SIGAI深度学习第一集 机器学习与数学基础知识
SIGAI深度学习课程:
本课程全面、系统、深入的讲解深度学习技术。包括深度学习算法的起源与发展历史,自动编码器,受限玻尔兹曼机,卷积神经网络,循环神经网络,生成对抗网络,深度强化学习,以及各种算法的应用。通过精心设计的实践项目,让你深刻理解算法的原理,真实学会算法的使用。
本讲:
讲授机器学习中的基本概念和算法、分类,以及微积分、线性代数、概率论、最优化方法等数学基础知识
机器学习简介:
特征向量
目标函数
机器学习分类:
有监督学习:分类问题(如人脸识别、字符识别、语音识别)、回归问题
无监督学习:聚类问题、数据降维
强化学习:根据当前状态预测下一个状态,回报最大化,回报具有延迟性,如无人驾驶、下围棋
深度学习数学知识:微积分、线性代数、概率论、最优化方法
一元函数微积分:
一元函数的泰勒展开:多项式近似代替函数
一定是在某一点附近做泰勒展开的
一元微分学:导数、泰勒展开、极值叛变法则。
多元函数微积分:
偏导数:其他变量当做常量,对其中一个变量求导数。
高阶偏导数:一般情况下,混合二阶偏导数与求导次序无关。
梯度:多元函数对各自变量的一阶偏导数构成的向量。
多元函数的泰勒展开
线性代数:
向量:n维空间的一个点。数学常为列向量,而在编程中常为行向量(按行优先存储)
向量的运算:加法、数乘、减法、内积、转置、向量的范数(将向量映射成一个非负的实数)
向量的范数:L-p范数分量绝对值的p次方求和再开p次方。L1范数:分量绝对值求和。L2范数:向量的长度/模。
矩阵:就是二维数组。矩阵的逆;矩阵的特征值;矩阵的二次型。
张量:相当于编程语言中的多维数组,n阶张量。
矩阵是2阶张量,向量是1阶张量。例如RGB彩色图像就是3阶张量。
雅克比矩阵:为所有因变量对所有自变量的偏导数构成的矩阵,雅克比矩阵的每一行为一个多元函数的梯度。

Hessian矩阵:多元函数的二阶偏导数构成的矩阵,是一个对称矩阵,相当于一元函数的二阶导数。
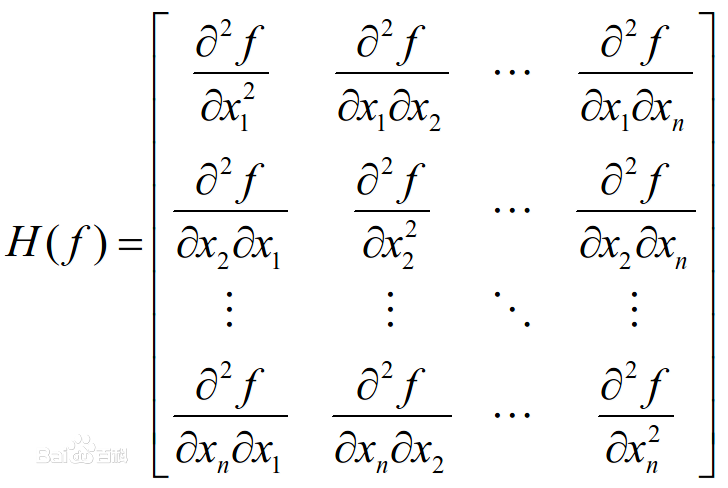
多元函数的极值判别法则:Hessian矩阵作用相当于f''(x)
如果Hessian矩阵正定,函数在该点有极小值;如果Hessian矩阵负定,函数在该点有极大值;如果Hessian矩阵不定,则为鞍点,不是极值点。
矩阵正定的定义:x[T]Ax>0
矩阵正定的判别法则:矩阵的特征值全大于0,矩阵的所有顺序主子式都大于0,矩阵合同于单位阵。
矩阵与向量求导:
wTx对x的梯度=w
xTAx对x的梯度=(A+AT)x
xTAx对x的Hessian算子(Hessian矩阵)=A+AT
概率论:
随机事件,随机事件的概率
条件概率:
p(a,b)=p(b|a)*p(a) p(a,b)=p(a|b)*p(b) =>p(b|a)*p(a)=p(a|b)*p(b)
贝叶斯公式:
将上式两边除以p(b)得到:p(a|b)=p(a)*p(b|a)/p(b) 将a看做因,将b看做果,那么p(b|a)称为先验概率,p(a|b)称为后验概率,贝叶斯公式就是建立在先验概率和后验概率之间的关系。
随机事件的独立性p(a,b,c)=p(a)p(b)p(c)
随机变量:
随机事件量化后的一个变量,取每个值关联一个概率值的变量。
离散型随机变量:
取值只有有限种情况,或者无限种可列情况(如0到正无穷的所有整数为无限可列,而0到1的所有实数为无限不可列)。描述离散型随机变量的概率分布:p(x=xi)≥0,∑p(x=xi)=1.
连续型随机变量:
取值为无限不可列种情况,即一个区间内的实数。描述连续型随机变量的是概率密度函数和分布函数,概率密度函数要满足:f(x)≥0,∫f(x)dx=1;分布函数定义为F(y)=p(x≤y)=∫f(x)dx
SIGAI深度学习第一集 机器学习与数学基础知识的更多相关文章
- SIGAI深度学习第二集 人工神经网络1
讲授神经网络的思想起源.神经元原理.神经网络的结构和本质.正向传播算法.链式求导及反向传播算法.神经网络怎么用于实际问题等 课程大纲: 神经网络的思想起源 神经元的原理 神经网络结构 正向传播算法 怎 ...
- SIGAI深度学习第九集 卷积神经网络3
讲授卷积神经网络面临的挑战包括梯度消失.退化问题,和改进方法包括卷积层.池化层的改进.激活函数.损失函数.网络结构的改 进.残差网络.全卷机网络.多尺度融合.批量归一化等 大纲: 面临的挑战梯度消失问 ...
- 【吴恩达课后测验】Course 1 - 神经网络和深度学习 - 第一周测验【中英】
[吴恩达课后测验]Course 1 - 神经网络和深度学习 - 第一周测验[中英] 第一周测验 - 深度学习简介 和“AI是新电力”相类似的说法是什么? [ ]AI为我们的家庭和办公室的个人设备供电 ...
- SIGAI机器学习第一集 机器学习简介
讲授机器学习的基本概念.发展历史与典型应用 大纲: 人工智能简介机器学习简介为什么需要机器学习机器学习的发展历史机器学习的典型应用人工智能主要的公司本课程讲授的算法 机器学习并不是人工智能一上来就采用 ...
- SIGAI深度学习第八集 卷积神经网络2
讲授Lenet.Alexnet.VGGNet.GoogLeNet等经典的卷积神经网络.Inception模块.小尺度卷积核.1x1卷积核.使用反卷积实现卷积层可视化等. 大纲: LeNet网络 Ale ...
- SIGAI深度学习第四集 深度学习简介
讲授机器学习面临的挑战.人工特征的局限性.为什么选择神经网络.深度学习的诞生和发展.典型的网络结构.深度学习在机器视觉.语音识别.自然语言处理.推荐系统中的应用 大纲: 机器学习面临的挑战 特征工程的 ...
- SIGAI深度学习第五集 自动编码器
深度学习模型-自动编码器(AE),就是一个神经网络的映射函数,f(x)——>y,把输入的一个原始信号,如图像.声音转换为特征. 大纲: 自动编码器的基本思想 网络结构 损失函数与训练算法 实际使 ...
- SIGAI深度学习第六集 受限玻尔兹曼机
讲授玻尔兹曼分布.玻尔兹曼机的网络结构.实际应用.训练算法.深度玻尔兹曼机等.受限玻尔兹曼机(RBM)是一种概率型的神经网络.和其他神经网络的区别:神经网络的输出是确定的,而RBM的神经元的输出值是不 ...
- 深度学习GPU集群管理软件 OpenPAI 简介
OpenPAI:大规模人工智能集群管理平台 2018年5月22日,在微软举办的“新一代人工智能开放科研教育平台暨中国高校人工智能科研教育高峰论坛”上,微软亚洲研究院宣布,携手北京大学.中国科学技术大学 ...
随机推荐
- Java基础---Java常量
常量:在程序运行期间不变的量 分类: 类型 含义 数据举例 整数常量 所有整数 0,1, 567, -9 小数常量 所有小数 0.0, -0.1, 2.55 字符常量 单引号引起来,只能写一个字符, ...
- redis 基本数据类型及使用
文章目录 相对其它 nosql 数据库的优势 杂项知识 基本数据类型 Key 关键字 String 类型(单键单值) List 类型 (单键多值) Set 类型 (单键多值) Hash类型 (KV模式 ...
- 数位dp踩坑
前言 数位DP是什么?以前总觉得这个概念很高大上,最近闲的没事,学了一下发现确实挺神奇的. 从一道简单题说起 hdu 2089 "不要62" 一个数字,如果包含'4'或者'62', ...
- 5-9 c语言之【初识win32编程】
---恢复内容开始--- 今天学习了win32的相关知识,首先win32是指是指可以在32位或以上Windows系统中运行的程序,我学习的主要利用c/c++语言编写的win32程序, 首先在win32 ...
- 一文搞懂嵌入式uboot、kernel、文件系统的关系
总览: 在linux系统软件架构可以分为4个层次(从低到高分别为): 1.引导加载程序 引导加载程序(Bootloader)是固化在硬件Flash中的一段引导代码,用于完成硬件的一 ...
- (二)Struts.xml文件详解
一.Struts.xml文件 Struts.xml文件构成 如图,<Struts>标签内共有5个子标签. 1.1 struts-default.xml 查看Struts的内容可知,Stru ...
- SQL logic error no such module: fts5 解决方案
因项目原因,需要使用SQLite的全文索引,用到了最新的fts5模块 但在咱们.net framwork中却会提示“SQL logic error no such module: fts5”:找不到f ...
- SQL Server注入
1.利用错误消息提取信息 1.1 枚举当前表与列 --' 抛出错误:选择列表中的列 'users.id' 无效,因为该列没有包含在聚合函数或 GROUP BY 子句中. 发现表名为 'users',存 ...
- VBA if...else语句
一个if语句由一个布尔表达式和一个或多个语句组成.如果条件评估为True,则执行if条件下的语句.如果条件评估为False,则执行else部分块下的语句. 语法 以下是VBScript中的if els ...
- Linux学习笔记:cut命令
基础 功能:文件内容查看,显示行中指定部分,删除文件中指定字段.cut 命令用于显示每行从开头算起 a - b 的文字. 语法: cut [-bn] [file.txt] cut [-c] [file ...