Redis 数据结构 & 原理 & 持久化
一 概述
redis是一种高级的key-value数据库,它跟memcached类似,不过数据可以持久化,而且支持的数据类型也很丰富。
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
支持在服务器端计算集合的并,交和补集(difference)等,还支持多种排序功能,所以redis也可以被看成是一个数据结构服务器
1 String(字符串)
string是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
string类型是Redis最基本的数据类型,一个键最大能存储512MB。
常用命令 get set decr incr mget等
实例
redis 127.0.0.1:> SET name "runoob"
OK
redis 127.0.0.1:> GET name
"runoob"
在以上实例中我们使用了 Redis 的 SET 和 GET 命令。键为 name,对应的值为 runoob。
redis> SET redis redis.com
OK redis> SET mongodb mongodb.org
OK redis> MGET redis mongodb
1) "redis.com"
2) "mongodb.org" redis> MGET redis mongodb mysql # 不存在的 mysql 返回 nil
1) "redis.com"
2) "mongodb.org"
3) (nil)
上面命令是MGET的用法: 返回所有(一个或多个)给定 key 的值。
如果给定的 key 里面,有某个 key 不存在,那么这个 key 返回特殊值 nil 。因此,该命令永不失败。
2 Hash(哈希)
Redis hash 是一个键值(key=>value)对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
常用命令 hget hset hgetall等
实例
redis> HMSET myhash field1 "Hello" field2 "World"
"OK"
redis> HGET myhash field1
"Hello"
redis> HGET myhash field2
"World"
以上实例中 hash 数据类型存储了包含用户脚本信息的用户对象。 实例中我们使用了 Redis HMSET 命令
每个 hash 可以存储 232 -1 键值对(40多亿)。
应用场景: 在memcached中,我们经常将一些结构化的信息打包成hashMap,在客户端序列化后存储为一个字符串,比如用户的昵称,年龄,性别,积分等,一旦需要修改其中某一项时,通常需要将所有值取出反序列化后,修改某一项的值,再序列化存储回去。这样不仅增大了开销,也不适用一些可能出现并发操作的场合。而redis的hash结构可以像在数据库中update一个字段的值一样,只修改到值,而不必取出全部数据内容
Memcached在Hash的应用场景下,我们要存储一个用户信息对象数据,包含用户ID,姓名,年龄,生日等信息,主要有以下2种存储方式:
方案1:
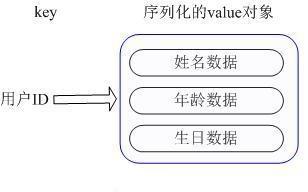
No.1将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储,这种方式的缺点是,增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
方案2:
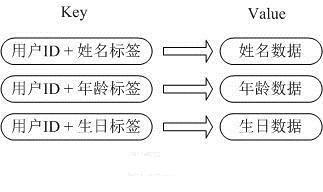
No.2这个用户信息对象有多少成员就存成多少个key-value对,用用户ID+对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题,但是大量重复用户ID这样的数据,内存浪费还是非常严重的。
然而Redis提供的Hash很好的解决了这个问题,Redis的Hash内部存储的value为一个HashMap,并且可以直接操作这个Map成员方法。
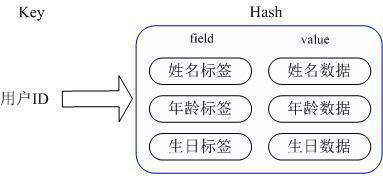
也就是说,Key仍然是用户ID, value是一个Map,这个Map的key是成员的属性名,类似字段,value是属性值,这样对数据的修改和存取都可以直接通过其内部Map的field, 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题,很好的解决了问题。
3 List(列表)
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
常用命令 lpush lpop rpush rpop lrange等
Redis 中list的数据结构实现是双向链表,所以可以非常便捷的应用于消息队列(生产者 / 消费者模型)。消息的生产者只需要通过lpush将消息放入 list,消费者便可以通过rpop取出该消息,并且可以保证消息的有序性。由于 Redis 拥有持久化功能,也不需要担心由于服务器故障导致消息丢失。
实例
redis 127.0.0.1:> lpush runoob redis
(integer)
redis 127.0.0.1:> lpush runoob mongodb
(integer)
redis 127.0.0.1:> lpush runoob rabitmq
(integer)
redis 127.0.0.1:> lrange runoob
) "rabitmq"
) "mongodb"
) "redis"
redis 127.0.0.1:>
列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)。
4 Set(集合)
Redis的Set是string类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
常用命令:sadd,spop,smembers,sunion
应用场景:
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,set还可以判断某个成员是否在一个set集合内的重要方法。还有一个微博用的关注关系,例如:用户 A,将它的关注和粉丝的用户 id 都存放在两个 set 中:
A:follow:存放 A 所有关注的用户 id
A:followed:存放 A 所有粉丝的用户 id
根据A:follow和A:followed的交集得到与 A 互相关注的用户。
sadd 命令
添加一个string元素到,key对应的set集合中,成功返回1,如果元素已经在集合中返回0,key对应的set不存在返回错误。
sadd key member
实例
redis 127.0.0.1:> sadd runoob redis
(integer)
redis 127.0.0.1:> sadd runoob mongodb
(integer)
redis 127.0.0.1:> sadd runoob rabitmq
(integer)
redis 127.0.0.1:> sadd runoob rabitmq
(integer)
redis 127.0.0.1:> smembers runoob ) "rabitmq"
) "mongodb"
) "redis"
注意:以上实例中 rabitmq 添加了两次,但根据集合内元素的唯一性,第二次插入的元素将被忽略。
集合中最大的成员数为 232 - 1(4294967295, 每个集合可存储40多亿个成员)。
5 zset(sorted set:有序集合)
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
常用命令:zadd,zrange,zrem,zcard等
使用场景:
Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构。常见sorted set和一个计算热度的算法便可以轻松打造一个热度排行榜,zrevrangebyscore可以得到以分数倒序排列的序列,zrank可以得到一个成员在该排行榜的位置(是分数正序排列时的位置,如果要获取倒序排列时的位置需要用zcard-zrank)。
zadd 命令
添加元素到集合,元素在集合中存在则更新对应score
zadd key score member
实例
redis 127.0.0.1:> zadd runoob redis
(integer)
redis 127.0.0.1:> zadd runoob mongodb
(integer)
redis 127.0.0.1:> zadd runoob rabitmq
(integer)
redis 127.0.0.1:> zadd runoob rabitmq
(integer)
redis 127.0.0.1:> ZRANGEBYSCORE runoob ) "redis"
) "mongodb"
) "rabitmq"
二 使用的场景
1 两大特性用途
(1)Pub/Sub
发布(Publish)与订阅(Subscribe),在Redis中,你可以设定对某一个key值进行消息发布及消息订阅,当一个key值上进行了消息发布后,所有订阅它的客户端都会收到相应的消息。这一功能最明显的用法就是用作实时消息系统,比如:群聊功能。
(2)Transactions
提供了基本的命令打包执行的功能,比如微博关注之后,除了添加一个关注ID(1315402)之后,还需要让被关注(19028474)的粉丝数量+1.这就可以进行打包进行:
> MULTI
OK
> sadd(19028474, 1315402)
QUEUED
> INCR 19028474
QUEUED
> EXEC
1) (integer) 1
2) (integer) 1
命令是顺序在一起执行的,中间不会有其实命令插进来执行。
2 其他常见的redis应用
(1)计数器
数据统计的需求非常普遍,通过redis原子操作计数。例如,点赞数、收藏数、分享数等。
(2)排行榜
排行榜按照得分进行排序,例如,展示最近、最热、点击率最高、活跃度最高等各种类型的top list。
(3)好友列表
例如,用户点赞列表、用户收藏列表、用户关注列表等。
(4)缓存
缓存热点数据,这也是redis最典型的应用之一,根据实际情况,缓存用户信息,缓存session等。
(5)存储时间戳
当用户发完微博后,都通过lpush将它存放在一个 key 为LATEST_WEIBO的list中,之后便可以通过lrange取出当前最新的微博,随着时间的变化,新的内容也在不断变化,保证每次用户刷新出来的都是最新最热的。
(6)判断行为
判断用户行为也是非常普遍,可以知道一个用户是否进行了某个操作。例如,用户是否点赞、用户是否收藏、用户是否分享等,来决定下次打开后,相关按钮是否置灰。
三 持久化的方式和原理
redis的所有数据都是保存在内存中的,
(1) 半持久化模式: 不定期地通过异步方式保存到磁盘上
(2) 全持久化模式: 把每一次数据变化都写入到一个append only file(aof)里面
1 半持久化模式 RDB(redis database)
(1)行为:
默认redis会以快照的形式将数据持久化到磁盘,生成一个二进制文件,比如叫dump.rdb,配置文件中的格式是 save N M。表示在N秒之内,redis至少发生M次修改则redis抓快照到磁盘。当然也可以手动执行save或bgsave(异步)做快照
(2)原理实现:
redis需要持久化时,fork一个子进程,子进程将数据写到磁盘上一个临时文件rdb文件中,当子进程完成写临时文件后,将原来的rdb替换掉,copy-on-write方式
(3)配置
RDB默认开启,redis.conf中的具体配置参数如下:
#dbfilename:持久化数据存储在本地的文件
dbfilename dump.rdb
#dir:持久化数据存储在本地的路径,如果是在/redis/redis-3.0./src下启动的redis-cli,则数据会存储在当前src目录下
dir ./
##snapshot触发的时机,save <seconds> <changes>
##如下为900秒后,至少有一个变更操作,才会snapshot
##对于此值的设置,需要谨慎,评估系统的变更操作密集程度
##可以通过“save “””来关闭snapshot功能
#save时间,以下分别表示更改了1个key时间隔900s进行持久化存储;更改了10个key300s进行存储;更改10000个key60s进行存储。
save
save
save
##当snapshot时出现错误无法继续时,是否阻塞客户端“变更操作”,“错误”可能因为磁盘已满/磁盘故障/OS级别异常等
stop-writes-on-bgsave-error yes
##是否启用rdb文件压缩,默认为“yes”,压缩往往意味着“额外的cpu消耗”,同时也意味这较小的文件尺寸以及较短的网络传输时间
rdbcompression yes
客户端使用命令进行持久化save存储:
./redis-cli -h ip -p port save
./redis-cli -h ip -p port bgsave
一个是在前台进行存储,一个是在后台进行存储。我的client就在server这台服务器上,所以不需要连其他机器,直接./redis-cli bgsave。由于redis是用一个主线程来处理所有 client的请求,这种方式会阻塞所有client请求。所以不推荐使用。另一点需要注意的是,每次快照持久化都是将内存数据完整写入到磁盘一次,并不是增量的只同步脏数据。如果数据量大的话,而且写操作比较多,必然会引起大量的磁盘io操作,可能会严重影响性能。
2 全持久化模式 AOF(append only file)
(1)行为
snapshotting的半持久化方法在redis异常死掉时,会造成数据的丢失(取决于save的时机和频率)。而AOF可以做到数据不丢失,相应地性能就会差一些。在配置文件中开启(默认是no),appendonlyyes开启AOF后,redis每执行一个修改数据的命令,都会把它添加到AOF文件中,当redis重启时,将会读取AOF文件进行"回放"以恢复到redis关闭前的最后时刻
随着修改数据的执行AOF文件会越来越大,其中很多内容反复记录某一个key的变化情况,因此redis有一个特性对此进行了优化: 不影响client端操作的同时,后台重建AOF文件,在任何时候执行BGREWRITEAOF命令,都会把当前内存中最短序列的命令写到磁盘,这些命令完全可以构建当前的数据而没有多余的变化情况(如状态变化,计数器变化等),缩小了AOF文件的大小。
AOF相对可靠,它和mysql的bin.log, zk的txn-log异曲同工。AOF文件内容是字符串,非常容易阅读和解析,且在没有被rewrite前,可以删除其中的某些命令(比如误操作的flushall)
AOF文件刷新的方式,有三种,需要配置参数appendfsync:
a) appendfsync always每提交一个修改命令都调用fsync刷新到AOF文件,非常非常慢,但也非常安全;
b) appendfsync everysec每秒钟都调用fsync刷新到AOF文件,很快,但可能会丢失一秒以内的数据;
c) appendfsync no依靠OS进行刷新,redis不主动刷新AOF,这样最快,但安全性就差。默认并推荐每秒刷新,这样在速度和安全上都做到了兼顾。
(2)原理实现:
同样用到了copy-on-write,首先redis会fork一个子进程;子进程将最新的AOF写入一个临时文件;父进程增量的把内存中的最新执行的修改写入(这时仍写入旧的AOF,rewrite如果失败也是安全的);当子进程完成rewrite临时文件后,父进程会收到一个信号,并把之前内存中增量的修改写入临时文件末尾;这时redis将旧AOF文件重命名,临时文件重命名,开始向新的AOF中写入。
(4)配置
AOF默认关闭,需要修改配置文件redis.conf, 主要是appendonly yes
##此选项为aof功能的开关,默认为“no”,可以通过“yes”来开启aof功能
##只有在“yes”下,aof重写/文件同步等特性才会生效
appendonly yes ##指定aof文件名称
appendfilename appendonly.aof ##指定aof操作中文件同步策略,有三个合法值:always everysec no,默认为everysec
appendfsync everysec
##在aof-rewrite期间,appendfsync是否暂缓文件同步,"no"表示“不暂缓”,“yes”表示“暂缓”,默认为“no”
no-appendfsync-on-rewrite no ##aof文件rewrite触发的最小文件尺寸(mb,gb),只有大于此aof文件大于此尺寸是才会触发rewrite,默认“64mb”,建议“512mb”
auto-aof-rewrite-min-size 64mb ##相对于“上一次”rewrite,本次rewrite触发时aof文件应该增长的百分比。
##每一次rewrite之后,redis都会记录下此时“新aof”文件的大小(例如A),那么当aof文件增长到A*( + p)之后
##触发下一次rewrite,每一次aof记录的添加,都会检测当前aof文件的尺寸。
auto-aof-rewrite-percentage
3 最后
最后,为以防万一(机器坏掉或磁盘坏掉),记得定期把使用 filesnapshotting 或 Append-only 生成的*rdb *.aof文件备份到远程机器上。我是用crontab每半小时SCP一次。我没有使用redis的主从功能 ,因为半小时备份一次应该是可以了,而且我觉得有如果做主从有点浪费机器。这个最终还是看应用来定了。
四 redis常见的问题问法
1 redis为什么是单线程的?
因为cpu不是redis的瓶颈。redis的瓶颈最有可能是机器内存或者网络带宽。既然单线程容易实现,而且cpu不会成为瓶颈,那就顺理成章地采用单线程的方案了。关于redis的性能,官方网站也有,普通笔记本轻松处理每秒几十万的请求。
事实上,单纯的网络IO,在大量的请求时多线程的确有优势。但并不是单纯的多线程,而是每个线程有各自的epoll这样的模型,也就是多线程和I/O多路复用的结合。我们也要考虑一下redis操作的是内存中的数据结构,如果在多线程中就需要为这些对象加锁。所以使用多线程虽然可以提高性能,但是每个线程的效率严重下降了,而且程序的逻辑严重复杂化。redis的数据结构并不全是简单的key-value,还有list,hash等复杂的结构,这些结构有可能会进行很细粒度的操作,比如在一个很长的列表后面添加一个元素,在hash中添加或者删除一个对象,这些操作还可以合成MULTI/EXEC的组。这样操作中可能就需要加非常多的锁,导致的结果是同步开销大大增加。
redis在权衡之后的选择是用单线程,突出自己功能的灵活性。在单线程基础上任何原子操作都可以几乎无代价地实现,多么复杂的数据结构都可以轻松运用。
并不是所有的kv数据库或者内存数据库都应该用单线程,比如zk用的就是多线程,最终还是看源码作者的意愿和取舍。
2 万一cpu成为redis的瓶颈了,或者不想让服务器其他核闲置,怎么办
多起几个redis进程。redis是kv数据库不是关系数据库,数据之间没有约束。只要客户端分清哪些key放在哪个redis进程上就可以了。redis-cluster可以帮你做的更好
3 单线程可以处理高并发请求吗
可以,redis都实现了。有一点要注意,并发不是并行。
并发性I/O流,意味着能够让一个计算单元来处理来自多个客户端的流请求,
并行性,意味着服务器能够同时执行几个事情,具有多个计算单元
4 redis总体快速的原因
(1)绝大多数请求是纯粹的内存操作,非常快速
(2)采用单线程,避免了不必要的上下文切换和竞态条件
(3)非阻塞IO,多路复用。内部采用epoll,epoll中的读,写,关闭,连接都转化成了事件,然后利用epoll的多路复用特性,在io上没有浪费
这3个条件不是相互独立的,特别是第一条,如果请求都是耗时的,采用单线程吞吐量及性能可想而知了。应该说redis为特殊的场景选择了合适的技术方案。
5 redis相比memcached有哪些优势?
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度比memcached快很多
(3) redis可以持久化其数据
(4)Redis支持数据的备份,即master-slave模式的数据备份。
(5)value大小:redis最大可以达到1GB,而memcache只有1MB
(6)网络io模型方面: memcached是多线程,分为监听线程,worker线程,引入全局锁,也带来了性能损耗。redis使用单线程的io复用模型,将速度优势发挥到最大,各有千秋
(7)数据一致性方面: memcached提供了cas命令来保证,而redis提供了事务功能,可以保证一串命令的原子性,中间不会被任何操作打断
6. redis常见性能问题和解决方案:
(1) Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件
(Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照;AOF文件过大会影响Master重启的恢复速度)
(2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
(3) 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
(4) 尽量避免在压力很大的主库上增加从库
(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3...
这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变。
Redis 数据结构 & 原理 & 持久化的更多相关文章
- redis数据结构、持久化、缓存淘汰策略
Redis 单线程高性能,它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性能损耗问题.redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放 ...
- 《【面试突击】— Redis篇》-- Redis哨兵原理及持久化机制
能坚持别人不能坚持的,才能拥有别人未曾拥有的.关注编程大道公众号,让我们一同坚持心中所想,一起成长!! <[面试突击]— Redis篇>-- Redis哨兵原理及持久化机制 在这个系列里, ...
- 【redis】redis底层数据结构原理--简单动态字符串 链表 字典 跳跃表 整数集合 压缩列表等
redis有五种数据类型string.list.hash.set.zset(字符串.哈希.列表.集合.有序集合)并且自实现了简单动态字符串.双端链表.字典.压缩列表.整数集合.跳跃表等数据结构.red ...
- Redis 数据结构与内存管理策略(上)
Redis 数据结构与内存管理策略(上) 标签: Redis Redis数据结构 Redis内存管理策略 Redis数据类型 Redis类型映射 Redis 数据类型特点与使用场景 String.Li ...
- mysql主从复制、redis基础、持久化和主从复制
一.mysql(mariadb)基础 1.基础命令(centos7操作系统下) 1.启动mysql systemctl start mariadb 2.linux客户端连接自己 mysql -uroo ...
- Redis核心原理
Redis系统介绍: Redis的基础介绍与安装使用步骤:https://www.jianshu.com/p/2a23257af57b Redis的基础数据结构与使用:https://www.jian ...
- Redis内核原理及读写一致企业级架构深入剖析1-综合组件环境实战
1 Redis 工作模型 redis实际上是个单线程工作模型,其拥有较多的数据结构,并支持丰富的数据操作,redis目前是原生支持cluster模式.如果需要缓存能够支持更复杂的结构和操作,基于以上原 ...
- Redis Cluster 原理相关说明
背景 之前写的 Redis Cluster部署.管理和测试 和 Redis 5.0 redis-cli --cluster help说明 已经比较详细的介绍了如何安装和维护Cluster.但关于Clu ...
- Docker Compose 部署 Redis 及原理讲解 | 懒人屋
原文:Docker Compose 部署 Redis 及原理讲解 | 懒人屋 Docker Compose 部署 Redis 及原理讲解 4.4k 字 16 分钟 2019-10-1 ...
随机推荐
- Ubuntu14.04 支持 exFat 格式操作
推荐u盘使用exfat格式,为什么呢?两个原因: 1.三大主流操作系统(Linux.Mac.Windows)都支持exfat格式.2.exfat支持大于4G的文件. 在ubuntu下,由于版权的原因( ...
- c++ demo code
/* //多继承 #include <iostream> using namespace std; class Sofa { public: Sofa(); ~Sofa(); void s ...
- 进入docker 容器命令行
#!/bin/bash CNAME=$1 CPID=$(docker inspect --format "{{.State.Pid}}" $CNAME) nsenter --tar ...
- 注解之 @RestController 和 @RequestMapping
Controller 是 Spring 中最基本的组件,主要处理用户交互,一般每个业务逻辑都会有一个 Controller,供用户请求接口进行数据访问:@RequestMapping 注解用于绑定UR ...
- cxf报错 Cannot find any registered HttpDestinationFactory from the Bus.
错误信息:Cannot find any registered HttpDestinationFactory from the Bus. 报错主要是因为缺少jetty依赖 一般添加如下依赖即可 < ...
- Logback 日志策略配置
[参考文章]:官方文档:Logback configuration [参考文章]:logback的使用和logback.xml详解 [参考文章]:Logback源码赏析-日志按时间滚动(切割) 1. ...
- 区间dp括号匹配
POJ2955 匹配则加一,不需要初始化 //#include<bits/stdc++.h> #include<iostream> #include<cstdio> ...
- DataTable 转换为List
注意table 列的参数类型,若不为string 需要详细声明 如 typeof(Int32) public static IList<T> Convert ...
- 亿级在线系统二三事-网络编程/RPC框架 原创: johntech 火丁笔记 今天
亿级在线系统二三事-网络编程/RPC框架 原创: johntech 火丁笔记 今天
- [Java读书笔记] Effective Java(Third Edition) 第 6 章 枚举和注解
Java支持两种引用类型的特殊用途的系列:一种称为枚举类型(enum type)的类和一种称为注解类型(annotation type)的接口. 第34条:用enum代替int常量 枚举是其合法值由一 ...