elasticsearch 的入门
参考文档
1.全文搜索引擎 Elasticsearch 入门教程(http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html)
2.elasticsearch的一次体验——1.Java环境的安装(https://blog.csdn.net/lowerxiaoshen/article/details/79208758)
3.Elasticsearch 权威指南(中文版)(https://es.xiaoleilu.com/)
要使用 elasticsearch 必须安装 java8 相关环境
1.去java官网下载jdk8 java环境官方下载地址(https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)
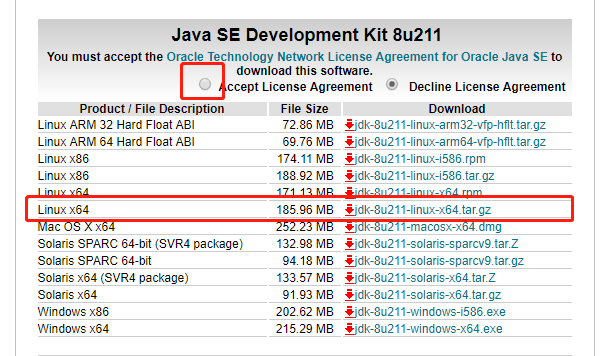
2.将下载好的压缩包上传到服务器。在这里可以选择安装ftp服务,也可以使用在线导入安装包的插件。
3.解压文件并添加添加环境变量
通过 vim /etc/profile 命令打开 profile 文件盘配置环境变量
文本最后添加
export JAVA_HOME=/home/lxshen/java/jdk1..0_161 #这个是自己的java文件的位置
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
保存完之后输入:source /etc/profile 命令使刚才配置的环境变量生效
4.查看Java环境是否安装成功

到这里说明Java环境安装成功。
安装 elasticsearch 相关环境
1. 安装完 Java,就可以跟着官方文档安装 Elastic。直接下载压缩包比较简单。
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.5.1.zip
$ unzip elasticsearch-5.5..zip
$ cd elasticsearch-5.5./
2.接着,进入解压后的目录,运行下面的命令,启动 Elastic。
$ ./bin/elasticsearch
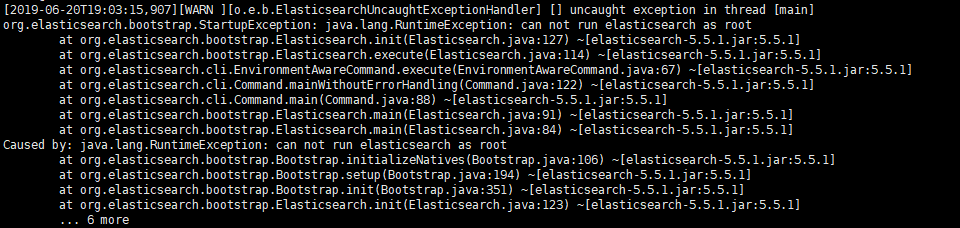
3.如果这时报错"max virtual memory areas vm.maxmapcount [65530] is too low",要运行下面的命令。
$ sudo sysctl -w vm.max_map_count=
如果出现这个错误,是因为使用root用户启动elasticsearch,elasticsearch是不允许使用root用户启动的,所以我们需要添加用户。
创建新用户
创建一个用户名为:linuxidc [root@localhost ~]# adduser linuxidc
为这个用户初始化密码,linux会判断密码复杂度,不过可以强行忽略: [root@localhost ~]# passwd linuxidc
更改用户 zhangbiao 的密码 。
新的 密码:
无效的密码: 密码未通过字典检查 - 过于简单化/系统化
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
centos系统添加/删除用户和用户组(https://blog.csdn.net/qq_31279347/article/details/82696731)
CentOS 7中添加一个新用户并授权(https://www.linuxidc.com/Linux/2016-11/137549.htm)
adduser *** //添加用户
passwd *** //给用户赋值
添加完用户之后:
用root用户执行 : chown -R 文件夹名 用户名
将这几个压缩包所在的文件夹及解压完的文件夹权限给你新建的用户。之后再使用新用户启动就OK了。
其他几个问题:https://segmentfault.com/a/1190000011899522
问题一
max virtual memory areas vm.max_map_count [] is too low, increase to at least []
max_map_count 的值是指一个进程最多可用于的内存映射区(memory map areas),在调用malloc会用到,由mmap/mprotect生成。
解决办法:
切换到root用户修改配置/etc/sysctl.conf
su root
vim /etc/sysctl.conf
加入
vm.max_map_count=
然后使其生效
sysctl -p
问题二
[]: max file descriptors [] for elasticsearch process is too low, increase to at least []
文件描述符太低
解决办法:
切换到root用户修改/etc/security/limits.conf
su root
vim /etc/security/limits.conf
加入
* soft nofile
* hard nofile
* soft nproc
* hard nproc
问题三
使用supervisor启动时,查看日志仍然报下面的错误
[]: max file descriptors [] for elasticsearch process is too low, increase to at least []
解决办法:
切换到root用户修改vim /etc/supervisord.d/elasticsearch.conf
[supervisord]
minfds=
minprocs= [program:es]
process_name=%(program_name)s_%(process_num)02d
directory=/usr/local/elasticsearch-5.6./
command=/usr/local/elasticsearch-5.6./bin/elasticsearch
;autostart=true
autorestart=false
user=testuser
numprocs=
4.如果一切正常,Elastic 就会在默认的9200端口运行。这时,打开另一个命令行窗口,请求该端口,会得到说明信息。
$ curl localhost:
{
"name" : "atntrTf",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "tf9250XhQ6ee4h7YI11anA",
"version" : {
"number" : "5.5.1",
"build_hash" : "19c13d0",
"build_date" : "2017-07-18T20:44:24.823Z",
"build_snapshot" : false,
"lucene_version" : "6.6.0"
},
"tagline" : "You Know, for Search"
}
上面代码中,请求9200端口,Elastic 返回一个 JSON 对象,包含当前节点、集群、版本等信息。
按下 Ctrl + C,Elastic 就会停止运行。
默认情况下,Elastic 只允许本机访问,如果需要远程访问,可以修改 Elastic 安装目录的config/elasticsearch.yml文件,去掉network.host的注释,将它的值改成0.0.0.0,然后重新启动 Elastic。
network.host: 0.0.0.0
上面代码中,设成0.0.0.0让任何人都可以访问。线上服务不要这样设置,要设成具体的 IP。
ELK(elasticsearch+logstash+kabana)安装及简单入门
https://blog.csdn.net/lck5602/article/details/79673087
ElasticSearch安装
1、下载安装包
https://www.elastic.co/downloads/elasticsearch
wget https://www.elastic.co/downloads/elasticsearch
2、解压到文件夹
tar -zxvf elasticsearch-5.2..tar.gz -C /bigdata/
3、修改配置文件(在安装目录的config目录下)
编辑配置文件elasticsearch.yml(配置es的相关配置)
vi /bigdata/elasticsearch-5.2.2/config/elasticsearch.yml 修改
cluster.name: ELK #集群名称,以此作为是否是同意集群的判断
node.name: es- #节点名称,以此作为集群中不同节点的分区条件
path.data: /data/es/data #数据存储地址
path.logs: /data/es/logs #日志存储地址
network.host: 192.168.1.34 #(主机地址)对外发布的网络地址
http.port: #ES默认监听的端口
discovery.zen.ping.unicast.hosts: ["node01"]
编辑配置文件jvm.options(jvm的相关配置)
IMPORTANT: JVM heap size #配置jvm的大小(默认配置是2G)
-Xms2g
-Xmx2g
编辑配置文件log4j2.properties(日志打印输出相关配置,一般不需要修改)
配置文件的参数也可以在启动的时候指定
例如:bin/elasticsearch -Ehttp.port=19200
本地快速启动集群
bin/elasticsearch #默认的配置启动
bin/elasticsearch -Ehttp.port= #修改端口号为19200启动
#看到started说明集群启动成功
输入:http://ip:port 查看Elasticsearch服务状态
查看节点时候组成集群,在浏览器中输入http://ip:port/_cat/nodes
例如:
http:192.168.1.31:/_cat/nodes
查看集群相关信息,执行http://ip:port/_cluster/stats
http://192.168.1.31:9200/_cluster/stats
4、elasticsearch常用术语
Document文档数据(就是具体存在ES中的一条数据)
Index索引(可以理解为mysql中的数据库)
Type索引中的数据类型(可以理解为mysql中的table)
Field字段,文档的属性
Query DSL查询语法
5、Elasticsearch中CRUD操作
Create创建文档
POST /accounts/person/ { "name":"John", "lastname":"Doe", "job_description":"Systems asministrator and Linux specialit" }
#accounts 相当于索引Index
#person 相当于类型Type Read读取文档 GET /accounts/person/ update更新文档 POST /accounts/person//_update { "name":"John", "lastname":"Doe", "job_description":"Systems asministrator and Linux specialit" } Delete删除文档 DELETE /accounts/person/
6、ElasticSearch 中Query语法
第一种Query String
GET /accounts/person/_search?q=john
第二种Query DSL
GET /accounts/person/_search { "query" :{ "match" :{ "name" : "john" } } }
Kabana安装
1、下载kabana
https://www.elastic.co/downloads/kibana
2、解压缩
tar -zxvf kibana-6.2.-darwin-x86_64.tar.gz -C /bigdata/
3、修改配置文件安装启动
修改config/kibana.yml
server.port: # Kibana对外访问的端口
server.host: "192.168.1.31" #Kibana对外访问的地址
elasticsearch.url: "http://192.168.1.31:9200" #Kibana需要访问的ElasticSearch的地址 启动服务后,看到server running的时候说明已经跑起来了
4、kabana常用功能
Discover数据搜索查看
Visualize图表制作
Dashboard仪表盘制作
Timelion时序数据的高级可视化分析
DevTools开发者工具(经常会用到)
Managerment配置管理
LogStash使用
1、下载
https://www.elastic.co/downloads/logstash
2、解压缩
3、准备logstash 配置文件
input { stdin { } }
output {
elasticsearch { hosts => ["127.0.0.1:9200"] }
stdout { codec => rubydebug }
}
4、启动
logstash -f logstash.conf
elasticsearch 的入门的更多相关文章
- Elasticsearch 基础入门
原文地址:Elasticsearch 基础入门 博客地址:http://www.extlight.com 一.什么是 ElasticSearch ElasticSearch是一个基于 Lucene 的 ...
- Elasticsearch从入门到放弃:分词器初印象
Elasticsearch 系列回来了,先给因为这个系列关注我的同学说声抱歉,拖了这么久才回来,这个系列虽然叫「Elasticsearch 从入门到放弃」,但只有三篇就放弃还是有点过分的,所以还是回来 ...
- Elasticsearch 教程--入门
1.1 初识 Elasticsearch 是一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎,可以说 Lucene 是当今最先进,最高效的全功能开源搜索引擎框架. 但是 L ...
- 转:ElasticSearch 简单入门
原文来自于:http://www.oschina.net/translate/elasticsearch-getting-started?cmp 教程样例 我们将要部署一个非常简单的应用--在一个部门 ...
- Elasticsearch从入门到精通-Elasticsearch是什么
作者其他ELK快速入门系列文章 logstash快速入门实战指南 Kibana从入门到精通 一.前言 驱动未来商业发展的最重要“能源”不是石油,而是数据.我们还来不及了解它,这个世界已经被它淹没.多年 ...
- ElasticSearch 简单入门
英文原文:Getting Started with ElasticSearch 原文链接:http://www.oschina.net/translate/elasticsearch-getting- ...
- Elasticsearch快速入门案例
写在前面的话:读书破万卷,编码如有神-------------------------------------------------------------------- 参考内容: <Ela ...
- elasticsearch 官方入门 及 API
https://www.elastic.co/guide/en/elasticsearch/reference/current/_basic_concepts.html 入门地址 ElasticSea ...
- elasticsearch从入门到出门-02-简单的CRUD
操作背景: 电商网站上面的一个商品的增删改查: es 能接受的都是JSON格式的数据 Es 提供了一套简单的集群信息健康监控的api GET /_cat/health?v epoch t ...
随机推荐
- springboot 使用常用注解
找到方法封装成json格式 @RestController = @Controller+@ResponseBody //一个组合注解,用于快捷配置启动类,springboot启动主入口 @Spring ...
- Flink原理(四)——任务及调度
本文是博主阅读官网文档.博客及书籍后自己所思所得,若是存在有误的地方,欢迎留言分享,谢谢! 一.任务调度 Flink是通过task slot的来定义执行资源的,为优化资源的利用率,Flink通过slo ...
- HTML&CSS基础-子元素的伪类选择器
HTML&CSS基础-子元素的伪类选择器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.html的源代码 <!DOCTYPE html> <html& ...
- pyspark minHash LSH 查找相似度
先看看官方文档: MinHash for Jaccard Distance MinHash is an LSH family for Jaccard distance where input feat ...
- [牛客网 -leetcode在线编程 -02] minimum-depth-of-binary-tree -树的最短深度
题目描述 题目描述 Given a binary tree, find its minimum depth.The minimum depth is the number of nodes along ...
- Golang : Forwarding a local port to a remote server example
原文:https://socketloop.com/tutorials/golang-forwarding-a-local-port-to-a-remote-server-example 端口转发, ...
- 《发际线总是和我作队》第九次团队作业:Beta冲刺Scrum Meeting2
项目 内容 这个作业属于哪个课程 软件工程 这个作业的要求在哪里 实验十三 团队作业9:Beta冲刺与团队项目冲刺 团队名称 发际线总和我作队 作业学习目标 (1)掌握软件黑盒测试技术:(2)掌握软件 ...
- 关于List集合中元素排序问题
问题描述: 有一个list集合,其中元素是Student对象,根据student的age排序. Student对象 /** * description * * @author 70KG * @date ...
- jmeter 压测工具安装及使用
linux下jmeter安装: 1. 下载JMeter官方网站下载最新版本: http://jmeter.apache.org/download_jmeter.cgi ,目前最新版是Apache JM ...
- shellshock溢出攻击
实验背景 2014年9月24日,Bash中发现了一个严重漏洞shellshock,该漏洞可用于许多系统,并且既可以远程也可以在本地触发.在本实验中,需要亲手重现攻击来理解该漏洞,并回答一些问题. 什么 ...