mysql数据库索引和引擎
1. 数据库索引
1.1 索引作用
当我们在数据库表中查询数据时,若没有索引,会逐个遍历表格中的所有记录,表格中数据记录量大时很耗时。建立索引就像创建目录一样,直接通过索引找到数据存储位置,加快查找。例如:有一张person表,其中有2W条记录,记录着2W个人的信息。有一个Phone的字段记录每个人的电话号码,现在想要查询出电话号码为xxxx的人的信息。
如果没有索引,那么将从表中第一条记录一条条往下遍历,直到找到该条信息为止。
如果有了索引,那么会将该Phone字段,通过一定的方法进行存储,好让查询该字段上的信息时,能够快速找到对应的数据,而不必在遍历2W条数据了。其中MySQL中的索引的存储类型有两种:BTREE、HASH。 也就是用树或者Hash值来存储该字段,要知道其中详细是如何查找的,就需要会算法的知识了。
但索引也不是越多越好,因为创建的索引也需要占用空间,而且需要维护索引,因此没必要为所有字段创建索引,对于经常需要查询,或数据记录很多的字段可以创建索引。
1.2 索引分类(index或key)
索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引
MyISAM和InnoDB存储引擎:只支持BTREE索引, 也就是说默认使用BTREE,不能够更换
MEMORY/HEAP存储引擎:支持HASH和BTREE索引
索引我们分为四类来讲 单列索引(普通索引,唯一索引,主键索引)、组合索引、全文索引、空间索引、
单列索引:一个索引只包含单个列,但一个表中可以有多个单列索引。
普通索引, INDEX:MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点。
唯一索引,UNIQUE :索引列中的值必须是唯一的,但是允许为空值,
主键索引, PRIMARY KEY:是一种特殊的唯一索引,不允许有空值。
组合索引: 在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀集合。
全文索引 FULLTEXT :只有在MyISAM引擎上才能使用 (MySQL 5.6版本的InnoDB 开始支持全文索引),只能在CHAR,VARCHAR,TEXT类型字段上使用全文索引,介绍了要求,说说什么是全文索引,就是在一堆文字中,通过其中的某个关键字等,就能找到该字段所属的记录行.
空间索引 SPATIAL : 只有在MyISAM引擎上才能使用(MySQL 5.7版本的InnoDB 开始支持),空间索引是对空间数据类型(坐标,地理位置等)的字段建立的索引,MySQL中的空间数据类型有四种,GEOMETRY、POINT、LINESTRING、POLYGON。创建空间索引的列,必须将其声明为NOT NULL
另外索引也可以分为聚集索引和非聚集索引:
聚集(clustered)索引:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。(即主键索引)
非聚集索引(辅助索引):该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。(包括普通索引,唯一索引,全文索引等)
1.3 索引操作
1.3.1 创建索引(create index): (创建索引后,通过SHOW CREATE TABLE tbname;能查看)
下面命令给titles表中的title列增加索引 (索引名称为idxtitle,未命名时默认为该字段名称),有三种方式如下:
1,创建表格时指定:
CREATE TABLE titles(
title varchar(100),
publID INT,
INDEX idxtitle (title)
);
2,创建索引: CREATE INDEX idxtitle ON titles(title);
3,修改表设计,添加索引: ALTER TABLE titles ADD INDEX idxtitle (title);
1.3.2增加不同的索引:
ALTER TABLE tablename ADD PRIMARY KEY (indexcols..); 不要写索引名称
ALTER TABLE tablename ADD INDEX [indexname] (indexcols..);
ALTER TABLE tablename ADD UNIQUE [indexname] (indexcols..);
ALTER TABLE tablename ADD FULLTEXT [indexname] (indexcols..);
ALTER TABLE tablename ADD INDEX [indexname] (indexcols1,indexcols2); 为indexcols1,indexcols2两列创建组合索引
1.3.3删除索引:
ALTER TABLE tablename DROP PRIMARY KEY ;
ALTER TABLE tablename DROP INDEX [indexname] ;
DROP indexname ON table_name;
1.3.4查看索引:
SHOW INDEX FROM table_name;
SHOW CREATE TABLE table_name;
DESC table_name
1.3.5 索引创建示例:
普通索引:加速查找功能 创建表时定义索引
CREATE TABLE user(
nid INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR() NOT NULL,
age INT NOT NULL,
email VARCHAR() NOT NULL,
index n_index (name)
)ENGINE=INNODB DEFAULT CHARSET=utf8; 创建表后添加索引
CREATE INDEX a_index ON user(age);
查看索引
SHOW INDEX FROM user;
删除索引
DROP INDEX a_index ON user; 注意:对于创建索引时如果是BLOB 和 TEXT 类型,必须指定length。
create index ix_extra on in1(extra()); .唯一索引功能:加速查找和唯一约束(可以为null)
CREATE TABLE user(
nid INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR() NOT NULL,
age INT NOT NULL,
email VARCHAR() NOT NULL,
UNIQUE n_index (name)
)ENGINE=INNODB DEFAULT CHARSET=utf8; CREATE INDEX a_index ON user(age); SHOW INDEX FROM user; DROP INDEX a_index ON user; . 主键索引功能:加速查找和唯一约束(不可为null),特殊的唯一索引
-- CREATE TABLE user(
-- nid INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
-- name VARCHAR() NOT NULL,
-- age INT NOT NULL,
-- email VARCHAR() NOT NULL,
-- )ENGINE=INNODB DEFAULT CHARSET=utf8;
-- 方式二
CREATE TABLE user(
nid INT NOT NULL AUTO_INCREMENT,
name VARCHAR() NOT NULL,
age INT NOT NULL,
email VARCHAR() NOT NULL,
PRIMARY key (nid)
)ENGINE=INNODB DEFAULT CHARSET=utf8; -- 创建和删除
ALTER TABLE user ADD PRIMARY KEY(name);
ALTER TABLE user DROP PRIMARY KEY;
ALTER TABLE user MODIFY nid INT,DROP PRIMARY KEY; .组合索引:组合索引是将n个列组合成一个索引
其应用场景为:频繁的同时使用n列来进行查询,如:where name = 'zack' and password = "" CREATE INDEX com_index ON user(name,age);
组合索引有最左前缀性,对于上述组合索引,查询时:
查询:
name and email -- 使用索引
name -- 使用索引
email -- 不使用索引
注意:对于同时搜索n个条件时,组合索引的性能好于多个单一索引合并。
四种索引操作示例
1.4 索引性能测试:
先创建person表格,通过存储过程插入5000条数据
--创建表 CREATE TABLE person(id INT, name VARCHAR()); --存储过程 (创建函数,delimiter $$:修改终止符号为$$) delimiter $$ CREATE PROCEDURE autoinsert()
BEGIN
DECLARE i INT DEFAULT ;
WHILE(i<) DO
INSERT INTO person VALUES(i,'zack');
SET i=i+;
END WHILE;
END$$ delimiter ; --调用函数 CALL autoinsert();
创建person表
无index时查询:SELECT * FROM person WHERE id=4900;
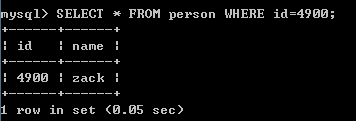
添加index后查询:
ALTER TABLE person ADD INDEX index_id (id);
SELECT * FROM person WHERE id=4900;
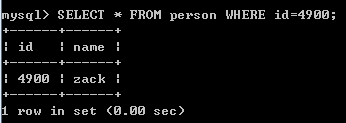
可以看出有索引时查询时间变快。
1.5.索引覆盖
索引覆盖:建立索引后并不是所有的查询都会通过索引表查询,通过索引表的查询称为索引覆盖。
常见的不会覆盖索引的情况:(通过explain语句分析,可以判断是否覆盖索引,但只是作为参考)
CREATE TABLE user(
nid INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR() NOT NULL,
age INT NOT NULL,
email VARCHAR() NOT NULL,
index n_index(name)
)ENGINE=INNODB DEFAULT CHARSET=utf8; show index from user;
name列为普通索引,id列为主键索引 不会覆盖索引的情况:
.以%开头的模糊查询:like "%cn"
select * from user where name like '%cn'; . 使用函数:
select * from user where reverse(name) = 'zack'; .OR语句中有一列不是索引列
select * from user where id = or email = '6734@qq.com';
下列特殊情况:
select * from user where id = or email = '6734@qq.com' and name = 'zack' . 类型不一致
(下面name列是字符串类型,传入条件时必须用引号引起来,不然不会走索引)
select * from user where name = ; . 使用了!=
select * from user where name != 'zack';
特别的:如果是主键,则还是会走索引
select * from user where id != ; . 使用了>,< (有可能覆盖索引,不同版本不一致)
select * from user where name > 'zack';
特别的:如果是主键或索引是整数类型,则还是会走索引
select * from user where id > ;
select * from user where age > ; . ORDER BY 语句根据索引列排序,选择的映射如果不是索引,则不走索引
select email from user order by name desc;
下面会走索引:select name from user order by name desc;
特别的:如果对主键排序,则还是走索引:
select * from user order by id desc; .组合索引最左前缀原理
如果组合索引为:(name,email)
name and email -- 使用索引
name -- 使用索引
email -- 不使用索引
覆盖索引
1.6 索引数据结构
(参考:http://blog.codinglabs.org/articles/theory-of-mysql-index.html)
一般索引采用B+ Tree和B- Tree实现,MySQL的InnoDB和MyISAM都采用B+ Tree实现,但存储细节上不一样。
MyISAM存储引擎:MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址(叶节点data域)。
主键索引(primary key):其结构如下,B+ Tree的叶子节点的key存放主键值,data存放主键值对应数据行的存储地址,而非叶子节点key为主键值,不存储data。查找时通过key从上往下找到叶子结点,如果key存在,拿到数据行存储地址。
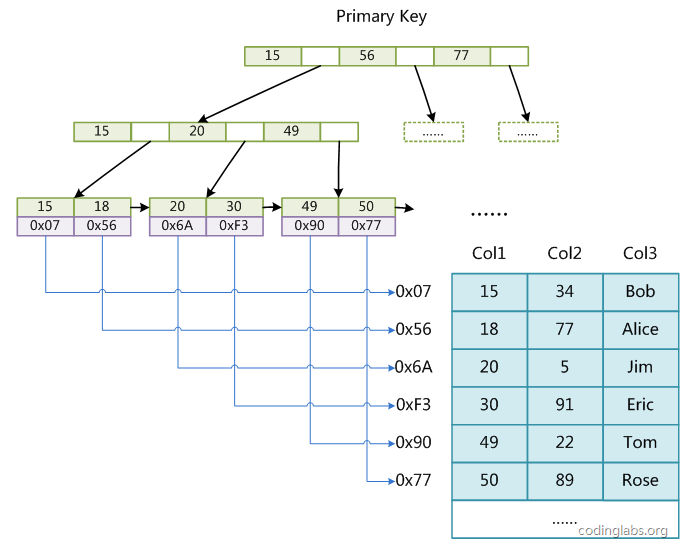
辅助索引(secondary key):上图中col1为主键,在col2上建立一个辅助索引,其结构如下,可以发现其结构和主键索引没有区别,叶子节点data存放的也是数据行地址(不同之处在于主索引要求key是唯一的,而辅助索引的key可以重复)
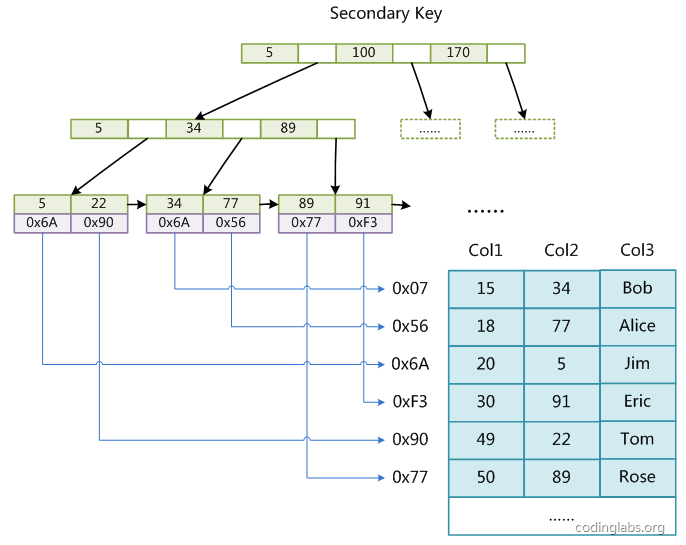
InnoDB存储引擎:InnoDB的数据文件本身就是索引文件,叶节点data域保存了完整的数据记录
主键索引:其结构如下,B+ Tree的叶子节点key存放主键值,data存放完整的数据记录。非叶子节点key为主键值,不存储data。查找时通过key从上往下找到叶子结点,如果key存在,直接拿到数据。
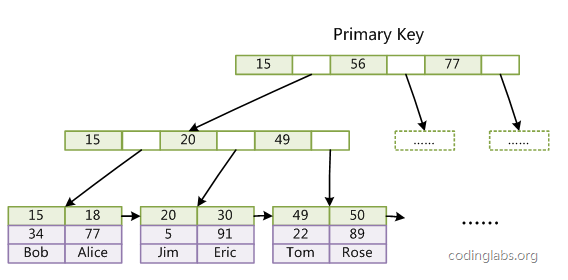
辅助索引:对于辅助索引的结构如下,与主键索引不同的是,叶节点的data存放存放主键索引的值,而不是地址,因此辅助索引进行检索时需要检索两遍索引,首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
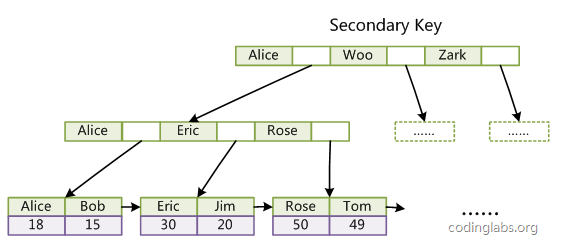
通过上述结构发现,InnoDB数据文件即包含主键索引,所以InnoDB要求表必须有主键,如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键。而且不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。另外,用非单调的字段作为主键在InnoDB中也不建议,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
2,mysql数据库引擎
https://dev.mysql.com/doc/refman/5.7/en/storage-engines.html
数据库存储引擎,是mysql用来处理SQL语句的组件,对每一个数据表格,创建时都需要指定一个数据库引擎,mysql会使用该引擎来处理这个表格的相应操作,因此对于不同引擎的表格,SQL语句的处理结果和性能会不同。另外,对于一个数据库中的表格,每个表格都可以指定不同的数据库引擎。通过命令SHOW ENGINES;能查看mysql支持的数据库引擎。主要有InnoDB,MyISAM, Memory, CSV, Archve, Blackhole等,常用的就是InnoDB,MyISAM, Memory。其中通过Create table 命令默认设置的引擎为InnoDB。
2.1 设置数据表格引擎:
创建表格时指定:CREATE TABLE titles(id INT, name VARCHAR(16)) ENGINE = InnoDB;
创建后修改:ALTER TABLE titles ENGINE = InnoDB;
(SET default_storage_engine=NDBCLUSTER; 设置默认的引擎)
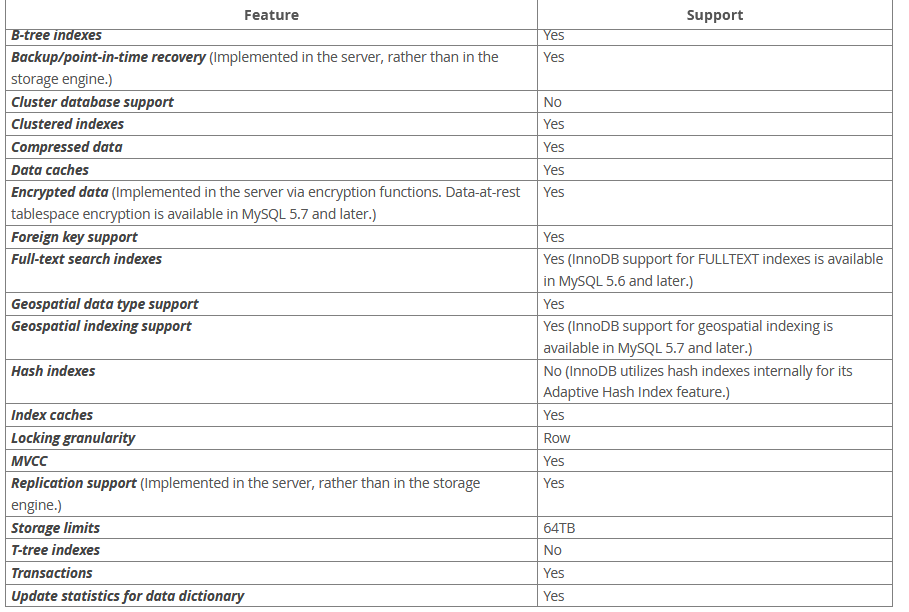
2.2 InnoDB特点
https://dev.mysql.com/doc/refman/5.7/en/innodb-introduction.html
InnoDB支持事务操作,即commit,rollback和crash-recovery;
InnoDB支持行级锁,即可以给一行数据上锁;
InnoDB支持外键关系约束;
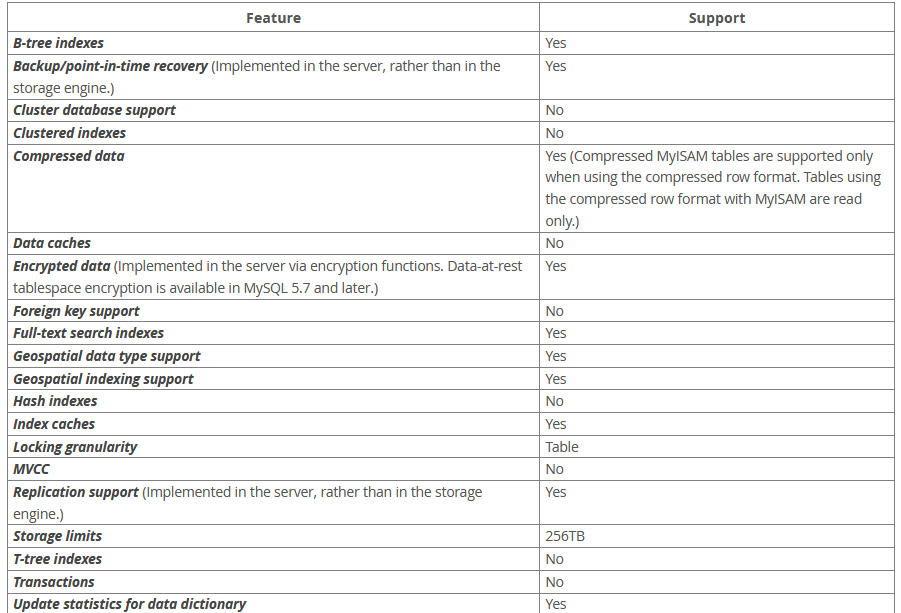
2.3 MyISAM特点
https://dev.mysql.com/doc/refman/5.7/en/myisam-storage-engine.html
MyISAM 适合读取操作较多的数据表,其读取速度较快;
MyISAM支持表级锁,可以给一张表上锁;
MyISAM支持全文索引;
MyISAM 支持Gometry,Point等表示空间位置的数据类型;
2.3 Memory:仅存在于内存中,多用于临时表格(hash index)
3.ODBC和JDBC
ODBC(open database connectivity): windows系统中数据库系统的一个驱动,基于ODBC的软件能够通过ODBC驱动来操控数据库中的数据。(如excel, access 能够通过ODBC连接MySQL 数据库,进行数据的增删改查
JDBC (java database connectivity):unix和Linux系统上数据库系统的驱动。
参考博客:https://www.cnblogs.com/whgk/p/6179612.html
http://www.cnblogs.com/yuanchenqi/articles/6357507.html
MyISAM和InnoDB的区别:https://segmentfault.com/a/1190000008227211
聚集索引与非聚集索引:https://www.cnblogs.com/s-b-b/p/8334593.html
mysql数据库索引和引擎的更多相关文章
- MySQL数据库InnoDB存储引擎多版本控制(MVCC)实现原理分析
文/何登成 导读: 来自网易研究院的MySQL内核技术研究人何登成,把MySQL数据库InnoDB存储引擎的多版本控制(简称:MVCC)实现原理,做了深入的研究与详细的文字图表分析,方便大家理解I ...
- MySQL数据库InnoDB存储引擎中的锁机制
MySQL数据库InnoDB存储引擎中的锁机制 http://www.uml.org.cn/sjjm/201205302.asp 00 – 基本概念 当并发事务同时访问一个资源的时候,有可能 ...
- (转)MySql数据库索引原理(总结性)
本文引用文章如链接: http://www.codinglabs.org/html/theory-of-mysql-index.html#more-100 参考书籍:Mysql技术内幕 本文主要是阐述 ...
- 第二百八十八节,MySQL数据库-索引、limit分页、执行计划、慢日志查询
MySQL数据库-索引.limit分页.执行计划.慢日志查询 索引,是数据库中专门用于帮助用户快速查询数据的一种数据结构.类似于字典中的目录,查找字典内容时可以根据目录查找到数据的存放位置,然后直接获 ...
- MySQL数据库索引常见问题
笔者看过很多数据库相关方面的面试题,但大多数答案都不太准确,因此决定在自己blog进行一个总结. Q1:数据库有哪些索引?优缺点是什么? 1.B树索引:大多数数据库采用的索引(innoDB采用的是b+ ...
- MySQL数据库索引的4大类型以及相关的索引创建
以下的文章主要介绍的是MySQL数据库索引类型,其中包括普通索引,唯一索引,主键索引与主键索引,以及对这些索引的实际应用或是创建有一个详细介绍,以下就是文章的主要内容描述. (1)普通索引 这是最基本 ...
- 知识点:Mysql 数据库索引优化实战(4)
知识点:Mysql 索引原理完全手册(1) 知识点:Mysql 索引原理完全手册(2) 知识点:Mysql 索引优化实战(3) 知识点:Mysql 数据库索引优化实战(4) 一:插入订单 业务逻辑:插 ...
- 为什么MySQL数据库索引选择使用B+树?
在进一步分析为什么MySQL数据库索引选择使用B+树之前,我相信很多小伙伴对数据结构中的树还是有些许模糊的,因此我们由浅入深一步步探讨树的演进过程,在一步步引出B树以及为什么MySQL数据库索引选择使 ...
- MySQL数据库索引之B+树
一.B+树是什么 B+ 树是一种树型数据结构,通常用于数据库和操作系统的文件系统中.B+ 树的特点是能够保持数据稳定有序,其插入与修改操作拥有较稳定的对数时间复杂度.B+ 树元素自底向上插入,这与二叉 ...
随机推荐
- Android项目笔记整理(1)
第二部分 工作项目中以及平时看视频.看书或者看博客时整理的个人觉得挺有用的笔记 1.Activity界面切换: if(条件1){ setContentView(R.layout.ma ...
- Maven 依赖的作用域
Maven的一个哲学是惯例优于配置(Convention Over Configuration), Maven默认的依赖配置项中,scope的默认值是compile,项目中经常傻傻的分不清,直接默认了 ...
- JavaScript捕获和冒泡探讨
<div id="div"> <input type="button" value="banana" id="b ...
- 牛客第十场 F.Popping Balloons
第一维直接遍历 第二维用线段树维护每个最左端可以得到的贡献 在线段树上每次删除一个点会影响到 X X-R X-2*R 3个值 最多操作1e5次 复杂度 6*n*logn(删了还要加回来 #i ...
- iframe通信相关:父操作子,子操作父,兄弟通信
这里写window和document是认为代表了BOM和DOM(个人理解不一定对) 拿到了window就能操作全局变量和函数 拿到了document就能获取dom,操作节点 父操作子 window:选 ...
- 模块化开发之Amd规范和Cmd规范
CMD规范:是SeaJS 在推广过程中对模块定义的规范化产出的. AMD规范:是 RequireJS 在推广过程中对模块定义的规范化产出的 // CMD define(function(require ...
- centos6 mini安装图形界面,并vnc远程控制
1.安装图形界面sudo yum groupinstall basic-desktop desktop-platform x11 fonts 2.安装vnc服务sudo yum -y install ...
- Java笔记(第五篇)
抛出异常 使用throws声明抛出异常 Throws 通常用于方法声明,当方法中可能存在异常,却不想在方法中对异常进行处理时,就可以在声明方法时使用throws声明抛出的异常,然后再调用该方法的其他方 ...
- setup elk with docker-compose
version: '2' services: elasticsearch: image: docker.calix.local:18080/docker-elasticsearch:6.2.2-1 c ...
- python 中的匿名函数lamda和functools模块
为什么 要把匿名函数和functools模块写在一起? 因为 lamda函数和functools模块都是对函数一种增强或者是简化. 匿名函数: 为了解决那些功能很简单的需求而设计一次性的需求函数 #& ...