使用XPath爬取网页数据
我们以我的博客为例,来爬取我所有写过的博客的标题。
首先,打开我的博客页面,右键“检查”开始进行网页分析。我们选中博客标题,再次右键“检查”即可找到标题相应的位置,我们继续点击右键,选择Copy,再点击Copy XPath,即可获得对应的XPath编码,我们可以先将它保存在一个文本文档中。
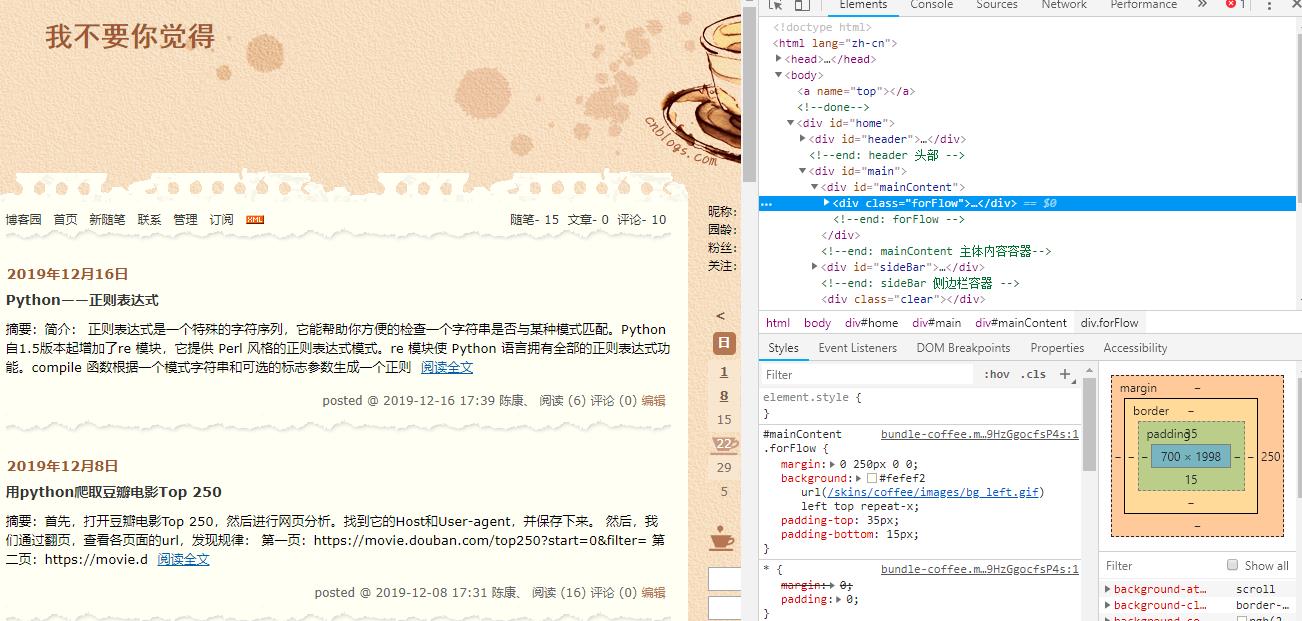
我们再多次对各个标题重复以上操作,即可得到关于标题的XPath编码的规律。我们不难看出,对于我的博客的标题的XPath编码格式为“//*[@id="mainContent"]/div/div[n]/div[2]/a”。
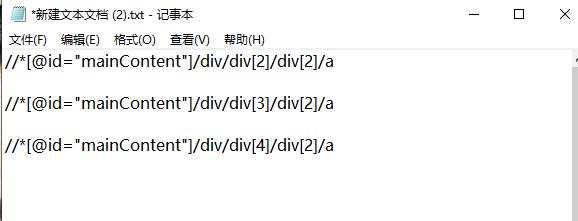
又因为我的博客共有2页,所以我们还需找到网页url的规律,经过分析,我们发现格式为'https://www.cnblogs.com/Chen-K/default.html?page='+str(i+1)。
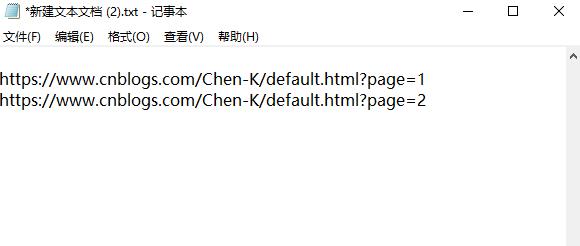
下面便可开始写代码:
import requests
from lxml import etree for i in range(0,2):
url = 'https://www.cnblogs.com/Chen-K/default.html?page='+str(i+1)
html = requests.get(url)
etree_html = etree.HTML(html.text)
a = etree_html.xpath('//*[@id="mainContent"]/div/div/div[2]/a/text()') # 加text()是为了将结果以txt格式输出
for j in a:
print(j)
运行结果:

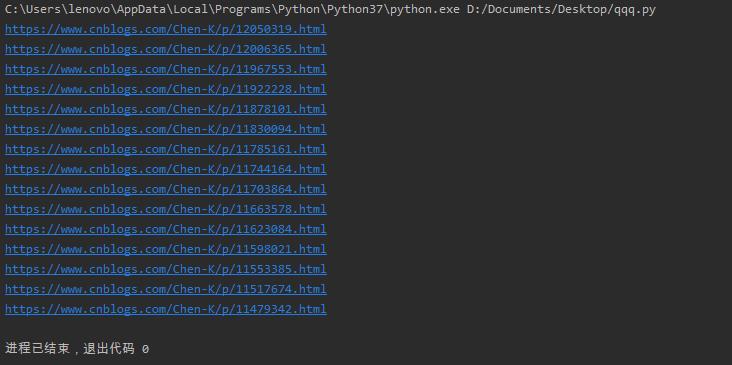
若是要爬取其他的数据,我们只需复制下来相应的XPath编码即可。操作过程大同小异,我们便不再多加赘述,下面我们以爬取每个博客的url为例:
import requests
from lxml import etree for i in range(0,2):
url = 'https://www.cnblogs.com/Chen-K/default.html?page='+str(i+1)
html = requests.get(url)
etree_html = etree.HTML(html.text)
a = etree_html.xpath('//*[@id="mainContent"]/div/div/div[2]/a/@href')
for j in a:
print(j)
运行结果:
XPath与BeautifulSoup相比,操作更加简单,代码也更为简洁,如果需要爬取比较多的信息,使用XPath将会大大减少我们的工作量。当然,我们想要使用XPath,必须先安装lxml库,而我们有两个方法可以安装lxml库。
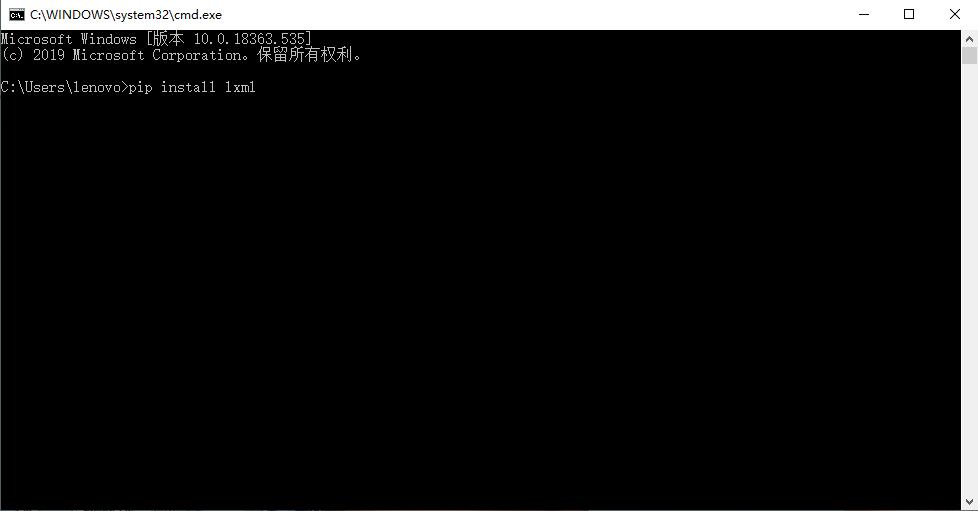
1、使用pip安装
我们只需打开命令行,输入指令“pip install lxml”,然后等待安装即可。
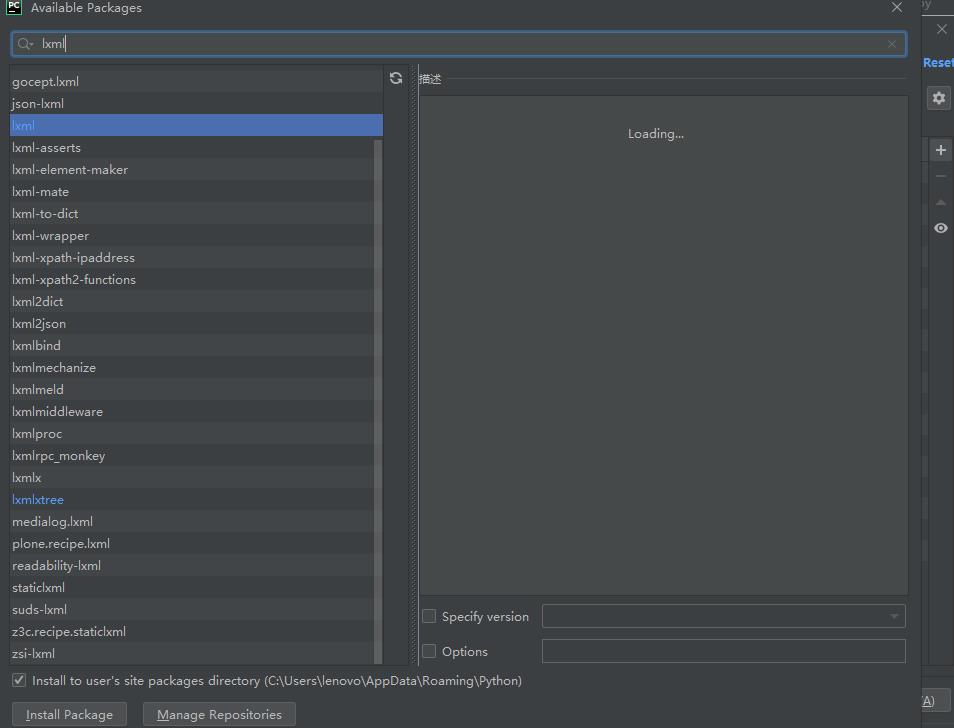
2、使用PyCharm安装
我们点击“文件”,找到设置,打开后点击右边的加号,然后在上面的搜索框中输入lxml,然后点击下方install,等待安装即可。
安装好lxml库之后,我们便可以使用其相关功能了。
使用XPath爬取网页数据的更多相关文章
- 爬虫系列4:Requests+Xpath 爬取动态数据
爬虫系列4:Requests+Xpath 爬取动态数据 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参 ...
- 使用webdriver+urllib爬取网页数据(模拟登陆,过验证码)
urilib是python的标准库,当我们使用Python爬取网页数据时,往往用的是urllib模块,通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获得ur ...
- python之爬取网页数据总结(一)
今天尝试使用python,爬取网页数据.因为python是新安装好的,所以要正常运行爬取数据的代码需要提前安装插件.分别为requests Beautifulsoup4 lxml 三个插件 ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
- 使用 Python 爬取网页数据
1. 使用 urllib.request 获取网页 urllib 是 Python 內建的 HTTP 库, 使用 urllib 可以只需要很简单的步骤就能高效采集数据; 配合 Beautiful 等 ...
- 03:requests与BeautifulSoup结合爬取网页数据应用
1.1 爬虫相关模块命令回顾 1.requests模块 1. pip install requests 2. response = requests.get('http://www.baidu.com ...
- Selenium+Tesseract-OCR智能识别验证码爬取网页数据
1.项目需求描述 通过订单号获取某系统内订单的详细数据,不需要账号密码的登录验证,但有图片验证码的动态识别,将获取到的数据存到数据库. 2.整体思路 1.通过Selenium技术,无窗口模式打开浏览器 ...
- 【推荐】oc解析HTML数据的类库(爬取网页数据)
TFhpple是一个用于解析html数据的第三方库,本人感觉功能还算可以,只不过在使用前必须配置项目. 配置 1.导入libxml2.tbd 2.设置编译路径 使用 这里使用一个例子来说明 http: ...
- 使用puppeteer爬取网页数据实践小结
简单介绍Puppeteer Puppeteer是一个Node库,它通过DevTools协议提供高级API来控制Chrome或Chromium.Puppeteer默认以无头方式运行,但可以配置为有头方式 ...
随机推荐
- Centos - php5.4升级到7.1 yum安装
查看当前 PHP 版本 1 php -v 查看当前 PHP 相关的安装包,删除之 1 2 3 4 5 yum list installed | grep php yum remove php ...
- kotlin之null值安全性
var a: String =null // 编译错误 var a: String? =null // 编译通过 要允许null值, 需要将变量声明为可为null的字符串类型:String? fun ...
- Build Telemetry for Distributed Services之OpenCensus:C#
OpenCensus Easily collect telemetry like metrics and distributed traces from your services OpenCensu ...
- iframe高度自适应方法
<iframe width="100%" id="tbbrecommend" name="tbbrecommend" src=&quo ...
- mysql left join对于索引不生效的问题
SELECT t.val, m.username FROM test.tmp_table AS t LEFT JOIN cehome.uc_members AS m USE INDEX(`mobil ...
- Spring Boot连接MySQL长时间不连接后报错`com.mysql.cj.core.exceptions.ConnectionIsClosedException: No operations allowed after connection closed.`的解决办法
报错:com.mysql.cj.core.exceptions.ConnectionIsClosedException: No operations allowed after connection ...
- 【ARTS】01_25_左耳听风-201900429~20190505
ARTS: Algrothm: leetcode算法题目 Review: 阅读并且点评一篇英文技术文章 Tip/Techni: 学习一个技术技巧 Share: 分享一篇有观点和思考的技术文章 Algo ...
- Zabbix 3.4.3 使用阿里云短信服务进行报警
目录 一.阿里云短信服务 1.1.首先开通阿里云短信服务 1.2 创建签名 1.3 创建短信模板 1.4 创建发送脚本 二.Zabbix Web 配置 2.1 增加 Media types 2.2 给 ...
- mysql写存储过程根据时间变化增加工龄
在工作中遇到要程序根据时间自动增加工龄的需求. php没办法自己发起请求,又不想在服务器上写计划任务crontab,通过用户请求来更改又不能保证用户会去操作. 用数据库的存储过程和事件来完成. 数据库 ...
- CG-CTF 南邮 综合题2
个人网站 http://www.wjlshare.tk 0x00前言 主要考了三块 第一块是文件包含获取源码 第二块是通过sql绕过注入获取密码 第三块是三参数回调后门的利用 做这题的时候结合了别人的 ...