ElasticSearch——分页查询
前言
ElasticSearch实现分页查询,有3种方式,他们在数据查询中各自占据着不同的优势,因此在搜索引擎的数据分页过程中,如何更好地利用各自的优势来进行数据查询是一个非常重要的过程。
传统分页(from&size)
按照一般的查询流程来说,如果我们想查询前10条数据:
- 客户端请求发送给某个节点;
- 节点转发给各个分片,查询每个分片上的前10条数据;
- 查询结果返回给节点,并将数据进行整合,提取前10条数据;
- 将查询结果返回给客户端。
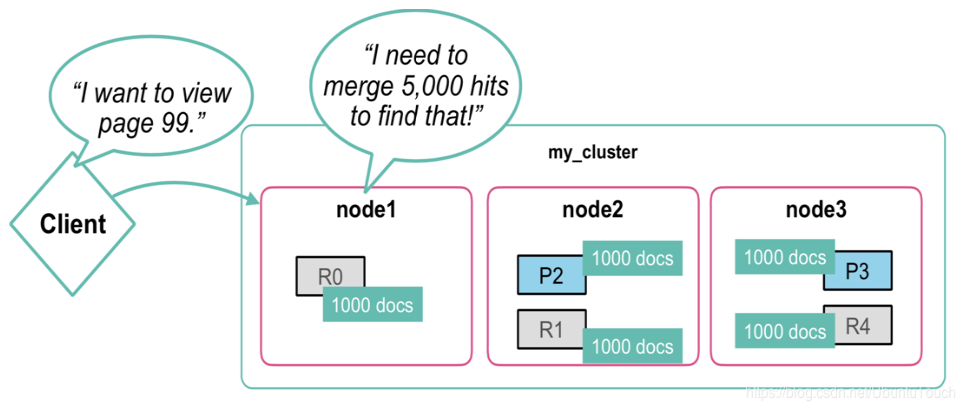
其原理就是当我们需要查询第10条到第20条数据时,节点从各个分片上获取10条数据并进行数据整合,然后从整合的数据中获取第10条到第20条数据作为请求的结果。查询的方法如下:
{
'from' : ,
'size' : ,
'query' : {
'term' : {
'user' : 'kimchy'
}
}
}
其中from定义了目标数据的偏移值,size定义了当前返回的事件数目。默认from为0,size为10,即所有的查询默认返回前10条数据。
在实际测试过程中,当此方式的访问页码越高,其执行的查询效率就越低。假设我们现在需要获取第20页的数据,ElasticSearch不得不取出所有分片上的第1页到第20页的所有文档,并对其进行合并排序,最终再取出from后的size条作为最终的返回结果;假设我们现在服务器上有16个分片,则我们需要汇总到shards*(from+size)条记录,即需要16*(20+10)条记录后,对其进行整合再做一次全局排序。因此,当索引非常大时,我们是无法使用from+size方式做深分页的,分页越深越容易OOM或者消耗内存,所以ES使用index.max_result_window:10000作为保护措施来避免这种情况的发生。但实际上当访问数据非常大时,我们采用scroll游标的方式来获取数据是更好地一种选择。
大数据量的快照分页(scroll)
相对于from&size的分页来说,使用scroll可以模拟一个传统的游标来记录当前读取的文档信息位置。采用此分页方法,不是为了实时查询数据,而是为了查询大量甚至全部的数据。此方式相对于维护了一份当前索引的快照信息,在执行数据查询时,scroll将会从这个快照信息中获取数据。它相对于传统的分页方式来说,不是查询所有数据再剔除掉不需要的部分,而是记录一个读取的位置来保证下次对数据的继续获取。
1、scroll访问数据过程
在使用scroll方式进行数据请求的过程中,主要分为四步,第一步首先通过设置访问地址和端口号等信息获取到客户端对象;第二步设置请求的索引名称、类型值、分页大小以及每次请求的scroll游标存活时间等信息,然后向服务器发送数据查询请求,并保存返回结果中的scroll_id值,此id值作为下次访问的必要内容;第三步获取到第一次请求的scroll_id值,再次设置数据请求的scroll游标存活时间,即可访问下一组size大小的索引数据,依次循环直到数据请求完毕;第四步,清除滚屏的scroll_id值,释放内存资源。
2、用Java代码实现scroll访问过程
当了解到scroll数据请求的原理之后,我们可以用Java代码对其进行相应的测试,其中主要包括两种实现方式,一种是采用Transport方式进行访问,另一种是采用Rest方式进行访问;但官方建议使用Rest方式进行请求,因为Transport在ES8.X版本中将会被废弃。
3、采用scroll方式请求的缺点
- scroll是对数据的一种快照,当数据发生任何变化的情况下(比如新增、更新和删除操作),是不会被感知到的,且维护scroll上下文也是非常昂贵的,因此不适用于实时和高并发的场景;
- 因为采用scroll方式,每次的数据请求都需要上一次请求结果中的scroll_id值来作为下次访问时的标志,因此采用此方式无法进行页面的随机跳转功能,只能进行滚动式数据浏览(类似于微博);
search_after
它与scroll API非常相似,但与它不同,search_after参数是无状态的,它始终针对最新版本的搜索器进行解析。 因此,排序顺序可能会在步行期间发生变化,具体取决于索引的更新和删除。
待补充....
总结
在这几种方式中,scroll方式适用于ES中索引数据很大的情况,因为scroll第一次请求数据时的时间相对于后面请求size大小的时间大得多(原因是因为此种方式会将满足条件的所有索引数据都以快照的方式保存在内存中,然后后续的数据请求都直接可以获取,因此第一次和之后的请求时间会差别比较大);当数据量比较小时,采用传统的from&size方式的效率就会比较高。
无论是哪种方式,避免深分页查询。
ElasticSearch——分页查询的更多相关文章
- elasticsearch 分页查询实现方案——Top K+归并排序
elasticsearch 分页查询实现方案 1. from+size 实现分页 from表示从第几行开始,size表示查询多少条文档.from默认为0,size默认为10,注意:size的大小不能超 ...
- Elasticsearch——分页查询From&Size VS scroll
Elasticsearch中数据都存储在分片中,当执行搜索时每个分片独立搜索后,数据再经过整合返回.那么,如果要实现分页查询该怎么办呢? 更多内容参考Elasticsearch资料汇总 按照一般的查询 ...
- ElasticSearch—分页查询
ElasticSearch查询—分页查询详解 Elasticsearch中数据都存储在分片中,当执行搜索时每个分片独立搜索后,数据再经过整合返回.那么,如何实现分页查询呢? 按照一般的查询流程来说,如 ...
- elasticsearch 分页查询实现方案
1. from+size 实现分页 from表示从第几行开始,size表示查询多少条文档.from默认为0,size默认为10, 注意:size的大小不能超过index.max_result_wind ...
- Elasticsearch 分页查询
目录 前言 from + size search after scroll api 总结 参考资料 前言 我们在实际工作中,有很多分页的需求,商品分页.订单分页等,在MySQL中我们可以使用limit ...
- Elasticsearch分页查询
global index global CLIENT index = "guajibao-ipused-2019.10.13" CLIENT = Elasticsearch(hos ...
- Elasticsearch教程(九) elasticsearch 查询数据 | 分页查询
Elasticsearch 的查询很灵活,并且有Filter,有分组功能,还有ScriptFilter等等,所以很强大.下面上代码: 一个简单的查询,返回一个List<对象> .. ...
- elasticsearch查询之大数据集分页查询
一. 要解决的问题 search命中的记录特别多,使用from+size分页,直接触发了elasticsearch的max_result_window的最大值: { "error" ...
- Elasticsearch from/size-浅分页查询-深分页 scroll-深分页search_after深度查询区别使用及应用场景
Elasticsearch调研深度查询 1.from/size 浅分页查询 一般的分页需求我们可以使用from和size的方式实现,但是这种的分页方式在深分页的场景下应该是避免使用的.深分页的页次增加 ...
随机推荐
- Sonya and Exhibition
http://codeforces.com/group/1EzrFFyOc0/contest/1004/problem/B #include<iostream> #include<c ...
- 2018/7/31--zznu-oj-问题 G: 方差 普拉斯--【两重暴力循环求方差即可!】
问题 G: 方差 普拉斯 时间限制: 1 Sec 内存限制: 128 MB提交: 94 解决: 17[提交] [状态] [讨论版] [命题人:admin] 题目描述 方差(样本方差)是每个样本值与 ...
- ASP.NET MVC 使用分部视图制作公共头部,尾部,并通过ViewBag传值
一:新建分部视图 二:布局页_Layout.cshtml上调用 不灵活,不能传递数据,引用静态公共部分 @Html.Partial("_Head") @Html.Partial(& ...
- 前端知识体系:JavaScript基础-作用域和闭包-JavaScript的作用域和作用域链
JavaScript的作用域和作用域链 作用域: 变量的作用域无非两种:全局作用域和局部作用域 全局作用域: 最外层函数定义的变量拥有全局作用域.即对任何内部函数来说都是可以访问的. <scri ...
- mysql sql语句多表合并UNION ALL和UNION
select d1.ID,CAST(d1.ID AS CHAR) AS intId, d1.CODE_TYPE, d1.CODE, d1.CODE_IMG, d1.VALUE from m_dict_ ...
- redis使用例子
package test.iafclub.redis; import java.util.ArrayList; import java.util.HashMap; import java.util.I ...
- The websites related Laravel 相关网站(内容将不断更新)
https://laraveldaily.com/ 文章内容质量很高
- web批量下载文件到本地
JavaWeb 文件下载功能 文件下载的实质就是文件拷贝,将文件从服务器端拷贝到浏览器端,所以文件下载需要IO技术将服务器端的文件读取到,然后写到response缓冲区中,然后再下载到个人客户端. 1 ...
- bzoj3694
/* * 对于不在最短路树上的边(x, y) * 1 * | * | * t * / \ * / \ * x-----y * 考虑这样一种形态的图, ‘-’ 标记为非最短路树的边 * 对于边集(x, ...
- UVA1674 闪电的能量 树剖
UVA1674 闪电的能量 树剖 题面 水.树剖模板 #include <cstdio> #include <cstring> #include <algorithm&g ...