webpack中bundler源码编写
word.js
export const word = 'hello';
message.js
import { word } from './word.js';
const message = `say ${word}`;
export default message;
index.js
import message from './message.js';
console.log(message);
这三个模块通过调用,最后打印出say hello。那我们说,如果直接想src目录下的代码运行下浏览器下,是不可以的;浏览器根本就不认识这种语法。所以我们需要通过webpack类似的打包工具帮助我们进行项目的打包。在根目录下创建一个bundler.js,这就是我们要做的打包工具
const fs = require('fs'); // 帮助我们获取一些文件的信息
// 分析模块
const moduleAnalyser = (filename) => {
// 读取文件内容
const content = fs.readFileSync(filename, 'utf-8');
console.log(content);
}
moduleAnalyser('./src/index.js');
运行node bundler.js,输出出来的就是index.js里面的内容。这里在控制台显示的内容,黑色的文本,不是很好看。我们可以安装一个工具
sudo npm install cli-highlight -g
npm install @babel/parser --save
const fs = require('fs'); // 帮助我们获取一些文件的信息
const parser = require('@babel/parser'); // 帮助我们分析代码,引入的文件
// 分析模块
const moduleAnalyser = (filename) => {
// 读取文件内容
const content = fs.readFileSync(filename, 'utf-8');
console.log(parser.parse(content, {
sourceType: 'module' // 说明是es module的引入方式
}));
}
moduleAnalyser('./src/index.js');
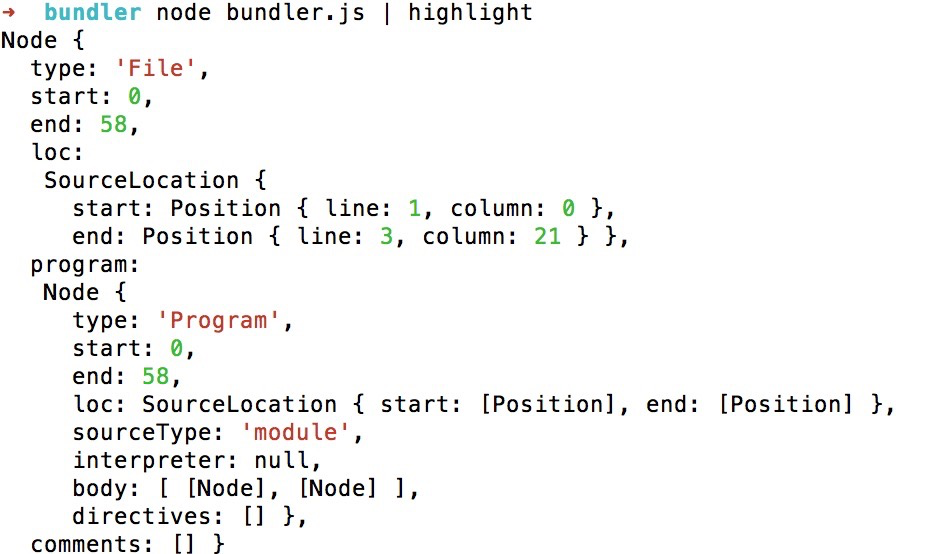
这个对象可以很好的表述我当前的这段代码。这个对象里有一个program这样的一个字段,表示当前运行的程序,里面有个body字段,我们可以打印这个字段看一下。
const fs = require('fs'); // 帮助我们获取一些文件的信息
const parser = require('@babel/parser'); // 帮助我们分析代码,引入的文件
// 分析模块
const moduleAnalyser = (filename) => {
// 读取文件内容
const content = fs.readFileSync(filename, 'utf-8');
const ast = parser.parse(content, {
sourceType: 'module' // 说明是es module的引入方式
})
console.log(ast.program.body);
}
moduleAnalyser('./src/index.js');
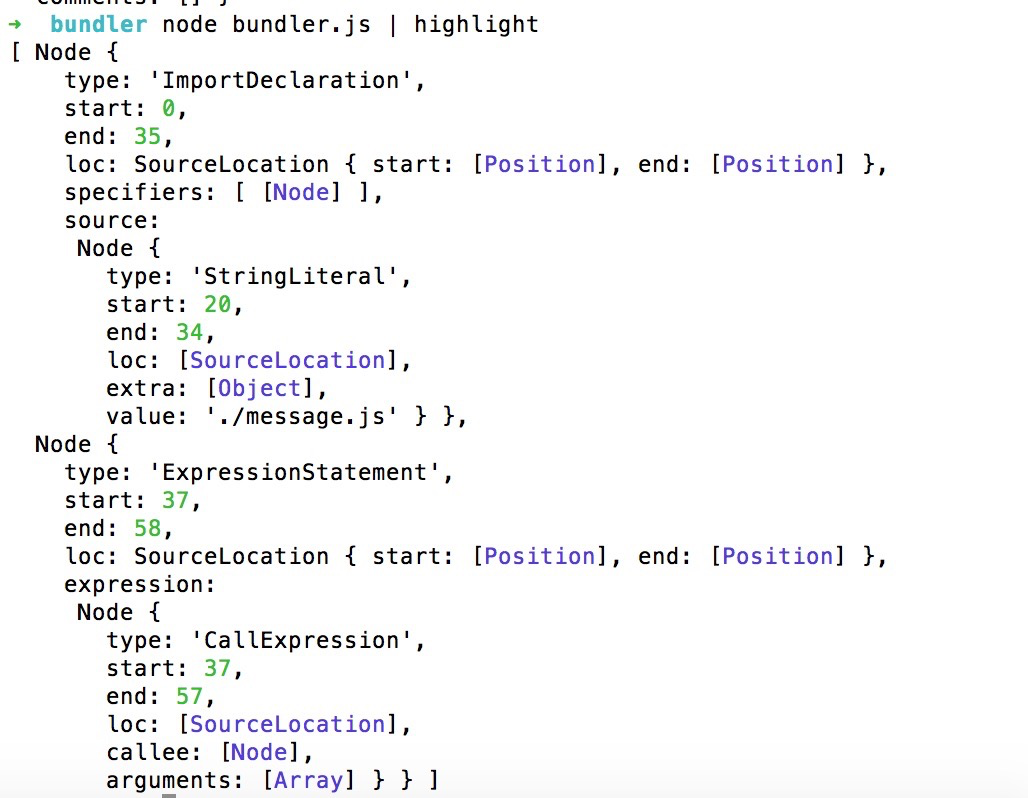
这个时候打印出来body的两个节点,首先第一个节点ImportDeclaration,确实是import一些东西。也就是引入的声明。第二个节点是ExpressionStatement,是一个表达式的声明,console.log确实是一个表达式的语句。所以通过babel.parser可以分析出抽象语法树。通过抽象语法树,我们就可以找到一些声明的语句,而声明的语句,放置的就是入口文件对应的一些依赖关系。我们可以遍历body,找到ImportDeclaration这样的一些内容,如果自己写一些遍历的话,还是有点麻烦,babel还提供给我们一个模块,可以帮助我们快速的找到import的节点。所以我们需要安装这样的一个模块
npm install @babel/traverse --save
bundler.js
const fs = require('fs'); // 帮助我们获取一些文件的信息
const parser = require('@babel/parser'); // 帮助我们分析代码,引入的文件
const traverse = require('@babel/traverse').default;// 因为是export出来的内容,必须加一个default属性才可以
// 分析模块
const moduleAnalyser = (filename) => {
// 读取文件内容
const content = fs.readFileSync(filename, 'utf-8');
// 利用parser.parse获取到ast
const ast = parser.parse(content, {
sourceType: 'module' // 说明是es module的引入方式
});
// 利用traverse对代码进行一个分析
const dependencies = [];
traverse(ast, {
// 只要抽象语法树有ImportDeclaration就会进入这个方法,node是节点
ImportDeclaration({ node }){
dependencies.push(node.source.value);
}
});
console.log(dependencies);
}
moduleAnalyser('./src/index.js');
再次运行 node bundler.js | highlight。发现已经打印出了依赖的模块。[ './message.js' ]。
const fs = require('fs'); // 帮助我们获取一些文件的信息
const path = require('path'); // 打包的时候需要绝对路径,借助path这个模块
const parser = require('@babel/parser'); // 帮助我们分析代码,引入的文件
const traverse = require('@babel/traverse').default;// 因为是export出来的内容,必须加一个default属性才可以
// 分析模块
const moduleAnalyser = (filename) => {
// 读取文件内容
const content = fs.readFileSync(filename, 'utf-8');
// 利用parser.parse获取到ast
const ast = parser.parse(content, {
sourceType: 'module' // 说明是es module的引入方式
});
// 利用traverse对代码进行一个分析
const dependencies = [];
traverse(ast, {
// 只要抽象语法树有ImportDeclaration就会进入这个方法,node是节点
ImportDeclaration({ node }){
// 拿到filename对应的文件夹路径
const dirname = path.dirname(filename);
// 对这个文件夹的路径进行一个转化,将引入的模块转化成绝对路径
const newFile = path.join(dirname, node.source.value);
console.log(newFile);
dependencies.push(node.source.value);
}
});
}
moduleAnalyser('./src/index.js');
这个时候打印出来的就是引入的模块的绝对路径。入口文件和相对应的依赖,都可以分析出来了。但是我们的代码,浏览器还是不支持的,需要借助babel去解析我们es6的代码。
npm install @babel/core --save
const fs = require('fs'); // 帮助我们获取一些文件的信息
const path = require('path'); // 打包的时候需要绝对路径,借助path这个模块
const parser = require('@babel/parser'); // 帮助我们分析代码,引入的文件
const traverse = require('@babel/traverse').default;// 因为是export出来的内容,必须加一个default属性才可以
const babel = require('@babel/core'); // babel的核心模块,转化代码,转化成浏览器认识的代码
// 分析模块
const moduleAnalyser = (filename) => {
// 读取文件内容
const content = fs.readFileSync(filename, 'utf-8');
// 利用parser.parse获取到ast
const ast = parser.parse(content, {
sourceType: 'module' // 说明是es module的引入方式
});
// 利用traverse对代码进行一个分析
const dependencies = {};
traverse(ast, {
// 只要抽象语法树有ImportDeclaration就会进入这个方法,node是节点
ImportDeclaration({ node }){
// 拿到filename对应的文件夹路径
const dirname = path.dirname(filename);
// 对这个文件夹的路径进行一个转化,将引入的模块转化成相对于bundler的相对路径
const newFile = './' + path.join(dirname, node.source.value);
// 为了方便,把相对路径,绝对路径都存上,key是相对路径,value是绝对路径
dependencies[node.source.value] = newFile;
}
});
// 这个方法可以将抽象语法树转化成浏览器可以运行代码。
const { code } = babel.transformFromAst(ast, null, {
presets: ['@babel/preset-env'] // 把es6语法翻译成es5语法
});
// 返回入口文件和相对应的依赖,都可以分析出来了。
return {
filename,
dependencies,
code
}
}
const moduleInfo = moduleAnalyser('./src/index.js');
console.log(moduleInfo);
这个时候就分析好了文件该有的内容,入口文件,对应的依赖,翻译好的代码。那么接下来就是分析其他的文件
webpack中bundler源码编写的更多相关文章
- webpack中bundler源码编写2
通过第一部分的学习,我们已经可以分析一个js的文件.这节课我们学习Dependencies Graph,也就是依赖图谱.对所有模块进行分析.先分析index.js.index.js里面引入了messg ...
- php中foreach源码分析(编译原理)
php中foreach源码分析(编译原理) 一.总结 编译原理(lex and yacc)的知识 二.php中foreach源码分析 foreach是PHP中很常用的一个用作数组循环的控制语句.因为它 ...
- vue打包时,assets目录 和static目录下文件的处理区别(nodeModule中插件源码修改后,打包后的文件应放在static目录)
为了回答这个问题,我们首先需要了解Webpack如何处理静态资产.在 *.vue 组件中,所有模板和CSS都会被 vue-html-loader 及 css-loader 解析,并查找资源URL.例如 ...
- 【原】Spark中Client源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Client源码分析(一)http://www.cnblogs.com/yourarebest/p/5313006.html DriverClient中的 ...
- 【原】Spark中Master源码分析(二)
继续上一篇的内容.上一篇的内容为: Spark中Master源码分析(一) http://www.cnblogs.com/yourarebest/p/5312965.html 4.receive方法, ...
- 【原】 Spark中Worker源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Worker源码分析(一)http://www.cnblogs.com/yourarebest/p/5300202.html 4.receive方法, r ...
- Django缓存机制--rest_framework中节流源码使用的就是django提供的缓存api
一.配置缓存 https://www.jb51.net/article/124434.htm 二.缓存全站.页面.局部 三.自我控制的简单缓存API API 接口为:django.core.c ...
- 深入理解 Node.js 中 EventEmitter源码分析(3.0.0版本)
events模块对外提供了一个 EventEmitter 对象,即:events.EventEmitter. EventEmitter 是NodeJS的核心模块events中的类,用于对NodeJS中 ...
- 从 sourcemap 中获取源码
使用 paazmaya/shuji: Reverse engineering JavaScript and CSS sources from sourcemaps 可以从 sourcemap 中获取源 ...
随机推荐
- webpack 安装vue(两种代码模式compiler 和runtime)
使用webpack安装vue,import之后,运营项目报错,如下: [Vue warn]: You are using the runtime-only build of Vue where the ...
- bootstrap-switch:记一次很坑的问题(连续相同状态的多行数据只有第一个显示按钮,其他行没有开关初始化)
先上截图,第234行都是禁用状态,但是只有第2行显示了禁用开关,后面的都没有开关初始化 检查下代码: onLoadSuccess: function(data){ {#获取行数据的状态#} conso ...
- C/C++文件操作经验总结
最近在做一个从groundtruth_rect.txt中读取按行存储的矩形元素(x, y, w, h),文本存储的格式如下: 310,102,39,50 308,100,39,50 306,99,39 ...
- element组件 MessageBox不能显示确认和取消按钮,记录正确使用方法!
这里是局部引入 调用方式:
- react-native 上拉加载
import React, {Component} from 'react'; import {View, ScrollView, Text, Dimensions, Image} from 'rea ...
- Java注解-注解处理器、servlet3.0|乐字节
大家好,我是乐字节的小乐,上次给大家带来了Java注解-元数据.注解分类.内置注解和自定义注解|乐字节,这次接着往下讲注解处理器和servlet3.0 一.注解处理器 使用注解的过程中,很重要的一部分 ...
- servlet02
内容 1servlet 2HTTP协议 3Request servlet继承的体系结构 抽象类 | GenericServlet:将servlet接口中其他方法默认空实现,只将servic ...
- 修改 ubuntu NTFS 文件系统下没有执行权限的问题
由于NTFS本身的特殊性,不能对其分区的文件权限进行修改,无论是sudo还是root都没有用. 安装以下两个插件解决问题: sudo apt-get install ntfs-3g //这个12.04 ...
- Deepin中安装docker
1.sudo apt install docker-ce: 2.安装好后可以用docker version查看一下是否成功,还可以通过网络详情里是否多了一个docker0来判断: 3.sudo use ...
- 【转帖】linux内存管理原理深入理解段式页式
linux内存管理原理深入理解段式页式 https://blog.csdn.net/h674174380/article/details/75453750 其实一直没弄明白 linux 到底是 段页式 ...