数据分析 - pandas 模块
数据读取结构 - DataFrame
- Series (collection of values)
- DataFrame (collection of Series objects)
- Panel (collection of DataFrame objects)
DataFrame 可以理解为一个矩阵结构, 每一列都是一个 Series
简单得使用展示
一维

二维

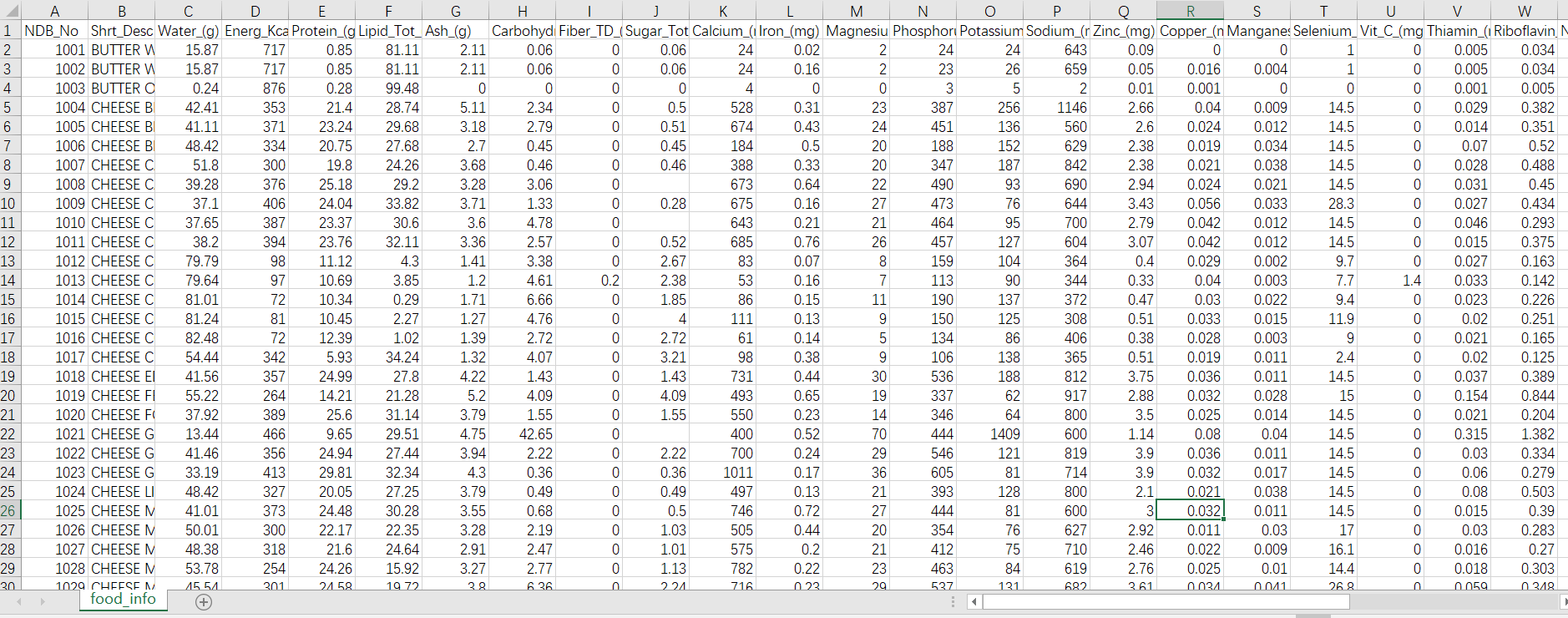
样本文件 food_info.csv
表示食品中的各种营养素指标
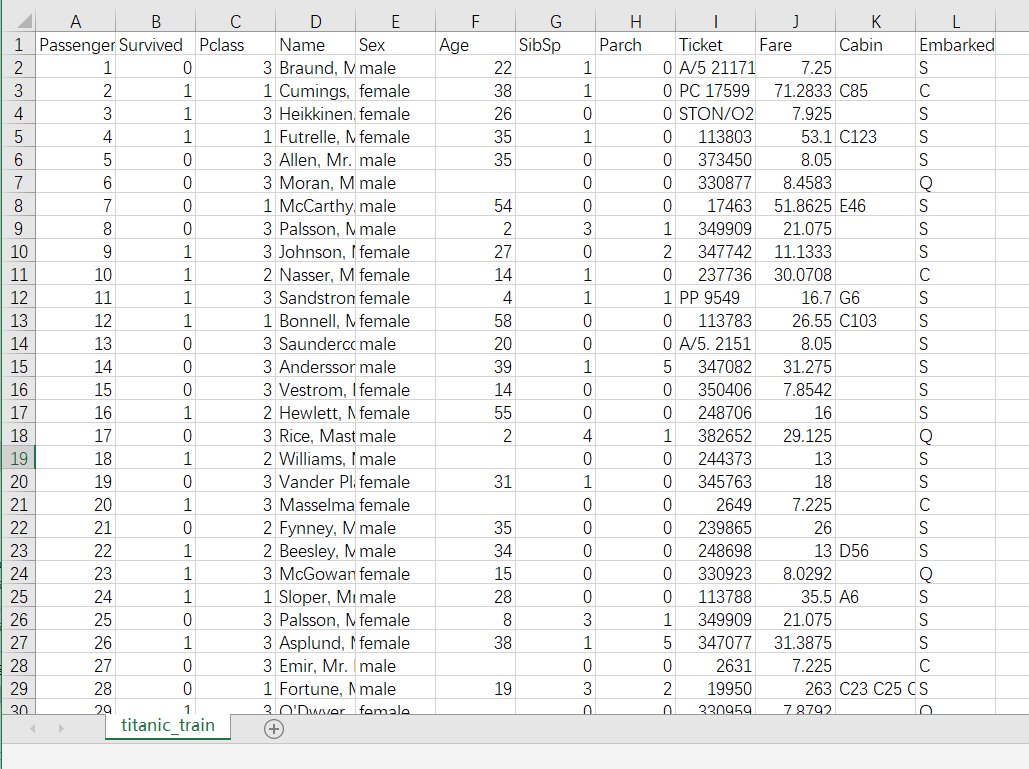
样本文件 titanic_train.csv
泰坦尼克号船员获救案例
属性
.dtypes 属性
查看 DataFrame 结构的内部数据类型
常见的属性值


此属性也可以作为方法使用
可以进行数据类型得更改, 但是更改必须要赋值才可以生效
直接使用仅仅是预览功能,而且如果此时赋值直接再本来都是 int 类型得里面加个 字符串是不会报错得, 而是将所有得类型自动转化成 object (字符串) 从而适配全部

.columns 属性
查看 DataFrame 的列名 (对应样本文件的每个营养素指标,得到一个 list 结构
也可以继续执行 .tolist() 方法返回一个列表


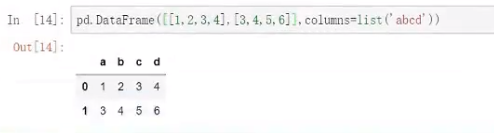
简单使用展示
.shape 属性
查看维度, 空间结构表示 (行, 列)
用于查看规模

操作方法
read_csv 方法
读取 csv 文件转为为 DataFrame 类型

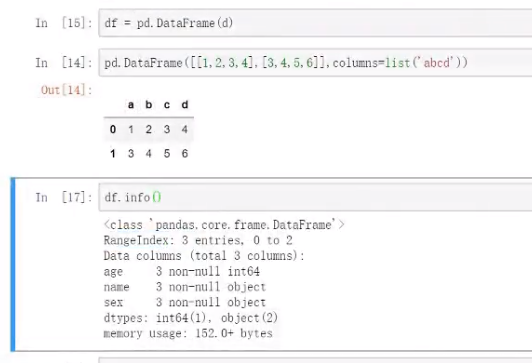
info 方法
查看信息预览
head 方法 / tail 方法
输出 头 / 尾 n 行数据
传入参数 count(int) 未指定时, 默认输出 5 行, 制定后输入指定行数
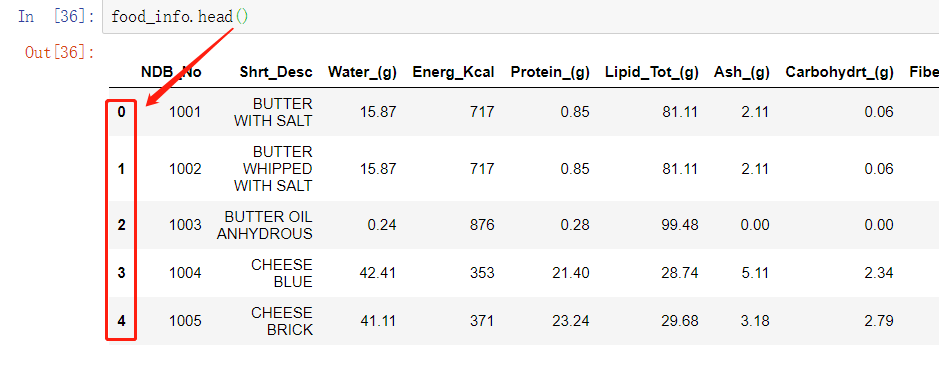

传给参数后会简化输出结果

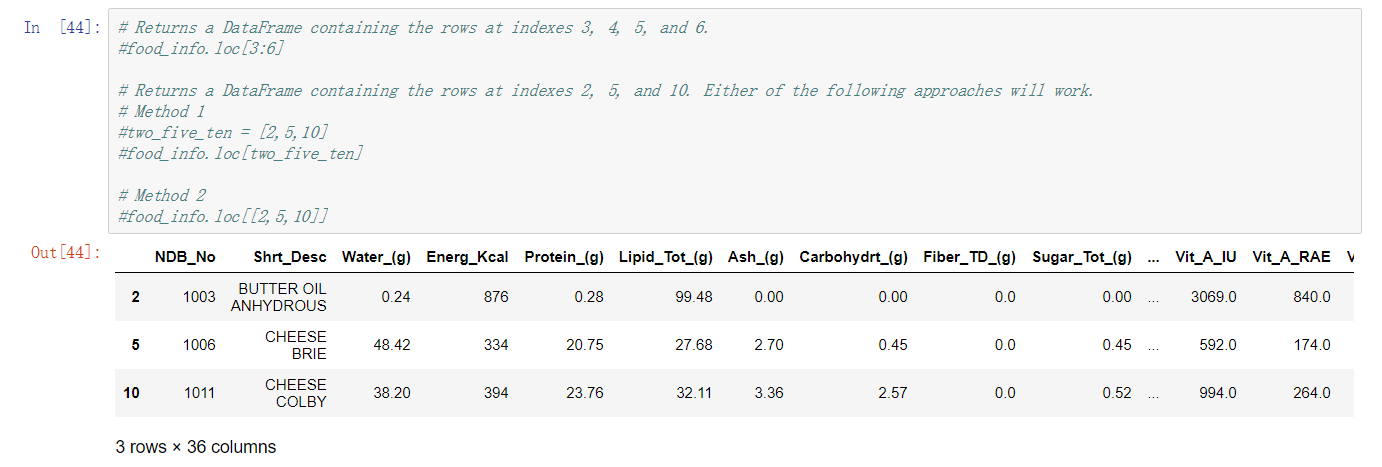
取行 - loc 方法
老版本貌似也可以使用 .ix 属性来取值, 用法是一样的, 但是会标红以及提示报错
指定索引取值, 此处不直接使用索引而是用 loc 方法再次封装了一下
传入参数为 索引号, 当然指定不存在的索引是会报错的

使用此方法也可以基于索引进行切片,
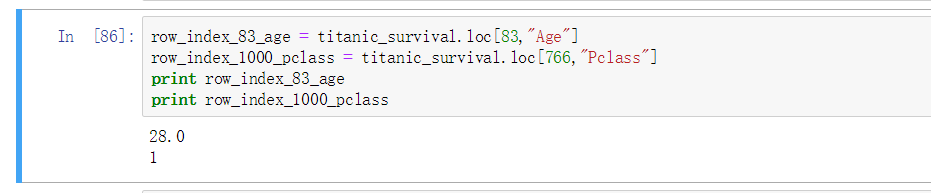
也可以直接定位到属性值而不是一行的样本, 格式如图, 先写行号在写属性名, 这样定位到一个值之后是可以直接赋值修改操作的
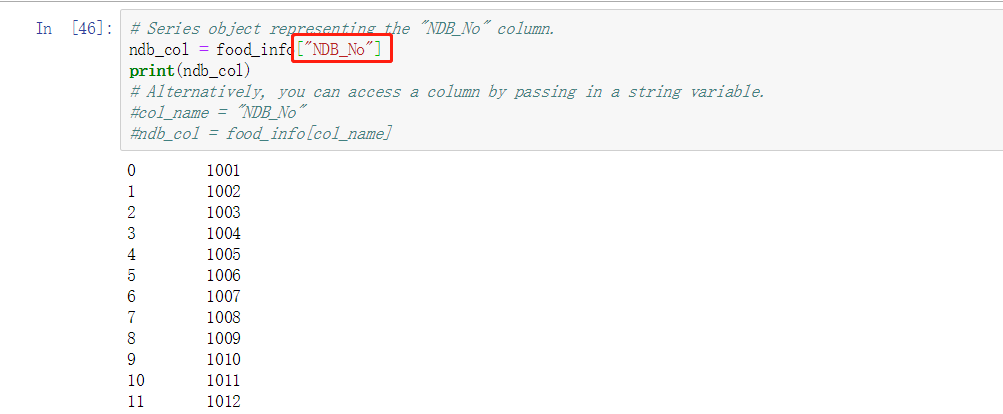
取列 - ["..."]
取列 按照字段字符串来取这一列的值, 想取多个列就传入多个值, 取索引列的话就用 .index 即可 , 索引列也可以进行修改赋值

赋值 直接对一列进行赋值操作会改变这一列的所有的值, 如果想赋值多个就传入列表即可,传入的如果数据不对其就报错超出索引
注意取多个列的时候要用 [] 再套一层

示例展示
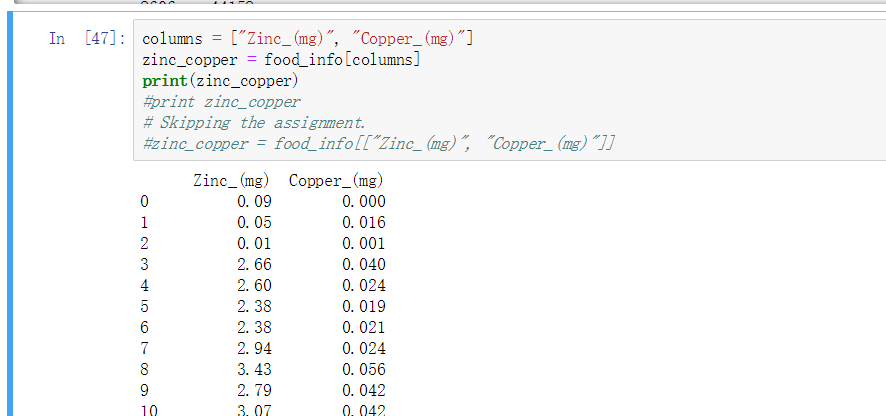
取列得时候也可以直接用 .列名 这样得类似属性得方式直接取出来, 但是这样得话容易于内置函数冲突
因此并不推荐, 更推荐使用 [...] 得形式更安全
运算
类似于 numpy 中的运算, 都是对一列全部的数据进行运算


如果运算值也是列. 则列之间如果数据对应(维度一样)的话则每行的多列进行运算
运算后的结果可以再保存进去, 但是必须要求维度一致

运算函数
取到列之后进行函数调用, 可以进行最大值 .max , 最小值 .min , 均值 .mean 等运算


排序操作 - sort_values
参数 :
列名,
inplace - 在原有基础上还是新拿出来
ascending - 升序, 默认是True表示升序, 把 NaN 放在最后面

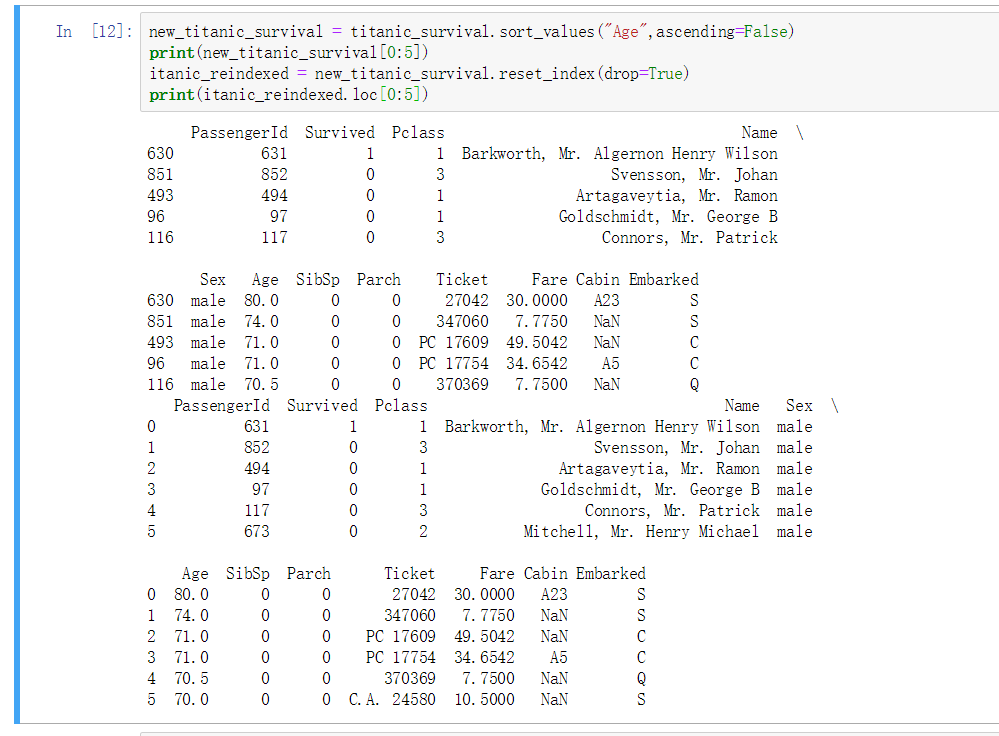
排序序号 - reset_index
使用 sort_values 后的指定的列排序成功了. 但是序号会按照之前的行号来处理. 看起来很不方便
使用 此函数进行 index 重新处理, 参数 drop 表示丢弃之前的序号
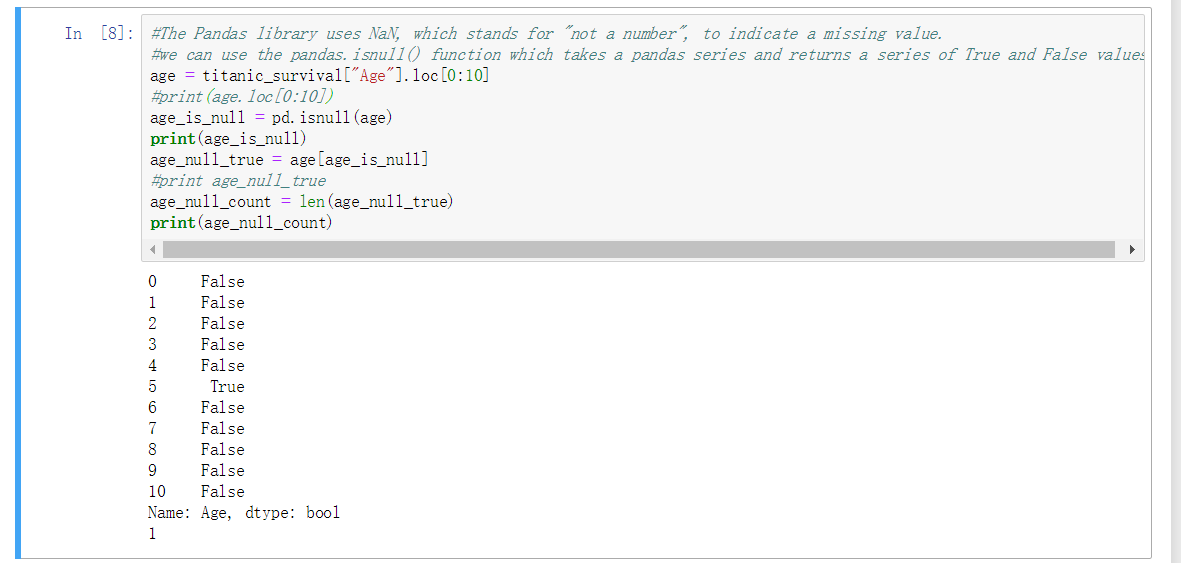
判断空值(缺失值) - isnull
pd.isnull( ) 传入一列, 进行判断空值输出 True/False 的列名映照序列
在 [] 中使用可以取出反向过滤非空值及行号, 也可以进行统计
丢弃指定值 - dropna
指定列的指定值进行丢弃
axis 指定丢弃值
subset 指定丢弃列

列关系运算 - pivot_table
正常思路按照 python 中的语法要进行比较繁琐的操作, 而 pandas 中进行了相应的封装
参数:
index 按照分类的列名, 基准, 不可以填入多个值
values 统计结果所用的变量, 可以填入多个值
aggfunc 统计结果的方式, 默认是 mean 均值方式
此处的案例: 求分析不同 Pclass (船舱等级) 的 Survived (获救人数) 的几率
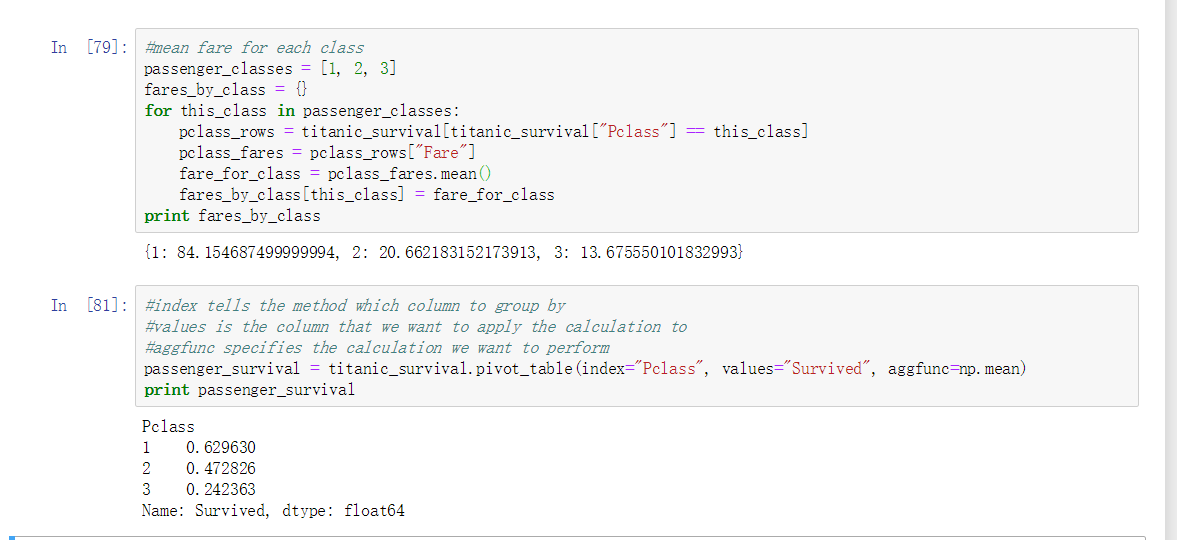
此处的案例: 求分析不同 Pclass (船舱等级) 的 Age (年龄) 的平均值
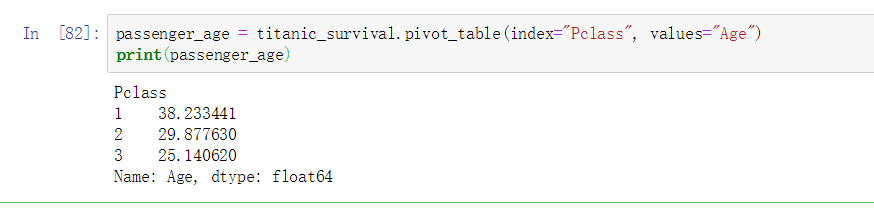
此处的案例: 求分析不同码头之间的船票价格以及获救与否之间的关系

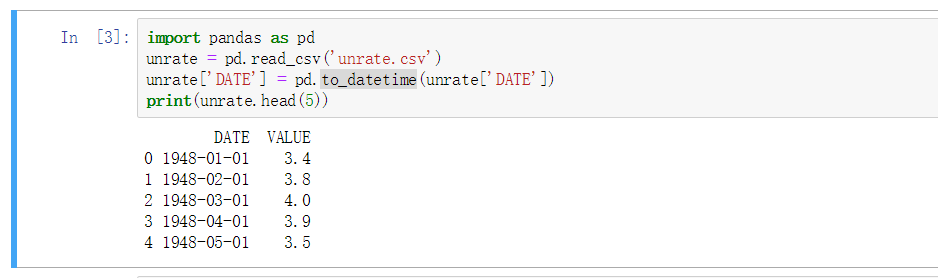
转换时间格式 - to_datetime
原有的时间格式是 1948/01/01 使用此函数可以转换为更标准时间格式
自定义函数 - apply
pandas 内置的函数不能满足自己的需求的时候可以自自定义函数来使用 apply 来进行调用处理
即再一次的封装使用更加方便
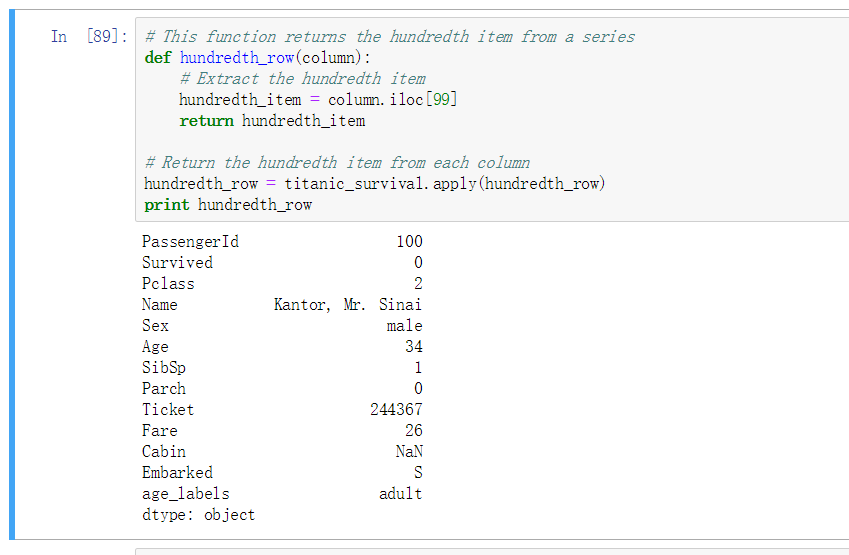
案例: 返回第100行数据
案例: 返回所有字段空值的计数

案例: 字段数据替换

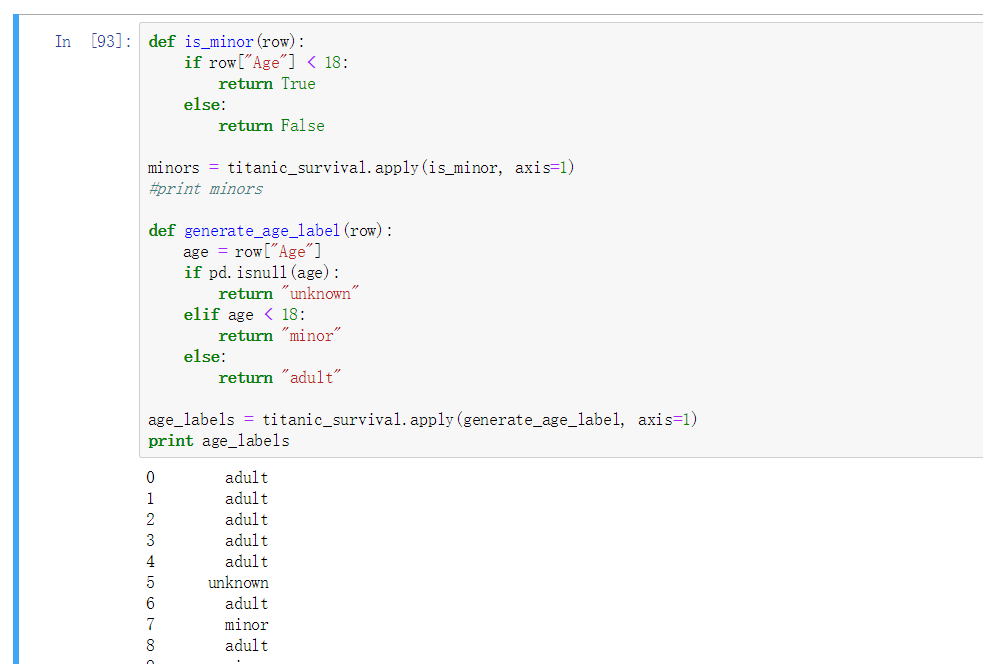
案例: 年龄判断
数据读取结构 - Series
DataFrame 中的每一列都是一个 Series

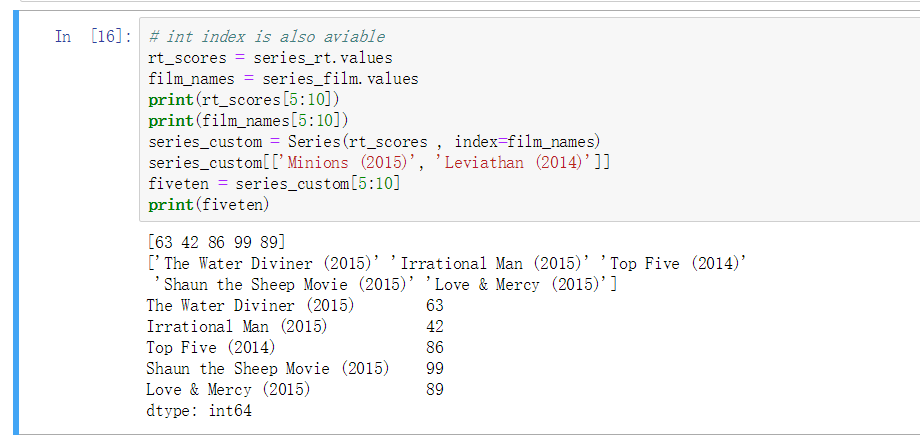
创建 Series
创建需要引入 Series 以及使用此类进行实例化
参数传递为 值以及 index 序号, index 可以设置为 字符串
通过 index 设置的字符串可以实现索引操作
属性
.index 查看创建索引
索引也可以设置为其他非数字

在创建的时候也可以指定索引值, 不一一对应也没关系会用 NaN 填充
[] 索引使用
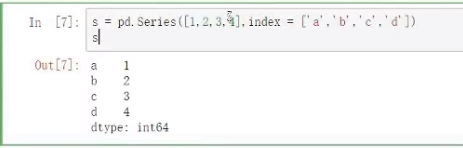
索引得使用和列表类似, 直接索引取值赋值新增加值都可以
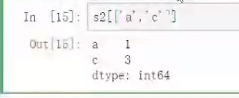
注意索引可以取多个值, 但是取多个值得时候一定要在[] 内, 然后外面再套一层 [] 才可以
而且如果此时赋值直接再本来都是 int 类型得里面加个 字符串是不会报错得,
而是将所有得类型自动转化成 object (字符串) 从而适配全部
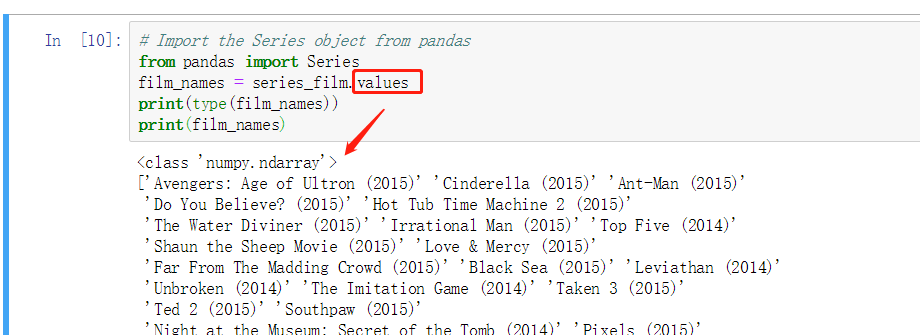
.values 查看所有值
类型本质为 ndarray
方法
排序
基本上很少用, 很少会对 Series 进行排序
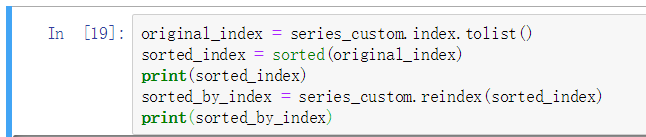

运算
相同维度的 Series 彼此可以直接运算

数据分析 - pandas 模块的更多相关文章
- Python数据分析 Pandas模块 基础数据结构与简介(一)
pandas 入门 简介 pandas 组成 = 数据面板 + 数据分析工具 poandas 把数组分为3类 一维矩阵:Series 把ndarray强大在可以存储任意数据类型可以专门处理时间数据 二 ...
- Python数据分析 Pandas模块 基础数据结构与简介(二)
重点方法 分组:groupby('列名') groupby(['列1'],['列2'........]) 分组步骤: (spiltting)拆分 按照一些规则将数据分为不同的组 (Applying)申 ...
- Pandas模块:表计算与数据分析
目录 Pandas之Series Pandas之DataFrame 一.pandas简单介绍 1.pandas是一个强大的Python数据分析的工具包.2.pandas是基于NumPy构建的. 3.p ...
- Python 数据处理扩展包: numpy 和 pandas 模块介绍
一.numpy模块 NumPy(Numeric Python)模块是Python的一种开源的数值计算扩展.这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list str ...
- 关于Python pandas模块输出每行中间省略号问题
关于Python数据分析中pandas模块在输出的时候,每行的中间会有省略号出现,和行与行中间的省略号....问题,其他的站点(百度)中的大部分都是瞎写,根本就是复制黏贴以前的版本,你要想知道其他问题 ...
- Pandas模块
前言: 最近公司有数据分析的任务,如果使用Python做数据分析,那么对Pandas模块的学习是必不可少的: 本篇文章基于Pandas 0.20.0版本 话不多说社会你根哥!开干! pip insta ...
- python 数据分析--pandas
接下来pandas介绍中将学习到如下8块内容:1.数据结构简介:DataFrame和Series2.数据索引index3.利用pandas查询数据4.利用pandas的DataFrames进行统计分析 ...
- Python数据分析--Pandas知识点(二)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘. Python数据分析--Pandas知识点(一) 下面将是在知识点一的基础上继续总结. 13. 简单计算 新建一个数据表 ...
- 4 pandas模块,Series类
对gtx图像进行操作,使用numpy知识 如果让gtx这张图片在竖直方向上进行颠倒. 如果让gtx这张图片左右颠倒呢? 如果水平和竖直方向都要颠倒呢? 如果需要将gtx的颜色改变一下呢 ...
随机推荐
- C++中volatile
volatile只保证其“可见性”,不保证其“原子性”. 执行count++;这条语句由3条指令组成: (1)将 count 的值从内存加载到 cpu 的某个 寄存器r: (2)将 寄存器r 的值 + ...
- Windows下Pycharm安装Tensorflow:ERROR: Could not find a version that satisfies the requirement tensorflow
今天在Windows下通过Pycharm安装Tensorflow时遇到两个问题: 使用pip安装其实原理都相同,只不过Pycharm是图形化的过程! 1.由于使用国外源总是导致Timeout 解决方法 ...
- kubernetes之pod调度
调度规则 deployment全自动调度: 运行在哪个节点上完全由master的scheduler经过一系列的算法计算得出, 用户无法进行干预 nodeselector定向调度: 指定pod调度到一些 ...
- (转)为什么收到三个重复的ACK意味着发生拥塞?
三次重复的ACK,可能是丢包引起的,丢包可能是网络拥塞造成的,也可能是信号失真造成的. 三次重复的ACK,也有可能是乱序引起的,而乱序和网络拥塞没有直接关系. 如果就写这两行,感觉什么都没写,接下来的 ...
- iphone bandwidth
iPhone 8, 8 Plus, X peak throughput of ~24GBs iPhone XS, XS Max, XR peak throughput of ~34GBs 在iphon ...
- 对List<Map>里的map的某个属性重复的值进行处理的方法
package test; import java.util.*;import java.util.stream.Collectors; public class Test5 { public sta ...
- sql server 安装
第一次安装sql server是2016版本,因为[win7-64版系统配置比较低],所以不成功. 第二次安装2012版,在[数据库引擎配置]的时候,选择的是[添加当前用户],以及后续需要添加用户的时 ...
- 利用swoole coroutine协程实现redis异步操作
<?php #注意:如果不开启兼容模式,会遇到这样的现象,用swoole协程的方法访问常规方法添加到redis中的数据,可能访问不到(直接返回NULL)!这可能是两者采用了不同的技术标准所致! ...
- Python 练习实例1
Python 练习实例1 题目:有四个数字:1.2.3.4,能组成多少个互不相https://www.xuanhe.net/同且无重复数字的三位数?各是多少? 程序分析:可填在百位.十位.个位的数字都 ...
- Luogu P4109 [HEOI2015]定价 贪心
思路:找规律?$or$贪心. 提交:1次 题解: 发现:若可以构成$X0000$,答案绝对不会再在数字最后把$0$改成其他数: 若可以构成$XX50...0$更优. 所以左端点增加的步长是增加的($i ...