sqoop 安装
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。
总之Sqoop是一个转换工具,用于在关系型数据库与HDFS之间进行数据转换。
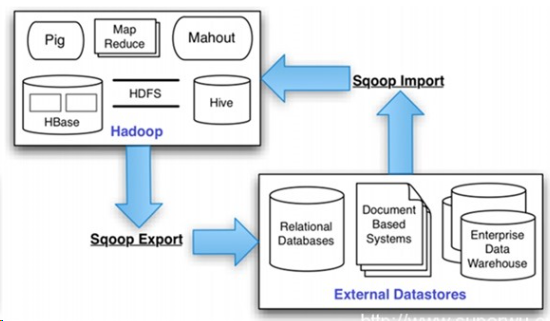
sqoop 安装步骤如下:
1.下载,指定到目录下
下载路径:https://mirrors.tuna.tsinghua.edu.cn/apache/sqoop/1.4.7/
选择版本:sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
安装在master主节点上。
解压:gunzip -d sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
tar -xvf sqoop-1.4.7.bin__hadoop-2.6.0.tar
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop-1.4.7
cd sqoop-1.4.7/
cp sqoop-env-template.sh sqoop-env.sh
vi sqoop-env.sh --根据具体内容填写
# Set Hadoop-specific environment variables here. #Set path to where bin/hadoop is available
#export HADOOP_COMMON_HOME=/home/hadoop/hadoop-2.7. #Set path to where hadoop-*-core.jar is available
#export HADOOP_MAPRED_HOME=/home/hadoop/hadoop-2.7. #set the path to where bin/hbase is available
#export HBASE_HOME=/home/hadoop/hbase #Set the path to where bin/hive is available
#export HIVE_HOME=/home/hadoop/hive #Set the path for where zookeper config dir is
#export ZOOCFGDIR=/home/hadoop/zookeeper
2.添加环境变量:
vi .bash_profile
export SQOOP_HOME=/home/hadoop/sqoop-1.4.
export PATH=$PATH:${SQOOP_HOME}/bin
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export CLASSPATH=$CLASSPATH:${SQOOP_HOME}/lib
使文件生效:
source .bash_profile
3.复制相关依赖包$SQOOP_HOME/lib
下载MySQL的依赖包
mysql-connector-java-5.1.46-bin.jar 点击打开链接
上传解压后,把mysql-connector-java-5.1.46-bin.jar 移动到/home/hadoop/sqoop-1.4.7/lib 下
cd /home/hadoop/hadoop-2.7.3/share/hadoop/common
cp hadoop-common-2.7.3.jar /home/hadoop/sqoop-1.4.7/lib/
4.修改$SQOOP_HOME/bin/configure-sqoop
注释掉HCatalog,Accumulo检查(除非你准备使用HCatalog,Accumulo等HADOOP上的组件)
## Moved to be a runtime check in sqoop.
#if [ ! -d "${HCAT_HOME}" ]; then
# echo "Warning: $HCAT_HOME does not exist! HCatalog jobs will fail."
# echo 'Please set $HCAT_HOME to the root of your HCatalog installation.'
#fi #if[ ! -d "${ACCUMULO_HOME}" ]; then
# echo "Warning: $ACCUMULO_HOME does notexist! Accumulo imports will fail."
# echo 'Please set $ACCUMULO_HOME to the rootof your Accumulo installation.'
#fi #Add HCatalog to dependency list
#if[ -e "${HCAT_HOME}/bin/hcat" ]; then
# TMP_SQOOP_CLASSPATH=${SQOOP_CLASSPATH}:`${HCAT_HOME}/bin/hcat-classpath`
# if [ -z "${HIVE_CONF_DIR}" ]; then
# TMP_SQOOP_CLASSPATH=${TMP_SQOOP_CLASSPATH}:${HIVE_CONF_DIR}
# fi
# SQOOP_CLASSPATH=${TMP_SQOOP_CLASSPATH}
#fi #Add Accumulo to dependency list
#if[ -e "$ACCUMULO_HOME/bin/accumulo" ]; then
# for jn in `$ACCUMULO_HOME/bin/accumuloclasspath | grep file:.*accumulo.*jar |cut -d':' -f2`; do
# SQOOP_CLASSPATH=$SQOOP_CLASSPATH:$jn
# done
# for jn in `$ACCUMULO_HOME/bin/accumuloclasspath | grep file:.*zookeeper.*jar |cut -d':' -f2`; do
# SQOOP_CLASSPATH=$SQOOP_CLASSPATH:$jn
# done
#fi
测试与mysql的连接
首先确保mysqld在运行:
[root@master ~]# service mysqld status
mysqld (pid 3052) is running...
然后测试是否连通:
[hadoop@master ~]$ sqoop list-databases --connect jdbc:mysql://127.0.0.1:3306/?useSSL=false --username root -P
19/02/18 17:38:32 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Enter password:
19/02/18 17:38:45 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
information_schema
hive
mysql
performance_schema
sys
输入密码后如果能显示你mysql上的数据库则表示已经连通。
<完>
sqoop 安装的更多相关文章
- 如何将mysql数据导入Hadoop之Sqoop安装
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle , ...
- Sqoop安装与应用过程
1. 参考说明 参考文档: http://sqoop.apache.org/ http://sqoop.apache.org/docs/1.99.7/admin/Installation.html ...
- sqoop安装部署(笔记)
sqoop是一个把关系型数据库数据抽向hadoop的工具.同时,也支持将hive.pig等查询的结果导入关系型数据库中存储.由于,笔者部署的hadoop版本是2.2.0,所以sqoop的版本是:sqo ...
- sqoop安装与简单实用
一,sqoop安装 1.解压源码包 2.配置环境变量 3.在bin目录下的 /bin/configsqoop 注释掉check报错信息 4.配置conf目录下 /conf/sqoop-env.sh 配 ...
- cdh版本的sqoop安装以及配置
sqoop安装需要提前安装好sqoop依赖:hadoop .hive.hbase.zookeeper hadoop安装步骤请访问:http://www.cnblogs.com/xningge/arti ...
- [Hadoop] Sqoop安装过程详解
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可 ...
- hadoop(八) - sqoop安装与使用
一. sqoop安装: 安装在一台节点上就能够了. 1. 使用winscp上传sqoop 2. 安装和配置 加入sqoop到环境变量 将数据库连接驱动mysql-connector-5.1.8.jar ...
- Sqoop 安装部署
1. 上传并解压 Sqoop 安装文件 将 sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz 安装包上传到 node-01 的 /root/ 目录下并将其解压 [root@no ...
- Sqoop安装及操作
一.集群环境: Hostname IP Hadoop版本 Hadoop 功能 系统 node1 192.168.1.151 0.20.0 namenode hive+sqoop rhel5.4X86 ...
随机推荐
- 一百零九:CMS系统之前端根据不同权限渲染不同菜单
给用户绑定为开发者 个人信息中渲染角色和权限 {% extends 'cms/cms_base.html' %} {% block title %} 个人信息{% endblock %} {% blo ...
- [ML] LIBSVM Data: Classification, Regression, and Multi-label
数据库下载:LIBSVM Data: Classification, Regression, and Multi-label 一.机器学习模型的参数 模型所需的参数格式,有些为:LabeledPoin ...
- Mysql——常用命令
查看版本:show variables like '%version%' 或者 select version() 是否开启binlog:show variables like 'log_bin ...
- Servlet(1):基础概念/最简实例
Servlet 生命周期(1) init()方法初始化Servlet对象 它在第一次创建Servlet时被调用,在后续每次不同用户请求时不再调用.(2) service()方法来处理客户端的请求 ...
- DS18b20温度传感器基础使用
认识管脚 认识唯一标示的64位地址序列号 寄存器数据译码成温度值(下面只针对12位转化的,还有9..10等其他位的转化方式,不同位的转化,其精度也不同) 传感器存储器 配置寄存器使用说明 DS18b2 ...
- 无监督异常检测之LSTM组成的AE
我本来就是处理时间序列异常检测的,之前用了全连接层以及CNN层组成的AE去拟合原始时间序列,发现效果不佳.当利用LSTM组成AE去拟合时间序列时发现,拟合的效果很好.但是,利用重构误差去做异常检测这条 ...
- TP5中用redis缓存
在config.php配置文件下找到缓存设置,将原来的文件缓存修改为redis缓存,也可以改为多种类型的缓存: // +---------------------------------------- ...
- [转帖]使用Gnome文件管理器连接到服务器:FTP/SFTP、Samba、NFS的方法
使用Gnome文件管理器连接到服务器:FTP/SFTP.Samba.NFS的方法 2019-05-09 16:28:44作者:雷增线稿源:云网牛站 https://ywnz.com/linuxyffq ...
- 关于mac配置vs code的C++环境问题
在配置完成后,编译通过了但是在终端输出一直不出现很奇怪,求问大家这是啥问题 以下是我的配置
- Linux-echo:打印彩色输出
脚本可以使用转义序列在终端中生成彩色文本 文本颜色是由对应的色彩码来描述的.其中包括: 重置=0,黑色=30,红色=31,绿色=32, 黄色=33,蓝色=34,洋红=35,青色=36,白色=37. 要 ...