bert系列二:《BERT》论文解读
论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
以下陆续介绍bert及其变体(介绍的为粗体)
bert自从横空出世以来,引起广泛关注,相关研究及bert变体/扩展喷涌而出,如ELECTRA、DistilBERT、SpanBERT、RoBERTa、MASS、UniLM、ERNIE等。
由此,bert的成就不仅是打破了多项记录,更是开创了一副可期的前景。
1, Bert
在看bert论文前,建议先了解《Attention is all you need》论文。
创新点:
- 通过MLM,使用双向Transformer模型,获得更丰富的上下文信息
- 输入方式,句子级输入,可以是一个句子或2个句子,只要给定分隔标记即可
Transformer,多头注意力等概念见bert系列一
预训练语言表示应用到下游任务的2种方式
- feature-based:提取某层或多层特征用于下游任务。代表:ELMo
- fine-tuning:下游任务直接在预训练模型上添加若干层,微调即可。代表:OpenAI GPT,bert
MLM(masked language model):
文中操作为,对15%的token进行mask标记,被标记的token有80%的情况下以[MASK]代替,10%以随机token代替,10%不改变原始token。
为什么要mask操作?因为,要使用双向模型,就面临一个“看见自己”的问题,如bert系列一所述。那么我们将一个token mask掉(是什么蒙蔽了我的双眼?是mask),它就看不见自己啦!
为什么不对选中的token全部mask?因为,预训练中这么做没问题,而在下游任务微调时,[MASK] token是不会出现的,由此产生mismatch问题。
预训练与微调图示
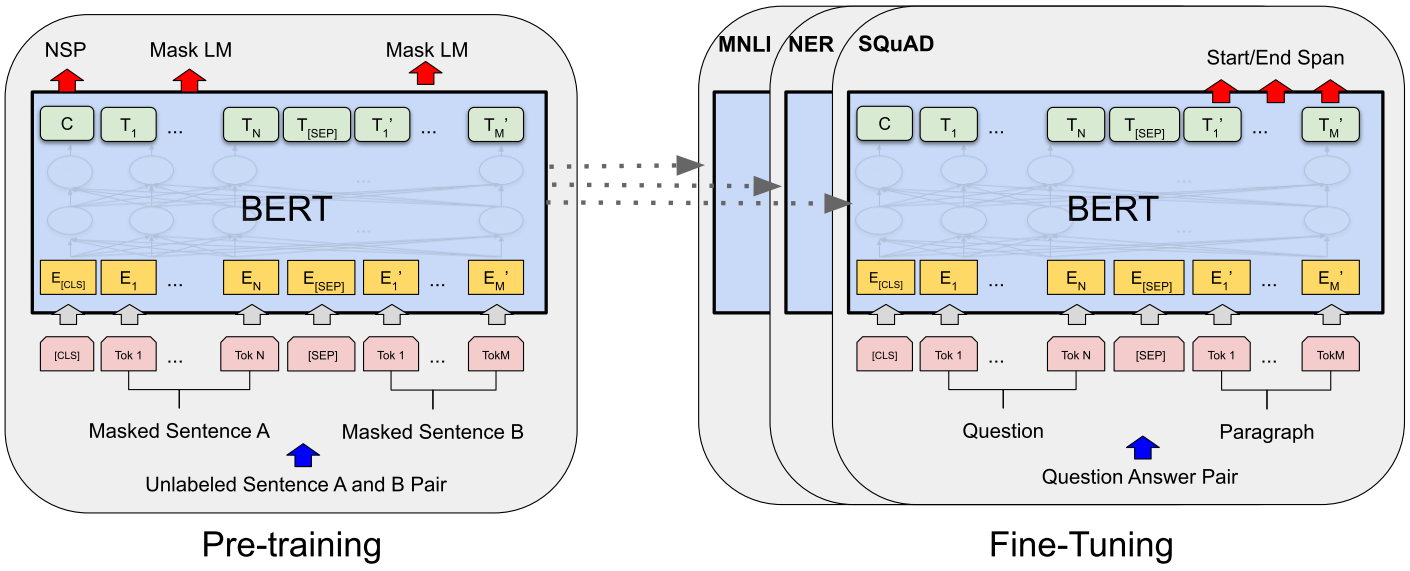
如图,输入可以是一个句子,或2个句子,最后都转换成最大长度521的序列,序列的开头是一个[CLS]标记,用于分类或预测下一句等任务。句子之间也有一个[SEP]标记,用于分隔句子。
对于微调,如图示问答任务,用S表示答案开头,E表示答案末尾。第i个单词(Ti)作为答案开头的概率为:
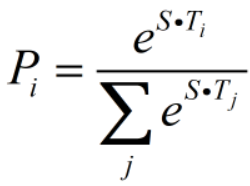
即单词隐层表示Ti与开头S点乘后的softmax值。
候选范围i~j的得分为STi+ETj,取其中得分最大(i,j)的作为答案的预测范围。
输入Embedding使用3个嵌入相加,token嵌入层就是我们通常用的嵌入方式,segment用于区分一个token属于句子A还是B,Position用于位置编码(自注意需要)
如下图:

2, ELECTRA
再介绍一个参数少,训练快,性能好的ELECTRA。来自论文《ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS》
创新点:
不使用mask操作,而是从一个较小的生成器(文中建议大小为判别器的1/4到1/2)中采样来替换一些tokens,然后使用一个判别器去判断这个token是真实的还是生成器产生的。这样模型可以使用全部的tokens而非bert中15%mask的token去训练。
这有点像GAN(生成对抗网络)的概念,不同的是,这里的生成器并不以fool判别器为目标,而是基于极大似然原则训练(其实GAN也可以通过极大似然,只不过生成器反向传播更新需要通过鉴别器)。
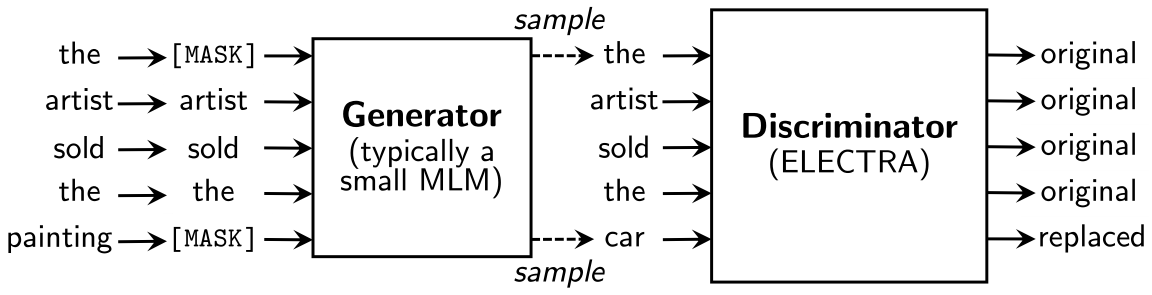
如图,先标记若干位置为mask点,然后使用生成器采样的数据覆盖mask位置,再使用判别器判断每个token是原生的还是伪造的。
生成器及判别器的损失函数为:
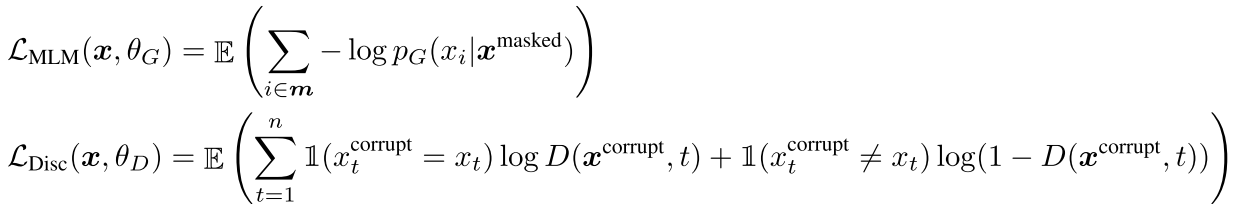
生成器负责对选定的m个点使用极大似然训练,而判别器将要对所有的token进行真伪判断。
最终loss为加权和:
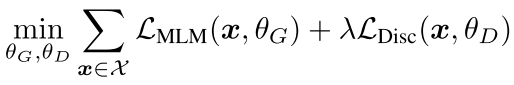
参数共享:
文中仅使用Embedding参数在生成器和判别器中共享(token和positional Embedding,这样做更高效)
3,DistilBERT
论文为《DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter》介绍部分我认为机器之心的这篇文章不错
机器之心:小版BERT也能出奇迹:最火的预训练语言库探索小巧之路
这里只总结一下
创新点
蒸馏模型之前也有。主要是使用了软目标交叉熵损失,以及学生网络初始化的方式。
成就
模型大小减到60%,保留97%语言理解能力,推理速度快60%
训练方式
训练方式为蒸馏(即使用学生网络模拟教师网络,这里bert-base作为教师网络)。
损失由3部分组成,一部分是学生网络与教师网络的软目标交叉熵,一部分为学生网络与教师网络隐状态矢量的嵌入余弦损失,一部分为掩饰语言模型(mlm)损失。其中前2个损失较为重要。
模型移除了token Embedding层和pooler(用于下一句预测),layer数量减到一半。学生网络的初始化也很重要,因为layer只有一半,所以初始化也是从2个layer中取1个。使用非常大的batch_size=4000等。
bert系列二:《BERT》论文解读的更多相关文章
- Bert系列(二)——源码解读之模型主体
本篇文章主要是解读模型主体代码modeling.py.在阅读这篇文章之前希望读者们对bert的相关理论有一定的了解,尤其是transformer的结构原理,网上的资料很多,本文内容对原理部分就不做过多 ...
- Bert系列 源码解读 四 篇章
Bert系列(一)——demo运行 Bert系列(二)——模型主体源码解读 Bert系列(三)——源码解读之Pre-trainBert系列(四)——源码解读之Fine-tune 转载自: https: ...
- Bert系列(三)——源码解读之Pre-train
https://www.jianshu.com/p/22e462f01d8c pre-train是迁移学习的基础,虽然Google已经发布了各种预训练好的模型,而且因为资源消耗巨大,自己再预训练也不现 ...
- nlp任务中的传统分词器和Bert系列伴生的新分词器tokenizers介绍
layout: blog title: Bert系列伴生的新分词器 date: 2020-04-29 09:31:52 tags: 5 categories: nlp mathjax: true ty ...
- swoft| 源码解读系列二: 启动阶段, swoft 都干了些啥?
date: 2018-8-01 14:22:17title: swoft| 源码解读系列二: 启动阶段, swoft 都干了些啥?description: 阅读 sowft 框架源码, 了解 sowf ...
- 网络结构解读之inception系列二:GoogLeNet(Inception V1)
网络结构解读之inception系列二:GoogLeNet(Inception V1) inception系列的开山之作,有网络结构设计的初期思考. Going deeper with convolu ...
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- [论文解读] 阿里DIEN整体代码结构
[论文解读] 阿里DIEN整体代码结构 目录 [论文解读] 阿里DIEN整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x04 模型基类 4.1 基本逻辑 ...
随机推荐
- kickstart批量装机脚本
#!/bin/bash #安装必备的软件 yum -y install dhcp tftp-server tftp xinetd syslinux vsftpd yum -y install *kic ...
- .net 密码明文传输 加密传递方法
未加密传递是这样的 html标签加密使用的是jquery.md5.js 自行官网下载 html代码 <head runat="server"> <meta ht ...
- ubuntu服务器常用命令
1.查看系统版本 cat /etc/issue cat /etc/lsb-release 2.查看cpu lscpu 3.查看内存 free -m 4.查看硬盘大小 fdisk -l |grep Di ...
- mac使用brew安装mysql报RROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
使用mac安装mysql安装完后运行 mysql -uroot -p 报了 ERROR 2002 (HY000): Can't connect to local MySQL server throug ...
- ZR#712
消灭砖块 题意: 很多块砖分布在一个 $ m \times m $ 的矩阵中,他可以消掉以他为左上角顶点的一个 $ n \times n $ 的矩阵里的所有砖块.计算可以消掉最多的砖块数(只能消一次) ...
- python并发——从线程池获取返回值
并发是快速处理大量相似任务的绝佳办法,但对于有返回值的方法,需要一个容器专门来存储每个进程处理完的结果 from multiprocessing import Pool import time #返回 ...
- 18.二叉树的镜像 Java
题目描述 操作给定的二叉树,将其变换为源二叉树的镜像. 输入描述 二叉树的镜像定义:源二叉树 8 / \ 6 10 / \ / \ 5 7 9 11 镜像二叉树 8 / \ 10 6 / \ / \ ...
- Linux .bashrc
Set environmental variable // 用:隔开 export PATH=$PATH:<PATH >:<PATH >:<PATH >:----- ...
- article收藏
sca https://github.com/spring-cloud-incubator/spring-cloud-alibaba spring-cloud-document https://git ...
- code备忘
按空白符分隔(正则) String[] split = line.trim().split("\\s+");