行界面,你可以浏览你的音乐库,并从播放列表或队列中播放音乐,这一切都是在命令行下. Linux上安装cmus 首先, ...
- ubuntu 右上角网络图标不见了
sudo service network-manager stop sudo rm /var/lib/NetworkManager/NetworkManager.state sudo service ...
- Java中的一些关键字:static,final,和abstract,interface,以及访问修饰符说明
1.关键字可以修饰的说明: 关键字 属性(是否可修饰) 方法(是否可修饰) 类(是否可修饰) static 是 是 是 final 是 是 是 abstract 否 是 是 2.关键字的意义: 关键字 ...
- centOS 安装 pm2
安装 npm install -g pm2 自启 pm2 startup centos 启动 pm2 start server/add.js (以实际路径为准) 其他命令: pm2 list #查看进 ...
- list列表相关操作
] ] ] : :-]print(s10)# a.sort(reve# rse=True)# print(a)# a.reverse()# print(a) lst = [], 'wusir','cg ...
- 编写一个自定义事件类,包含on/off/emit/once方法
function Event() { this._events = {}; } Event.prototype.on = function(type, fn) { if (!this._events[ ...
- PowerPoint储存此文件时发生错误 出现错误的问题解决方法
.单击“文件”,单击“选项”,然后单击“加载项”. . 在管理下拉框中选择“COM加载项”,单击“转到”按钮. . 检查是否存在有任何加载项,清除所有复选框来禁用它们. . 关闭PPT并重新启动,测试 ...