NLP语言学基础
不同的自然语言有不同的语法结构,因此需要对语言数据进行语法解析,才能让机器更准确地学到相应的模式。而语言不同于图像,数据标注工作需要有一定的语言学知识,因此数据的整理也相对更困难。下面以英语为例(别的咱也看不懂),对NLP研究中常见的基本语言学概念进行记录。
词性(Part Of Speech)
词性(Part Of Speech, POS)通常在初中就学过:名词、动词、形容词、副词等,这里不再赘述。由于同一个词有多种不同词性的可能,因此数据标注时对语句中各个词的词性的标注就十分重要,从而消除词性歧义。如:
There are many chairs in the room.
He chairs the weekly meeting.
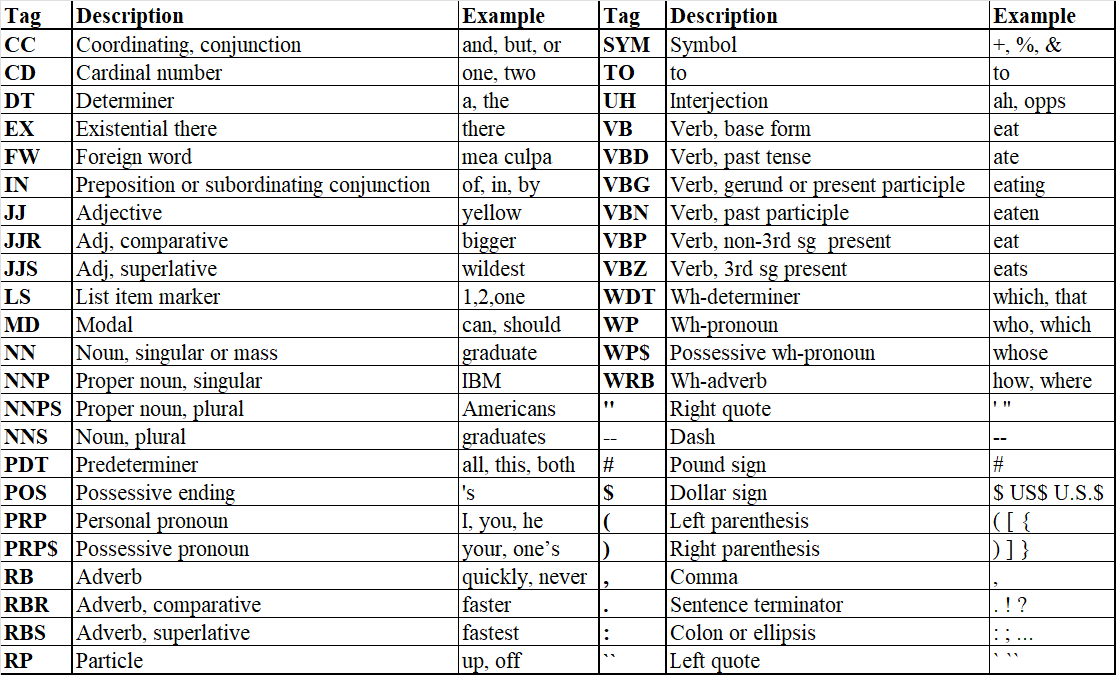
两个chairs分别是名词和动词。以下是宾夕法尼亚大学定义的词性标签(Penn Treebank POS Tags),NLP数据集中常用于语句中词性的分类:
短语结构语法(Phrase Structure Grammar)
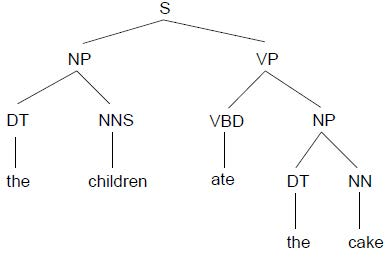
短语结构语法是一种重写规则,用于描述给定语言的句法,从而消除语法歧义。这是一种基于成分的语法(constituency-based),每次分解对应的词汇可以有多个(与下面的依赖语法不同)。一般来说,每个句子(Sentence, S)都能被分为主语(名词短语, Noun Phrase, NP)和谓语(动词短语, Verb Phrase, VP)。NP和VP则能被进一步分解更小的NP和VP,或最终分解为不可分解的某种性质的词汇。例子如下:
The children ate the cake.
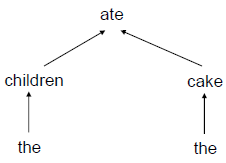
依存语法(Dependency Grammar)
依存语法将句子每个词汇看做是互相依赖的关系,因此每次分解只对应一个词汇。具体分解方式先占个坑,以后再记录。
NLP语言学基础的更多相关文章
- NLP&数据挖掘基础知识
Basis(基础): SSE(Sum of Squared Error, 平方误差和) SAE(Sum of Absolute Error, 绝对误差和) SRE(Sum of Relative Er ...
- NLP传统基础(1)---BM25算法---计算文档和query相关性
一.简介:TF-IDF 的改进算法 https://blog.csdn.net/weixin_41090915/article/details/79053584 bm25 是一种用来评价搜索词和文档之 ...
- NLP传统基础(3)---潜在语义分析LSA主题模型---SVD得到降维矩阵
https://www.jianshu.com/p/9fe0a7004560 一.简单介绍 LSA和传统向量空间模型(vector space model)一样使用向量来表示词(terms)和文档(d ...
- NLP传统基础(2)---LDA主题模型---学习文档主题的概率分布(文本分类/聚类)
一.简介 https://cloud.tencent.com/developer/article/1058777 1.LDA是一种主题模型 作用:可以将每篇文档的主题以概率分布的形式给出[给定一篇文档 ...
- Deep Learning in NLP (一)词向量和语言模型
原文转载:http://licstar.net/archives/328 Deep Learning 算法已经在图像和音频领域取得了惊人的成果,但是在 NLP 领域中尚未见到如此激动人心的结果.关于这 ...
- Deep Learning In NLP 神经网络与词向量
0. 词向量是什么 自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化. NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representati ...
- Word2Vec之Deep Learning in NLP (一)词向量和语言模型
转自licstar,真心觉得不错,可惜自己有些东西没有看懂 这篇博客是我看了半年的论文后,自己对 Deep Learning 在 NLP 领域中应用的理解和总结,在此分享.其中必然有局限性,欢迎各种交 ...
- 【NLP】自然语言处理:词向量和语言模型
声明: 这是转载自LICSTAR博士的牛文,原文载于此:http://licstar.net/archives/328 这篇博客是我看了半年的论文后,自己对 Deep Learning 在 NLP 领 ...
- 自然语言处理(NLP)入门学习资源清单
Melanie Tosik目前就职于旅游搜索公司WayBlazer,她的工作内容是通过自然语言请求来生产个性化旅游推荐路线.回顾她的学习历程,她为期望入门自然语言处理的初学者列出了一份学习资源清单. ...
- (Stanford CS224d) Deep Learning and NLP课程笔记(二):word2vec
本节课将开始学习Deep NLP的基础--词向量模型. 背景 word vector是一种在计算机中表达word meaning的方式.在Webster词典中,关于meaning有三种定义: the ...
随机推荐
- 【Mac渗透测试】之SQL注入Demo
目录: 一.下载安装sqlmap 二.SQL注入 三.参考文章 一.下载安装sqlmap 1.官网地址:http://sqlmap.org/#download git下载: git clone --d ...
- 专业级语义搜索优化:利用 Cohere AI、BGE Re-Ranker 及 Jina Reranker 实现精准结果重排
专业级语义搜索优化:利用 Cohere AI.BGE Re-Ranker 及 Jina Reranker 实现精准结果重排 1. 简介 1.1 RAG 在说重排工具之前,我们要先了解一下 RAG. 检 ...
- 利用CSS 实现环形百分比进度展示
先看效果图: UI设计了这样的效果,已读人数占总人数的百分比,环形展示. 这里可以用echarts图表,也可以用css实现,因为我是在小程序环境下,考虑到包大小体积,采用了css实现. 核心就是一行代 ...
- CA-TCC: 半监督时间序列分类的自监督对比表征学习《Self-supervised Contrastive Representation Learning for Semi-supervised Time-Series Classification》(时间序列、时序表征、时间和上下文对比、对比学习、自监督学习、半监督学习、TS-TCC的扩展版)
现在是2023年11月27日,10:48,今天把这篇论文看了. 论文:Self-supervised Contrastive Representation Learning for Semi-supe ...
- Spring —— 整合MyBatis
MyBatis核心程序 配置文件 整合MyBatis
- 【赵渝强老师】使用kubeadmin部署K8s集群
首先,我们来看一下整体的架构. K8s的部署方式: yum方式部署 二进制包:手动使用tar包来部署 minikube:单机版,用于开发测试. kubeadm:可以把kubeadmin看成一个部署工具 ...
- 国庆快乐!附ssh实战
小伙伴们,有一段时间没更新了,目前在中科院软件所实习,在这里我祝大家国庆快乐! 今天这一期带来ssh命令的实战教程,ssh在工作当中遇到的非常多,因为总是需要登服务器,而且玩法也有不少,这是我常用的几 ...
- Nuxt.js 应用中的 app:beforeMount 钩子详解
title: Nuxt.js 应用中的 app:beforeMount 钩子详解 date: 2024/10/4 updated: 2024/10/4 author: cmdragon excerpt ...
- TEN Framework 入坑记
TL;DR TEN Framework 最初叫 Astra,后改为 TEN,即 Transformative Extensions Network. 我第一次见到 TEN (那时还叫 Astra)是在 ...
- 简化部署流程:Rainbond让Jeepay支付系统部署更轻松
在如今的开发环境中,部署一套像 Jeepay 这样的 Java 支付系统往往需要开发者面对繁琐的配置.依赖环境管理以及服务的高可用性保障,手动部署和运维变得异常艰巨和费时.然而,借助 Rainbond ...