solr8.2 环境搭建 配置中文分词器 ik-analyzer-solr8 详细步骤
一、下载安装Apache Solr 8.2.0
下载地址:http://lucene.apache.org/solr/downloads.html
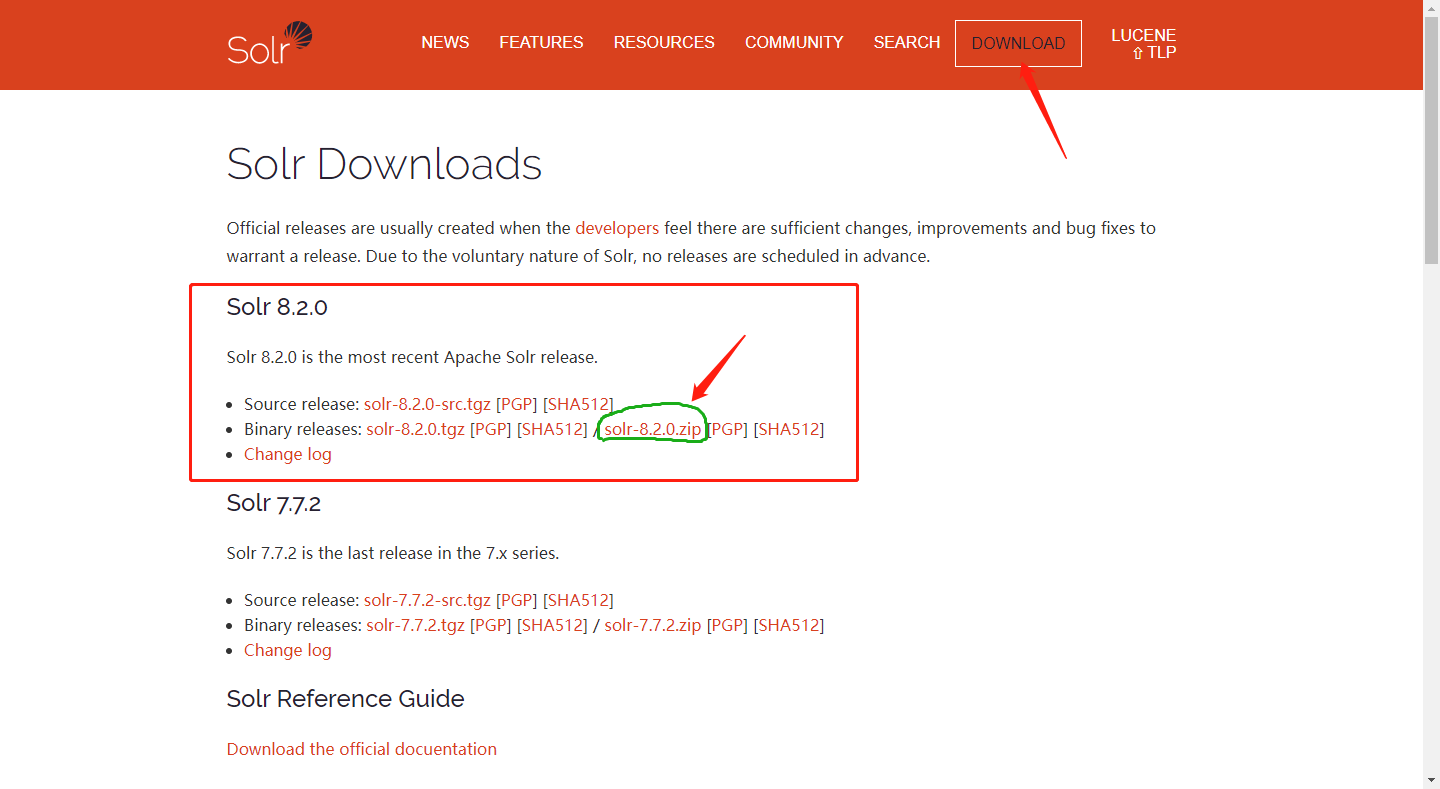
因为是部署部署在windows系统上,所以下载zip压缩包即可。
下载完成后解压出来。
二、启动solr服务
进入solr-7.3.0/bin目录:
Shift+右键 在此处打开命令窗口;

在控制台输入以下命令:
./solr start -p 9090

看到Started Solr server on port 9090. Happy searching!表示solr服务已经启动成功,这里是用solr自带的jetty启动的。
接下来我们可以打开浏览器访问:http://localhost:9090/solr/index.html
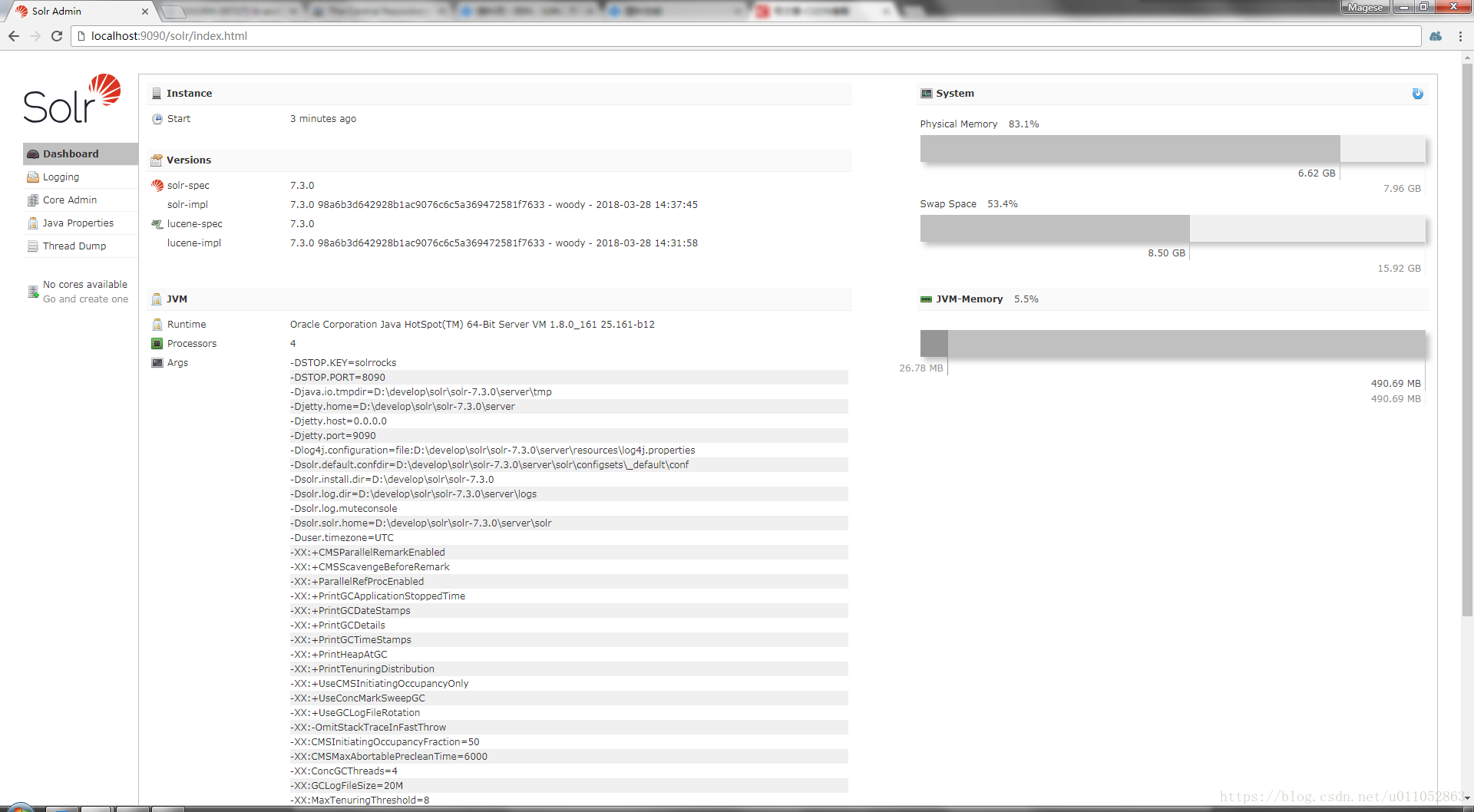
就可以看到solr已经成功启动了。
三、添加solr core
先进入solr-7.3.0/example/example-DIH/solr/solr目录中
将该目录中的conf文件夹与core.properties文件copy

接下来我们进入solr-7.3.0/server/solr目录
在此目录创建一个文件夹mycore
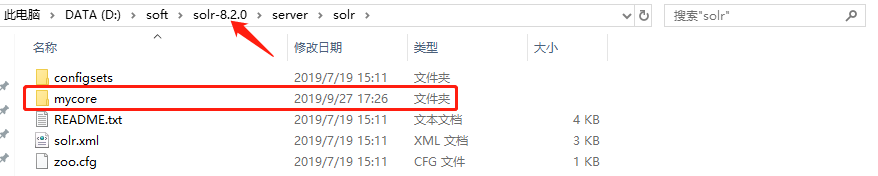
然后我们将上面的conf文件夹和core.properties文件copy到此文件夹中

接下来在之前启动的cmd窗口重启一下solr服务,在控制台输入以下命令:
./solr restart -p 9090

重启完成后刷新一下http://localhost:9090/solr/index.html页面,
发现solr core已经添加成功了

四、配置中文分词器 IK-Analyzer-Solr8
先下载solr8版本的ik分词器,下载地址:https://search.maven.org/search?q=com.github.magese
分词器GitHub源码地址:https://github.com/magese/ik-analyzer-solr8
GitHub上有分词器的使用方式

将下载好的jar包放入solr-7.3.0/server/solr-webapp/webapp/WEB-INF/lib目录中
然后到solr-7.3.0/server/solr/mycore/conf目录中打开managed-schema文件
在配置文件中加入以下代码:
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>

配置完成后再次重启一次solr服务
./solr restart -p 9090

再次刷新http://localhost:9090/solr/index.html页面
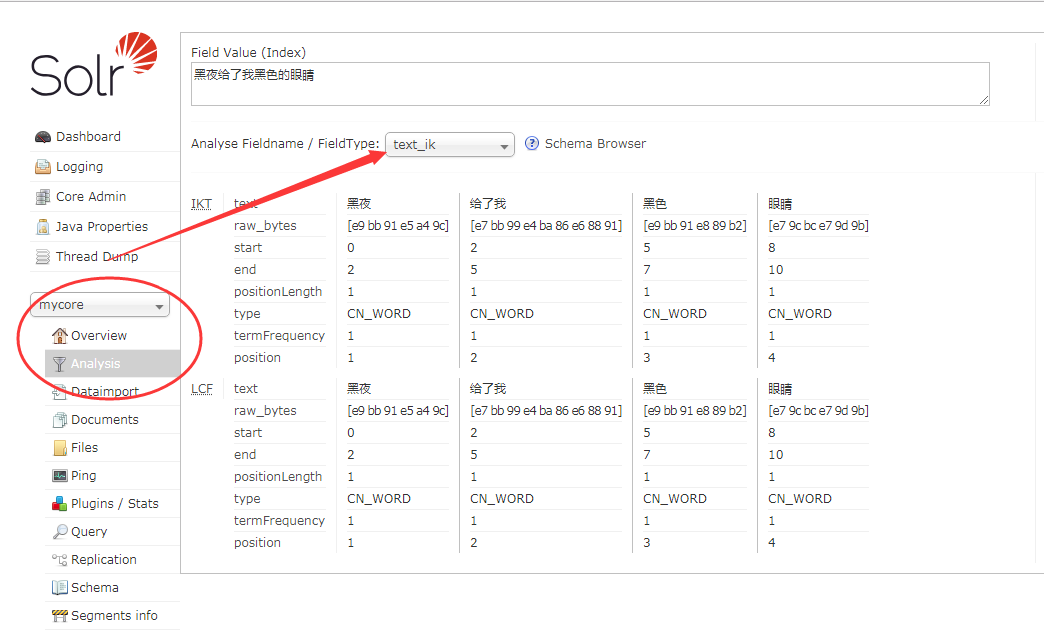
选择mycore -> Analysis -> 选择分词器 text_ik 输入 "黑夜给了我黑色的眼睛"
点击"Analyse Values"按钮可以看到结果已经分词成功了。
solr8.2 环境搭建 配置中文分词器 ik-analyzer-solr8 详细步骤的更多相关文章
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- ElasticSearch搜索引擎安装配置中文分词器IK插件
近几篇ElasticSearch系列: 1.阿里云服务器Linux系统安装配置ElasticSearch搜索引擎 2.Linux系统中ElasticSearch搜索引擎安装配置Head插件 3.Ela ...
- solrcloud配置中文分词器ik
无论是solr还是luncene,都对中文分词不太好,所以我们一般索引中文的话需要使用ik中文分词器. 三台机器(192.168.1.236,192.168.1.237,192.168.1.238)已 ...
- ElasticSearch7.3学习(十五)----中文分词器(IK Analyzer)及自定义词库
1. 中文分词器 1.1 默认分词器 先来看看ElasticSearch中默认的standard 分词器,对英文比较友好,但是对于中文来说就是按照字符拆分,不是那么友好. GET /_analyze ...
- Solr 配置中文分词器 IK
1. 下载或者编译 IK 分词器的 jar 包文件,然后放入 ...\apache-tomcat-8.5.16\webapps\solr\WEB-INF\lib\ 这个 lib 文件目录下: IK 分 ...
- 5.Solr4.10.3中配置中文分词器
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 1.下载IK Analyzer 2012FF_hf1.zip并上传到/home/test 2.按照如下命令安装 ...
- 沉淀再出发:ElasticSearch的中文分词器ik
沉淀再出发:ElasticSearch的中文分词器ik 一.前言 为什么要在elasticsearch中要使用ik这样的中文分词呢,那是因为es提供的分词是英文分词,对于中文的分词就做的非常不好了 ...
- 如何在Elasticsearch中安装中文分词器(IK)和拼音分词器?
声明:我使用的Elasticsearch的版本是5.4.0,安装分词器前请先安装maven 一:安装maven https://github.com/apache/maven 说明: 安装maven需 ...
随机推荐
- self-attention详解
编写你自己的 Keras 层 对于简单.无状态的自定义操作,你也许可以通过 layers.core.Lambda 层来实现.但是对于那些包含了可训练权重的自定义层,你应该自己实现这种层. 这是一个 K ...
- react 做的简易todolist
首先要有一定的react的基础,里面的一些不做解释(包括项目文件的用法及作用) ### 1. 先安装react的插件 npm install create-react-app -g ...
- 如何抓住ECS的命门,让我们的学习事半功倍
导读 这是一篇老文写与2019年5月 我们说如何提高我们的学习效率,有人说一本书一般只会讲一个知识点,那我们学习ECS 如何抓住学习的重点,提高学习效率.经过本人一段时间的学习总结,总于找到了一个便捷 ...
- opencv入门笔记
一.图片基本操作 1.1 显示图片 #include <opencv2/opencv.hpp> //头文件 using namespace cv; //包含cv命名空间 void main ...
- elasticsearch7.1.1【win】下载安装
下载:https://www.elastic.co/cn/downloads/elasticsearch 历史版本下载:https://www.elastic.co/cn/downloads/past ...
- C语言位操作中指定的某一位数置0、置1、取反
一.指定的某一位数置1 宏 #define setbit(x,y) x|=(1<<y) 二.指定的某一位数置0 宏 #define clrbit(x,y) x&=~(1< ...
- poj1873(二进制枚举+求凸包周长)
题目链接:https://vjudge.net/problem/POJ-1873 题意:n个点(2<=n<=15),给出n个点的坐标(x,y).价值v.做篱笆时的长度l,求选择哪些点来做篱 ...
- PCL学习(二)三维模型转点云 obj转pcd----PCL实现
#include <pcl/io/io.h> #include <pcl/io/pcd_io.h> #include <pcl/io/obj_io.h> #incl ...
- TCP状态转换(图解+文字解说)
<深入分析 javaweb 技术内幕>P38 读书扩展 作者:淮左白衣 写于2018年4月12日20:58:36 目录 TCP状态转换图解 图解三次握手 文字讲解三次握手: 图解四次挥手 ...
- vscode配置phpxdebug
打debug还是很有必要的,以前嫌麻烦,现在觉得,通过debug可以看自己写的代码的执行的逻辑,更容易理清别人代码的逻辑. 步骤: 下载phpdebug插件 查看自己的php版本信息,下载对应的deb ...