One Class SVM 对于样本不均衡处理思路——拿出白样本建模,算出outlier,然后用黑去检验效果
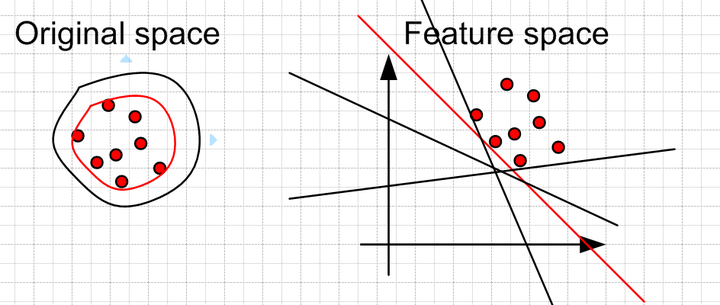
One Class SVM 是指你的training data 只有一类positive (或者negative)的data, 而没有另外的一类。在这时,你需要learn的实际上你training data 的boundary。而这时不能使用 maximum margin 了,因为你没有两类的data。 所以呢,在这边文章中,“Estimating the support of a high-dimensional distribution”, Schölkopf 假设最好的boundary要远离feature space 中的原点。
左边是在original space中的boundary,可以看到有很多的boundary 都符合要求,但是比较靠谱的是找一个比较 紧(closeness) 的boundary (红色的)。这个目标转换到feature space 就是找一个离原点比较远的boundary,同样是红色的直线。当然这些约束条件都是人为加上去的,你可以按照你自己的需要采取相应的约束条件。比如让你data 的中心离原点最远。
这些都是我个人的理解,我不是专门研究machine learning的。如有不妥之处,还望指出。
1、sklearn中关于异常检测的说法
Novelty and Outlier Detection:
Many applications require being able to decide whether a new observation belongs to the same distribution as existing observations (it is an inlier), or should be considered as different (it is an outlier). Often, this ability is used to clean real data sets. Two important distinction must be made:
novelty detection:
The training data is not polluted by outliers, and we are interested in detecting anomalies in new observations.
outlier detection:
The training data contains outliers, and we need to fit the central mode of the training data, ignoring the deviant observations.
也就是说主要方法有两种:
1)、novelty detection:当训练数据中没有离群点,我们的目标是用训练好的模型去检测另外新发现的样本;
2)、outlier detection:当训练数据中包含离群点,模型训练时要匹配训练数据的中心样本,忽视训练样本中的其它异常点;
sklearn提供了一些机器学习方法,可用于奇异(Novelty )点或异常(Outlier)点检测,包括OneClassSVM、Isolation Forest、Local Outlier Factor (LOF) 等。其中OneClassSVM可用于Novelty Detection,而后两者可用于Outlier Detection。
2、OneClassSVM(Unsupervised Outlier Detection)
2.1、关于一类SVM的形象解释:
作者:知乎用户
链接:https://www.zhihu.com/question/22365729/answer/115048306
最近因为做到异常行为检测、剧烈运动分析方面的任务,接触到了一类svm,尽我所能的介绍下我掌握的知识吧。先举个例子。比方说,我们要判断一张照片里的人脸,是男性还是女性,这是个二分类问题。对于一张未知性别的人脸,经过svm分类器分类(经典的二分类svm),我们会给出他\她是男性or不是男性的结果(不是男性就是女性啦,暂时不考虑第三性别,O(∩_∩)O~;为什么这么表达,是因为为了与下面的一类svm概念做区别)。那么经典svm训练的方式呢,就是将一堆已标注了男女性别的人脸照片(假设男性是正样本,女性是负样本),提取出有区分性别的特征(假设这种能区分男女性别的特征已构建好)后,通过svm中的支持向量,找到这男女两类性别特征点的最大间隔。进而在输入一张未知性别的照片后,经过特征提取步骤,就可以通过这个训练好的svm很快得出照片内人物的性别,此时我们得出的结论,我们知道要么是男性,不是男性的话,那一定是女性。以上情况是假设,我们用于训练的样本,包括了男女两类的图片,并且两类图片的数目较为均衡。现实生活中的我们也是这样,我们只有在接触了足够多的男生女生,知道了男生女生的性别特征差异后(比方说女性一般有长头发,男性一般有胡子等等),才能准确判断出这个人到底是男是女。但如果有一个特殊的场景,比方说,有一个小和尚,他从小在寺庙长大,从来都只见过男生,没见过女生,那么对于一个男性,他能很快地基于这个男性与他之前接触的男性有类似的特征,给出这个人是男性的答案。但如果是一个女性,他会发现,这个女性与他之前所认知的男性的特征差异很大,进而会得出她不是男性的判断。注意咯,这里所说的 “她不是男性” 的判断,与我们使用二分类svm中所说的 “不是男性” 的判断,虽然结论相同,但却不是同一个概念。 我们在使用经典二分类svm去分类人脸性别时,当我们判定未知样本不是男性时,我们会同时得到她是个女性的结论(因为我们是知道另一类,也即女性类别的),但对于以上介绍的特殊场景,我们只能根据它与小和尚认知的男性特征不一致,得出它不是男性的判断,至于它是女性呢,还是第三性别,甚至是外星人,对不起,并不知道,我们只能将其排除出男性的范围,并不能给它做出属于哪类的决策。以上场景就是一类svm的典型应用场景,当出现一个分类问题中,只有一种类型的样本,或有两种类型样本,但其中一类型样本数目远少于另一类型样本数目(如果此时采用二分类器,training set中正负样本不均衡,可能造成分类器过于偏向数目多的样本类别,使train出来的model有bias)时,就可以考虑使用一类svm进行分类。再举例子到异常行为检测上,比方说,在银行存取款大厅,正常情况大家都是在坐席耐心叫号等待,抑或取号,在柜台接受服务等。这些行为虽然各有不同,但却都会有比较相类似的特征,例如都会有比较一致性的运动方向(比如说,正常走动,取号,排队等),不是很大的运动幅度等,但对于一些异常行为,比如说银行大厅内的打斗、斗殴,抢劫等,你不能要求这些行为也按套路出牌,如武侠片里先摆pos、再出脚,最后再手上各种招式,正是因为这些异常行为无法有效度量。我们就可以将一类svm应用于其中,比方说,我们提取出人类在银行的正常行为操作的特征,并使用一类svm将之正确表达,那么对于一个异常行为,我们可以很快得出,这货提取的特征和我这个分类器包含的特征不一致,那么它肯定就不是正常的行为特征,那么就可以发出报警了。以上就是我口语表达的一类svm分类器的介绍,有很多不严谨的地方,望海涵。
2.2、OneClassSVM主要参数和方法
class sklearn.svm.OneClassSVM(kernel=’rbf’, degree=3, gamma=’auto’, coef0=0.0, tol=0.001, nu=0.5, shrinking=True, cache_size=200, verbose=False, max_iter=-1, random_state=None)
参数:
kernel:核函数(一般用高斯核)
nu:设定训练误差(0, 1]
方法:
fit(x):训练,根据训练样本和上面两个参数探测边界。(注意是无监督哦!)
predict(x):返回预测值,+1就是正常样本,-1为异常样本。
decision_function(X):返回各样本点到超平面的函数距离(signed distance),正的为正常样本,负的为异常样本。
2.3、OneClassSVM官方实例
#!/usr/bin/python
# -*- coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager
from sklearn import svm
xx, yy = np.meshgrid(np.linspace(-5, 5, 500), np.linspace(-5, 5, 500))
# Generate train data
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
# plot the line, the points, and the nearest vectors to the plane
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.title("Novelty Detection")
plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 7), cmap=plt.cm.PuBu) #绘制异常样本的区域
a = plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='darkred') #绘制正常样本和异常样本的边界
plt.contourf(xx, yy, Z, levels=[0, Z.max()], colors='palevioletred') #绘制正常样本的区域
s = 40
b1 = plt.scatter(X_train[:, 0], X_train[:, 1], c='white', s=s, edgecolors='k')
b2 = plt.scatter(X_test[:, 0], X_test[:, 1], c='blueviolet', s=s,
edgecolors='k')
c = plt.scatter(X_outliers[:, 0], X_outliers[:, 1], c='gold', s=s,
edgecolors='k')
plt.axis('tight')
plt.xlim((-5, 5))
plt.ylim((-5, 5))
plt.legend([a.collections[0], b1, b2, c],
["learned frontier", "training observations",
"new regular observations", "new abnormal observations"],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11))
plt.xlabel(
"error train: %d/200 ; errors novel regular: %d/40 ; "
"errors novel abnormal: %d/40"
% (n_error_train, n_error_test, n_error_outliers))
plt.show()
结果:
3、总结
1、严格地讲,OneClassSVM不是一种outlier detection方法,而是一种novelty detection方法:它的训练集不应该掺杂异常点,因为模型可能会去匹配这些异常点。 但在数据维度很高,或者对相关数据分布没有任何假设的情况下,OneClassSVM也可以作为一种很好的outlier detection方法。
2、其实在分类问题中,当两类样本及其不平衡时,也可以将个数比例极小的那部分当做异常点来处理,从另外一种角度来完成分类任务!
4、参考文献:
1、http://scikit-learn.org/stable/modules/outlier_detection.html#outlier-detection
---------------------
作者:夕阳下江堤上的男孩
来源:CSDN
原文:https://blog.csdn.net/YE1215172385/article/details/79750703
版权声明:本文为博主原创文章,转载请附上博文链接!
补充:
在机器学习中,(高斯)径向基函数核(英语:Radial basis function kernel),或称为RBF核,是一种常用的核函数。它是支持向量机分类中最为常用的核函数。[1]
关于两个样本x和x'的RBF核可表示为某个“输入空间”(input space)的特征向量,它的定义如下所示:[2]
- {\displaystyle K(\mathbf {x} ,\mathbf {x'} )=\exp \left(-{\frac {||\mathbf {x} -\mathbf {x'} ||_{2}^{2}}{2\sigma ^{2}}}\right)}

{\displaystyle \textstyle ||\mathbf {x} -\mathbf {x'} ||_{2}^{2}}



- {\displaystyle K(\mathbf {x} ,\mathbf {x'} )=\exp(-\gamma ||\mathbf {x} -\mathbf {x'} ||_{2}^{2})}

因为RBF核函数的值随距离减小,并介于0(极限)和1(当x = x'的时候)之间,所以它是一种现成的相似性度量表示法。[2] 核的特征空间有无穷多的维数;对于{\displaystyle \sigma =1}
- {\displaystyle \exp \left(-{\frac {1}{2}}||\mathbf {x} -\mathbf {x'} ||_{2}^{2}\right)=\sum _{j=0}^{\infty }{\frac {(\mathbf {x} ^{\top }\mathbf {x'} )^{j}}{j!}}\exp \left(-{\frac {1}{2}}||\mathbf {x} ||_{2}^{2}\right)\exp \left(-{\frac {1}{2}}||\mathbf {x'} ||_{2}^{2}\right)}

One Class SVM 对于样本不均衡处理思路——拿出白样本建模,算出outlier,然后用黑去检验效果的更多相关文章
- 思科恶意加密TLS流检测论文记录——由于样本不均衡,其实做得并不好,神马99.9的准确率都是浮云啊,之所以思科使用DNS和http一个重要假设是DGA和HTTP C&C(正常http会有图片等)。一开始思科使用的逻辑回归,后面17年文章是随机森林。
论文记录:Identifying Encrypted Malware Traffic with Contextual Flow Data from:https://songcoming.github. ...
- Python:SMOTE算法——样本不均衡时候生成新样本的算法
Python:SMOTE算法 直接用python的库, imbalanced-learn imbalanced-learn is a python package offering a number ...
- 为什么ROC曲线不受样本不均衡问题的影响
转自:https://blog.csdn.net/songyunli1111/article/details/82285266 在对分类模型的评价标准中,除了常用的错误率,精确率,召回率和F1度量外, ...
- 【小白学AI】八种应对样本不均衡的策略
文章来自:微信公众号[机器学习炼丹术] 目录 1 什么是非均衡 2 8种解决办法 2.1 重采样(四种方法) 2.2 调整损失函数 2.3 异常值检测框架 2.4 二分类变成多分类 2.5 EasyE ...
- Bert文本分类实践(三):处理样本不均衡和提升模型鲁棒性trick
目录 写在前面 缓解样本不均衡 模型层面解决样本不均衡 Focal Loss pytorch代码实现 数据层面解决样本不均衡 提升模型鲁棒性 对抗训练 对抗训练pytorch代码实现 知识蒸馏 防止模 ...
- 机器学习 - 案例 - 样本不均衡数据分析 - 信用卡诈骗 ( 标准化处理, 数据不均处理, 交叉验证, 评估, Recall值, 混淆矩阵, 阈值 )
案例背景 银行评判用户的信用考量规避信用卡诈骗 ▒ 数据 数据共有 31 个特征, 为了安全起见数据已经向了模糊化处理无法读出真实信息目标 其中数据中的 class 特征标识为是否正常用户 (0 代表 ...
- 算法面经之讯飞+CVTE
一.科大讯飞(合肥) 概况:刚经历了科大讯飞的初面,大概35分钟左右,问的内容比较笼统,主要针对简历上的内容来,面试官比较亲切,回忆了一下面试内容. 建议:把简历上的内容整吧清楚,不知道的别瞎写,写了 ...
- 基于 Spark 的文本情感分析
转载自:https://www.ibm.com/developerworks/cn/cognitive/library/cc-1606-spark-seniment-analysis/index.ht ...
- 机器学习相关知识整理系列之二:Bagging及随机森林
1. Bagging的策略 从样本集中重采样(有放回)选出\(n\)个样本,定义子样本集为\(D\): 基于子样本集\(D\),所有属性上建立分类器,(ID3,C4.5,CART,SVM等): 重复以 ...
随机推荐
- mysql查询之上升的温度,有趣的电影,超过5名学生的课,大国,反转性别, 换座位
最近发现一个网站 力扣 查看 上面有很多算法和数据库的题目,做了一下,发现自己平时都疏忽了,因此边做边记录下来 1.上升的温度 给定一个 Weather 表,编写一个 SQL 查询,来查找与之前(昨天 ...
- Ubuntu查看与结束任务进程
1.打开终端 2.敲 ps -ef 查出进程的编号(就是PID那列) 3.输入 kill PID 即可(如果PID是123456,则kill 123456) 例如: 我想把splash关闭,直接输 ...
- jquery鼠标经过弹出层写法
jquery鼠标经过弹出层写法<pre><div class="navitem"><a href="/index.php?c=news&am ...
- 如何解决visual studio2017 install 下载安装极慢的问题
问题: visual studio 2017 下载安装速度慢,只有6.70kb/s.其他版本估计也有这个问题. 解决方案: 进入目录:C:\Windows\System32\drivers\etc 右 ...
- Python-16-继承、封装、多态
一.继承 1. 概念 继承是一种创建新类的方式,新建的类可以继承一个或多个父类(python支持多继承),父类又可称为基类或超类,新建的类称为派生类或子类. 子类会“”遗传”父类的属性,从而解决代码重 ...
- AspNetCore Redis实现分布式缓存
分布式缓存描述: 分布式缓存重点是在分布式上,相信大家接触过的分布式有很多中,像分布式开发,分布式部署,分布式锁.事物.系统 等有很多.使我们对分布式本身就有一个很明确的认识,分布式就是有多个应用程序 ...
- 基于CentOS6.5的Dubbo及Zookeeper配置
基于CentOS的Dubbo及Zookeeper配置 需要提前准备好的资料: 1.首先配置java环境 步骤: 将jdk的包上传至centos服务器的/opt目录下,并且解压 tar -zxvf jd ...
- springboot 2.1.3.RELEASE添加filter,servlet源码学习
Servlet规范中,通过ServeltContext来注册Filter.Servlet,这里分析Filter,Servlet是相同逻辑 springboot2.0中,我们通过 FilterRegis ...
- Spring AOP创建Throwdvice实例
1.异常发生的时候,通知某个服务对象做处理 2.实现throwsAdvice接口 接口实现: public interface IHello { public void sayHello(String ...
- java之hibernate之组件映射
1.在开发中,有的类信息比较复杂,而且某几个信息可以组成某一个部分,这个时候可以采用组件映射,组件映射是一张表映射到多个类.表结构 2.类的设计 Link.java public class Link ...