动态查找之二叉树查找 c++实现
算法思想
二叉搜索树(又称二叉查找树或二叉排序树)BST树
二叉查找树
二叉查找树,也称二叉搜索树,或二叉排序树。其定义也比较简单,要么是一颗空树,要么就是具有如下性质的二叉树:
(1)若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2) 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(3) 任意节点的左、右子树也分别为二叉查找树;
(4) 没有键值相等的节点。
二叉查找树的性质总结:
a.二叉查找树还有一个性质,即对二叉查找树进行中序遍历,即可得到有序的数列。
b.二叉查找树的查询复杂度,和二分查找一样,插入和查找的时间复杂度均为 O(logn) ,但是在最坏的情况下仍然会有 O(n) 的时间复杂度。原因在于插入和删除元素的时候,树没有保持平衡。
具体实现:
/****
* BinarySortTree.
*
****/
#include"stdafx.h"
#include <iostream>
#include<queue>
using namespace std;
typedef struct node
{
int elem;
struct node* leftchild;
struct node* rightchild;
}BitNode,*BinTree;
//insert binary tree function
BinTree Insert_BinaryTree(BinTree &bt,int key)
{
if (bt == )
{
bt = new BitNode;
bt->elem = key;
bt->leftchild = ;
bt->rightchild = ;
return bt;
}
if (key < bt->elem)
{
bt->leftchild = Insert_BinaryTree(bt->leftchild,key);
}
else
{
bt->rightchild = Insert_BinaryTree(bt->rightchild, key);
}
return bt;
}
//for one search binary tree function
int Search_BinaryTree(BinTree &bt,int key)
{
if (bt == ) return ;
if (bt->elem == key) return ; if (key < bt->elem)
{
return Search_BinaryTree(bt->leftchild,key);
}
else
{
return Search_BinaryTree(bt->rightchild, key);
}
}
// for another one search binary tree function
int Search_BinaryTree(BinTree &bt, int key, BitNode ** p, BitNode** pf)
{
*p = bt;
*pf = ;
while (*p != )
{
if ((*p)->elem == key)
return ;
if ((*p)->elem > key)
{
*pf =*p;
*p = (*p)->leftchild;
}
else
{
*pf = *p;
*p = (*p)->rightchild;
}
}
return ;
}
//delete binary tree function
int Delete_BinaryTree(BinTree *bt,int key)
{
BitNode *p=*bt;
BitNode *pf=;
int findflag;
if (bt == ) return ;
findflag = Search_BinaryTree(*bt,key,&p,&pf);
if (findflag == ) return ;
//删除的节点是叶子节点
if (p->leftchild == && p->rightchild == )
{
if (pf == )
{
delete bt;
bt = ;
return ;
}
if (p == pf->leftchild)
{
pf->leftchild = ;
delete p;
p = ;
return ;
}
else
{
pf->rightchild = ;
delete p;
p = ;
return ;
}
}
//删除的节点只有一个子节点
if (p->leftchild == )
{
if (pf = )
{
*bt = p->rightchild;
delete p;
return ;
}
if(p==pf->leftchild)
{
pf->leftchild = p->rightchild;
delete p;
return ;
}
else
{
pf->rightchild = p->rightchild;
delete p;
return ;
}
} if (p->rightchild == )
{
if (p == pf->leftchild)
{
pf->leftchild = p->leftchild;
delete p;
return ;
}
if (p == pf->rightchild)
{
pf->rightchild = p->leftchild;
delete p;
return ;
}
}
//3.删除的节点含有两个子节点
BitNode * prf = p;
BitNode * pr = p->rightchild;
while (pr->leftchild != )
{
prf = pr;
pr = pr->leftchild;
}
if(prf == p)
{
p->elem = pr->elem;
prf->rightchild = pr->rightchild;
}
else
{
p->elem = pr->elem;
prf->leftchild = pr->rightchild;
}
delete pr;
return ; } //print binary tree function
void printTree(BitNode * bt)
{
queue<BitNode*> q;
q.push(bt);
while (!q.empty())
{
BitNode* p = q.front(); q.pop();
if (p)
{
cout << p->elem << "->";
q.push(p->leftchild);
q.push(p->rightchild);
}
}
cout << endl;
}
//test function
int main()
{
int a[] = { , , , , , , , , , }; // initialization and creat the Binary Sort Tree.
BinTree bt = ;
for (int i = ; i < ; i++)
{
bt = Insert_BinaryTree(bt, a[i]);
}
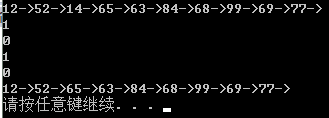
printTree(bt);
//search start.
cout << Search_BinaryTree(bt, ) << endl;
cout << Search_BinaryTree(bt, ) << endl; //delete start.
cout << Delete_BinaryTree(&bt, ) << endl; //search 14 again.
cout << Search_BinaryTree(bt, ) << endl;
printTree(bt);
system("pause");
return ;
}
动态查找之二叉树查找 c++实现的更多相关文章
- 查找算法(顺序查找、二分法查找、二叉树查找、hash查找)
查找功能是数据处理的一个基本功能.数据查找并不复杂,但是如何实现数据又快又好地查找呢?前人在实践中积累的一些方法,值得我们好好学些一下.我们假定查找的数据唯一存在,数组中没有重复的数据存在. (1)顺 ...
- 深入浅出数据结构C语言版(12)——从二分查找到二叉树
在很多有关数据结构和算法的书籍或文章中,作者往往是介绍完了什么是树后就直入主题的谈什么是二叉树balabala的.但我今天决定不按这个套路来.我个人觉得,一个东西或者说一种技术存在总该有一定的道理,不 ...
- 查找->静态查找表->次优查找(静态树表)
文字描算 之前分析顺序查找和折半查找的算法性能都是在“等概率”的前提下进行的,但是如果有序表中各记录的查找概率不等呢?换句话说,概率不等的情况下,描述查找过程的判定树为何类二叉树,其查找性能最佳? 如 ...
- 查找->静态查找表->折半查找(有序表)
文字描述 以有序表表示静态查找表时,可用折半查找算法查找指定元素. 折半查找过程是以处于区间中间位置记录的关键字和给定值比较,若相等,则查找成功,若不等,则缩小范围,直至新的区间中间位置记录的关键字等 ...
- 各种查找算法的选用分析(顺序查找、二分查找、二叉平衡树、B树、红黑树、B+树)
目录 顺序查找 二分查找 二叉平衡树 B树 红黑树 B+树 参考文档 顺序查找 给你一组数,最自然的效率最低的查找算法是顺序查找--从头到尾挨个挨个遍历查找,它的时间复杂度为O(n). 二分查找 而另 ...
- 算法与数据结构(九) 查找表的顺序查找、折半查找、插值查找以及Fibonacci查找
今天这篇博客就聊聊几种常见的查找算法,当然本篇博客只是涉及了部分查找算法,接下来的几篇博客中都将会介绍关于查找的相关内容.本篇博客主要介绍查找表的顺序查找.折半查找.插值查找以及Fibonacci查找 ...
- jvascript 顺序查找和二分查找法
第一种:顺序查找法 中心思想:和数组中的值逐个比对! /* * 参数说明: * array:传入数组 * findVal:传入需要查找的数 */ function Orderseach(array,f ...
- DNS 正向查找与反向查找
原创地址:http://www.cnblogs.com/jfzhu/p/3996323.html 转载请注明出处 所谓正向查找,就是说在这个区域里的记录可以依据名称来查找对应的IP地址.反向查找就是在 ...
- Java中常用的查找算法——顺序查找和二分查找
Java中常用的查找算法——顺序查找和二分查找 神话丿小王子的博客 一.顺序查找: a) 原理:顺序查找就是按顺序从头到尾依次往下查找,找到数据,则提前结束查找,找不到便一直查找下去,直到数据最后一位 ...
随机推荐
- Java 之 Object 类
一.Object 概述 java.lang.Object 类是 Java 语言中的根类,即所有类的父类. 在对象实例化的时候,最终找的父类就是 Object. 如果一个类没有特别指定父类,那么默认则 ...
- QT之Qt之Q_PROPERTY宏理解
在初学Qt的过程中,时不时地要通过F2快捷键来查看QT类的定义,发现类定义中有许多Q_PROPERTY的东西,比如最常用的QWidget的类定义: Qt中的Q_PROPERTY宏在Qt中是很常用的,那 ...
- web由http升级为https搭建
nginx实现http访问 server { listen default_server; listen [::]: default_server; server_name _; root /usr/ ...
- Spark(火花)快速、通用的大数据处理引擎框架
一.什么是Spark(火花)? 是一种快速.通用处理大数据分析的框架引擎. 二.Spark的四大特性 1.快速:Spark内存上采用DAG(有向无环图)执行引擎非循环数据流和内存计算支持. 内存上比M ...
- Beta冲刺第6次
二.Scrum部分 1. 各成员情况 翟仕佶 学号:201731103226 今日进展 新增图像拼接合并功能 存在问题 无 明日安排 视情况而定 截图 曾中杰 学号:201731062517 今日进展 ...
- 如何学习numpy
可以通过官方中文文档 NumPy 中文文档
- python 连接 redis cluster 集群
一. redis集群模式有多种, cluster模式只是其中的一种实现方式, 其原理请自行谷歌或者百度, 这里只举例如何使用Python操作 redis cluster 集群 二. python 连接 ...
- jmeter5.1企业级应用功能详解
apache jmeter是100%的java桌面应用程序,它被设计用来加载被测试软件功能特性.度量被测试软件的性能.jmeter可以模拟大量的服务器负载,并且jmeter提供图形化的性能分析. JM ...
- Intellij IDEA如何生成JavaDoc
JavaDoc是一种将注释生成HTML文档的技术. 1.使用javadoc命令生成文档 首先了解一下javadoc指令的用法 用法: javadoc [options] [packagenames] ...
- Vant 实现 上拉加载更多
Vant 的List 组件 默认支持 瀑布流滚动加载.官方的示例是用定时器模拟的数据.我们在项目实战中,肯定是结合ajax请求处理的.那么我们该如何实现这个效果呢? Vant 的 List组件 使用方 ...