ES 基础理论 配置调优
一、简介
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
它不但包括了全文搜索功能,还可以进行以下工作:
分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
实时分析的分布式搜索引擎。
可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
使用案例:
维基百科使用Elasticsearch来进行全文搜做并高亮显示关键词,以及提供search-as-you-type、did-you-mean等搜索建议功能。
英国卫报使用Elasticsearch来处理访客日志,以便能将公众对不同文章的反应实时地反馈给各位编辑。
StackOverflow将全文搜索与地理位置和相关信息进行结合,以提供more-like-this相关问题的展现。
GitHub使用Elasticsearch来检索超过1300亿行代码。
每天,Goldman Sachs使用它来处理5TB数据的索引,还有很多投行使用它来分析股票市场的变动。
二、数据写入过程
Lucene 把每次生成的倒排索引,叫做一个段(segment)。然后另外使用一个 commit 文件,记录索引内所有的 segment。而生成 segment 的数据来源,则是内存中的 buffer。
1、数据写入 --> 进入ES内存 buffer (同时记录到translog)--> 生成倒排索引分片(segment)
2、将 buffer 中的 segment 先同步到文件系统缓存中,然后再刷写到磁盘
问1:
ES如何做到实时检索?
由于在buffer中的索引片先同步到文件系统缓存,再刷写到磁盘,因此在检索时可以直接检索文件系统缓存,保证了实时性。
这一步刷到文件系统缓存的步骤,在 Elasticsearch 中,是默认设置为 1 秒间隔的,对于大多数应用来说,几乎就相当于是实时可搜索了。
不过对于 ELK 的日志场景来说,并不需要如此高的实时性,而是需要更快的写入性能。我们可以通过 /_settings 接口或者定制 template 的方式,加大 refresh_interval 参数。
|
1
2
|
# curl -XPOST http://127.0.0.1:9200/logstash-2015.06.21/_settings -d'{ "refresh_interval": "10s" } |
问2:
当segment从文件系统缓存同步到磁盘时发生了错误怎么办? 数据会不会丢失?
由于Elasticsearch 在把数据写入到内存 buffer 的同时,其实还另外记录了一个 translog日志,如果在这期间故障发生时,Elasticsearch会从commit位置开始,恢复整个translog文件中的记录,保证数据的一致性。
等到真正把 segment 刷到磁盘,且 commit 文件进行更新的时候, translog 文件才清空。这一步,叫做 flush。同样,Elasticsearch也提供了 /_flush 接口。
Elasticsearch 的flush操作主要通过以下几个参数控制:
默认设置为:每 30 分钟主动进行一次 flush,或者当 translog 文件大小大于 512MB 时主动触发flush。
这两个行为,可以分别通过
index.translog.flush_threshold_period 每隔多长时间执行一次flush(默认30m)
index.translog.flush_threshold_size 当事务日志大小到达此预设值,则执行flush。(默认512mb)
index.translog.flush_threshold_ops 当事务日志累积到多少条数据后flush一次。
问3:
索引数据的一致性通过 translog 保证。那么 translog 文件自己呢?
Elasticsearch 2.0 以后为了保证不丢失数据,每次 index、bulk、delete、update 完成的时候,一定触发刷新 translog 到磁盘上,才给请求返回 200 OK。这个改变在提高数据安全性的同时当然也降低了一点性能。
如果你不在意这点可能性,还是希望性能优先,可以在 index template 里设置如下参数:
|
1
|
"index.translog.durability": "async" |
三、segment merge 对写入性能的影响
ES 会不断在后台运行任务,主动将这些零散的 segment 做数据归并,尽量让索引内只保有少量的,每个都比较大的,segment 文件。这个过程是有独立的线程来进行的,并不影响新 segment 的产生。
当归并完成,较大的这个 segment 刷到磁盘后,commit 文件做出相应变更,删除之前几个小 segment,改成新的大 segment。等检索请求都从小 segment 转到大 segment 上以后,删除没用的小 segment。这时候,索引里 segment 数量就下降了
segment 归并的过程,需要先读取 segment,归并计算,再写一遍 segment,最后还要保证刷到磁盘。可以说,这是一个非常消耗磁盘 IO 和 CPU 的任务。所以,ES 提供了对归并线程的限速机制,确保这个任务不会过分影响到其他任务。
默认情况下,归并线程的限速配置 indices.store.throttle.max_bytes_per_sec 是 20MB。对于写入量较大,磁盘转速较高,甚至使用 SSD 盘的服务器来说,这个限速是明显过低的。对于 ELK Stack 应用,建议可以适当调大到 100MB或者更高。
通过API的设置方式,也可以写在配置文件中。
|
1
2
3
4
5
6
|
curl -XPUT http://127.0.0.1:9200/_cluster/settings -d'{ "persistent" : { "indices.store.throttle.max_bytes_per_sec" : "100mb" }}' |
用于控制归并线程的数目,推荐设置为cpu核心数的一半。 如果觉得自己磁盘性能跟不上,可以降低配置,免得IO情况瓶颈。
index.merge.scheduler.max_thread_count
归并策略
归并线程是按照一定的运行策略来挑选 segment 进行归并的。主要有以下几条:
index.merge.policy.floor_segment 默认 2MB,小于这个大小的 segment,优先被归并。
index.merge.policy.max_merge_at_once 默认一次最多归并 10 个 segment
index.merge.policy.max_merge_at_once_explicit 默认 optimize 时一次最多归并 30 个 segment。
index.merge.policy.max_merged_segment 默认 5 GB,大于这个大小的 segment,不用参与归并。optimize 除外。
optimize 接口
既然默认的最大 segment 大小是 5GB。那么一个比较庞大的数据索引,就必然会有为数不少的 segment 永远存在,这对文件句柄,内存等资源都是极大的浪费。
但是由于归并任务太消耗资源,所以一般不太选择加大 index.merge.policy.max_merged_segment 配置,而是在负载较低的时间段,通过 optimize 接口,强制归并 segment。
|
1
|
curl -XPOST http://127.0.0.1:9200/logstash-2015-06.10/_optimize?max_num_segments=1 |
由于 optimize 线程对资源的消耗比普通的归并线程大得多,所以,绝对不建议对还在写入数据的热索引执行这个操作。
四、副本分片的存储过程
默认情况下ES通过对每个数据的id值进行哈希计算,对索引的主分片取余,就是数据实际应该存储的分片ID。
由于取余这个计算,完全依赖于分母,所以导致 ES 索引有一个限制,索引的主分片数,不可以随意修改。因为一旦主分片数不一样,所以数据的存储位置计算结果都会发生改变,索引数据就完全不可读了。
有副本配置情况下,ES的写入流程
1、客户端请求发送给Node1节点,图中的Node1是Master节点,实际环境中也可以不是(通常Master节点和Data_Node部署在不同的服务器)。
2、Node 1 用数据的 _id 取余计算得到应该讲数据存储到 P0 上。通过 cluster state 信息发现 P0 的主分片已经分配到了 Node 3 上。Node 1 转发请求数据给 Node 3。
3、Node3 完成请求数据的索引过程,存入主分片 P0。然后并行转发数据给分配有 P0 的副本分片(R0)的 Node1 和 Node2。当收到任一节点汇报副本分片数据写入成功,Node 3 即返回给初始的接收节点 Node 1,宣布数据写入成功。Node 1 返回成功响应给客户端。
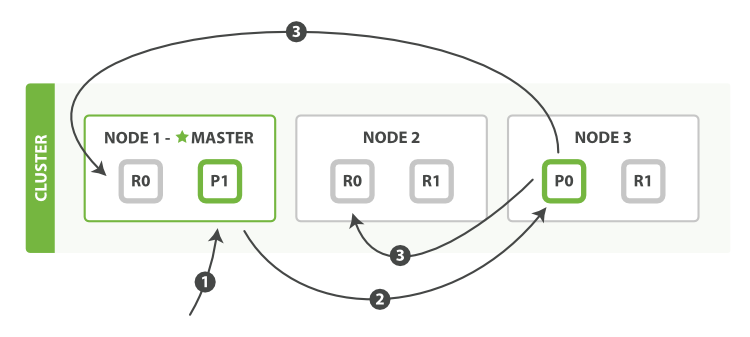
副本配置和分片配置不一样,是可以随时调整的。有些较大的索引,甚至可以在做 optimize 前,先把副本全部取消掉,等 optimize 完后,再重新开启副本,节约单个 segment 的重复归并消耗。
|
1
2
3
|
curl -XPUT http://127.0.0.1:9200/logstash-mweibo-2015.05.02/_settings -d '{ "index": { "number_of_replicas" : 0 }}' |
五、fielddata
indices.fielddata.cache.size 节点用于 fielddata 的最大内存,如果 fielddata 达到该阈值,就会把旧数据交换出去。该参数可以设置百分比或者绝对值。默认设置是不限制,所以强烈建议设置该值,比如 10%。
indices.fielddata.cache.expire 这个参数绝对绝对不要设置!
indices.breaker.fielddata.limit 默认值是JVM堆内存的60%,注意为了让设置正常生效,一定要确保 indices.breaker.fielddata.limit 的值大于 indices.fielddata.cache.size 的值。否则的话,fielddata 大小一到 limit 阈值就报错,就永远道不了 size 阈值,无法触发对旧数据的交换任务了。
六、全文搜索
ES 对搜索请求,有简易语法和完整语法两种方式。简易语法作为以后在 Kibana 上最常用的方式。
|
1
2
3
4
|
# 命令行示例:curl -XGET http://127.0.0.1:9200/logstash-2015.06.21/log/_search?q=first# curl指令 -请求方式 http://服务器IP:端口/索引库名称/_type(索引类型)/_search?q=querystring 语法 |
?q=后面跟的是querystring 语法,这种语法在Kibana上是通用的
querystring 语法解析:
全文检索:直接写搜索的单词,如 q=Shanghai
单字段的全文检索:比如知道想检索的信息可能出现在某字段中,可以在搜索单词之前加上字段名和冒号,如:q=name:tuchao
单字段的精确检索:在搜索单词前后加双引号,比如 clientip:"192.168.12.1"
多个检索条件的组合:可以使用 NOT, AND 和 OR 来组合检索,注意必须是大写。比如
|
1
|
http://127.0.0.1:9200/logstash-nginxacclog-2016.09.23/_search?q=status:>400 AND size:168 |
字段是否存在:_exists_:user 表示要求 user 字段存在,_missing_:user 表示要求 user 字段不存在;
通配符:用 ? 表示单字母,* 表示任意个字母。比如 fir?t mess*
正则: 不建议使用
近似搜索:用 ~ 表示搜索单词可能有一两个字母写的不对,请 ES 按照相似度返回结果。比如 frist~;
七、映射的定制
Elasticsearch 是一个 schema-less 的系统,会尽量根据 JSON 源数据的基础类型猜测你想要的字段类型映射。
如果你对这种动态生成的映射关系不满意,或者想要使用一些更高级的映射设置,那么就需要使用自定义映射。
ES 可以随时根据数据中的新字段来创建新的映射关系。我们也可以在还没有正式数据写入之前,先创建一个基础的映射。等后续数据有其他字段时,ES 也一样会自动处理。
映射的创建方式如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
curl -XPUT http://127.0.0.1:9200/logstash-2015.06.20/_mapping -d '{ "mappings": { "syslog" : { "properties" : { "@timestamp" : { "type" : "date" }, "message" : { "type" : "string" }, "pid" : { "type" : "long" } } } }}' |
注意:对于已存在的映射,ES 的自动处理仅限于新字段出现。已经生成的字段映射,是不可变更的。 如果确实需要,可以参考reindex接口
而如果是新增一个字段映射的更新,那还是可以通过 /_mapping 接口直接完成的:
|
1
2
3
4
5
6
7
8
9
|
curl -XPUT http://127.0.0.1:9200/logstash-2015.06.21/_mapping/syslog -d '{ "properties" : { "syslogtag" : { "type" : "string", "index": "not_analyzed" } }}' |
这里只需要单独写这个新字段的内容就够了。ES 会自动合并进去。
删除映射
删除数据并不代表会删除数据的映射。比如:
|
1
|
curl -XDELETE http://127.0.0.1:9200/logstash-2015.06.21/syslog |
删除了索引下 syslog 的全部数据,但是 syslog 的映射还在。删除映射(同时也就删掉了数据)的命令是:
|
1
|
curl -XDELETE http://127.0.0.1:9200/logstash-2015.06.21/_mapping/syslog |
当然,如果删除整个索引,那映射也是同时被清除的。
查看已有数据的映射
我们用 logstash 写入 ES 的数据,都会根据 logstash 自带的 template,生成一个很有学习意义的映射:
|
1
|
curl -XGET http://127.0.0.1:9200/logstash-nginxacclog-2016.09.20/_mapping/ |
特殊字段
ES有一些默认的特殊字段,这些字段统一以_下划线开头。如_index,_type,_id。默认不开启的还有 _ttl,_timestamp,_size,_parent 等;这里介绍两个对我们索引和检索性能都有较大影响的:
_all
_all 里存储了各字段的数据内容。其作用是,在检索的时候,如果无法或者未指明具体搜索哪个字段的数据,那么 ES 默认就会是从 _all 里去查找。
对于日志场景,如果你的日志划分出来的字段比较少且数目固定。那么,完全可以关闭掉 _all 功能,节省这部分 IO 和 CPU。
|
1
2
3
|
"_all" : { "enabled" : false} |
_source
_source 里存储了该条记录的 JSON 源数据内容。这部分内容只是按照 ES 接收到的内容原样存储下来,并不经过索引过程。对于 ES 的请求过程来说,它不参与 Query 阶段,而只用于 Fetch 阶段。我们在 GET 或者 /_search 时看到的数据内容,都是从 _source 里获取到的。
所以,虽然 _source 也重复了一遍索引中的数据,一般我们并不建议关闭这个功能。因为一旦关闭,你搜索的结果除了一个 _id,啥都看不到。对于日志场景,意义不是很大。
当然,也有少数场景是可以关闭 _source 的:
把 ES 作为时间序列数据库使用,只要聚合统计结果,不要源数据内容。
把 ES 作为纯检索工具使用,_id 对应的内容在 HDFS 上另外存储,搜索后使用所得 _id 去 HDFS 上读取内容。
八、动态模板映射
当你有一类相似的数据字段,想要统一设置其映射,就可以用到这项功能 动态模板映射(dynamic_templates)。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
"_default_" : { "dynamic_templates" : [ { "message_field" : { "mapping" : { "index" : "analyzed", "omit_norms" : true, "store" : false, "type" : "string" }, "match" : "*msg", "match_mapping_type" : "string" } }, { "string_fields" : { "mapping" : { "index" : "not_analyzed", "ignore_above" : 256, "store" : false, "doc_values" : true, "type" : "string" }, "match" : "*", "match_mapping_type" : "string" } } ], "properties" : { } } |
这样只会匹配字符串类型字段名以 msg 结尾的,都会经过全文索引,其他字符串字段则进行精确索引。同理,还可以继续书写其他类型(long, float, date 等)的 match_mapping_type 和 match。
索引模板
对每个希望自定义映射的索引,都要定时提前通过发送 PUT 请求的方式创建索引的话,未免太过麻烦。ES 对此设计了索引模板功能。我们可以针对同一类索引,定制相同的模板。
模板中的内容包括两大类,setting(设置)和 mapping(映射)。setting 部分,多为在 elasticsearch.yml 中可以设置全局配置的部分,而 mapping 部分,则是这节之前介绍的内容。如下为定义所有以 te 开头的索引的模板:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
curl -XPUT http://localhost:9200/_template/template_1 -d '{ "template" : "te*", "settings" : { "number_of_shards" : 1 }, "mappings" : { "type1" : { "_source" : { "enabled" : false } } }}' |
同时,索引模板是有序合并的。如果我们在同一类索引里,又想单独修改某一小类索引的一两处单独设置,可以再累加一层模板:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
curl -XPUT http://localhost:9200/_template/template_2 -d '{ "order" : 1, "template" : "te*", "settings" : { "number_of_shards" : 2 }, "mappings" : { "type1" : { "_all" : { "enabled" : false } } }}' |
默认的 order 是 0,那么新创建的 order 为 1 的 template_2 在合并时优先级大于 template_1。最终,对tete*/type1 的索引模板效果相当于:
|
1
2
3
4
5
6
7
8
9
10
11
|
{ "settings" : { "number_of_shards" : 2 }, "mappings" : { "type1" : { "_source" : { "enabled" : false }, "_all" : { "enabled" : false } } }} |
注1:模版合并可以用在,当不想改变原模版,又想微调模版的相关参数时可使用。 创建一个小模版,设置相关修改的参数,保证template值设置和原模版相同,由于两个模版的template相同,那么当有新的索引被创建时会匹配到两个模版,这时两个模版的配置将会合并,order值大的模版参数,将会覆盖order值小的模版参数。
关于创建小模版的配置编写需要注意几个点
1、先认真分析原模版要修改的几个段值的嵌套关系(建议使用网页的json解析工具辅助查看)
2、小模版不需要写原模版所有内容,只需要写想变更的几个字段值
3、小模版不可和原模版同名
4、可以通过请求ES输出原模版json参考,更改,但是需要删除一些导入不兼容的字段(下面注3会提到)
注2:从ES中导出的模版无法直接复制导入,格式有差异
通过访问ES中已有模版logstash3,得到以下模版json
|
1
|
http://10.10.1.90:9200/_template/logstash3?pretty |

通过删除以上我标红的字符,也就是模版名称段和别名段和多余的符号。 就可以变成以下可以导入的格式。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
curl -XPUT http://127.0.0.1:9200/_template/logstash5 -d '{ "order" : 1, "template" : "logstash-*", "settings" : { "index" : { "refresh_interval" : "120s" } }, "mappings" : { "_default_" : { "_all" : { "enabled" : false } } }}' |
关键参数解释 :
"order":1 优先级
"template":"logstash-*" 匹配索引库的 Pattern
"aliases" : { } 别名段
变更模版配置也是一样的:
1、访问该模版得到json
curl http://10.10.1.90:9200/_template/logstash3?pretty
2、变更配置,删除不兼容的字符(以上标红的字符)
3、删除原模版,重新导入
|
1
2
3
4
5
6
7
8
|
# 删除模版curl -XDELETE http://127.0.0.1:9200/_template/logstash3 # 导入curl -XPUT http://127.0.0.1:9200/_template/logstash3 -d ' 修改后的template json' |
九、elasticsearch 常用配置参数总结
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
|
# ---------------------------------- Cluster -----------------------------------# Use a descriptive name for your cluster:# 集群名称,用于定义哪些elasticsearch节点属同一个集群。cluster.name: bigdata# ------------------------------------ Node ------------------------------------# 节点名称,用于唯一标识节点,不可重名node.name: server3# 1、以下列出了三种集群拓扑模式,如下:# 如果想让节点不具备选举主节点的资格,只用来做数据存储节点。node.master: falsenode.data: true# 2、如果想让节点成为主节点,且不存储任何数据,只作为集群协调者。node.master: truenode.data: false# 3、如果想让节点既不成为主节点,又不成为数据节点,那么可将他作为搜索器,从节点中获取数据,生成搜索结果等node.master: falsenode.data: false# 这个配置限制了单机上可以开启的ES存储实例的个数,当我们需要单机多实例,则需要把这个配置赋值2,或者更高。#node.max_local_storage_nodes: 1# ----------------------------------- Index ------------------------------------# 设置索引的分片数,默认为5 "number_of_shards" 是索引创建后一次生成的,后续不可更改设置index.number_of_shards: 5# 设置索引的副本数,默认为1index.number_of_replicas: 1# 索引的刷新频率,默认1秒,太小会造成索引频繁刷新,新的数据写入就慢了。(此参数的设置需要在写入性能和实时搜索中取平衡)通常在ELK场景中需要将值调大一些比如60s,在有_template的情况下,需要设置在应用的_template中才生效。 index.refresh_interval: 120s# ----------------------------------- Paths ------------------------------------# 数据存储路径,可以设置多个路径用逗号分隔,有助于提高IO。 # path.data: /home/path1,/home/path2path.data: /home/elk/server3_data# 日志文件路径path.logs: /var/log/elasticsearch# 临时文件的路径path.work: /path/to/work# ----------------------------------- Memory -------------------------------------# 确保 ES_MIN_MEM 和 ES_MAX_MEM 环境变量设置为相同的值,以及机器有足够的内存分配给Elasticsearch# 注意:内存也不是越大越好,一般64位机器,最大分配内存别才超过32G# 当JVM开始写入交换空间时(swapping)ElasticSearch性能会低下,你应该保证它不会写入交换空间# 设置这个属性为true来锁定内存,同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过 `ulimit -l unlimited` 命令bootstrap.mlockall: true# 节点用于 fielddata 的最大内存,如果 fielddata # 达到该阈值,就会把旧数据交换出去。该参数可以设置百分比或者绝对值。默认设置是不限制,所以强烈建议设置该值,比如 10%。indices.fielddata.cache.size: 50mb# indices.fielddata.cache.expire 这个参数绝对绝对不要设置!indices.breaker.fielddata.limit 默认值是JVM堆内存的60%,注意为了让设置正常生效,一定要确保 indices.breaker.fielddata.limit 的值大于 indices.fielddata.cache.size 的值。否则的话,fielddata 大小一到 limit 阈值就报错,就永远道不了 size 阈值,无法触发对旧数据的交换任务了。#------------------------------------ Network And HTTP -----------------------------# 设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0network.bind_host: 192.168.0.1# 设置其它节点和该节点通信的ip地址,如果不设置它会自动设置,值必须是个真实的ip地址network.publish_host: 192.168.0.1# 同时设置bind_host和publish_host上面两个参数network.host: 192.168.0.1# 设置集群中节点间通信的tcp端口,默认是9300transport.tcp.port: 9300# 设置是否压缩tcp传输时的数据,默认为false,不压缩transport.tcp.compress: true# 设置对外服务的http端口,默认为9200http.port: 9200# 设置请求内容的最大容量,默认100mbhttp.max_content_length: 100mb# ------------------------------------ Translog -------------------------------------#当事务日志累积到多少条数据后flush一次。index.translog.flush_threshold_ops: 50000# --------------------------------- Discovery --------------------------------------# 这个参数决定了要选举一个Master至少需要多少个节点,默认值是1,推荐设置为 N/2 + 1,N是集群中节点的数量,这样可以有效避免脑裂discovery.zen.minimum_master_nodes: 1# 在java里面GC是很常见的,但在GC时间比较长的时候。在默认配置下,节点会频繁失联。节点的失联又会导致数据频繁重传,甚至会导致整个集群基本不可用。# discovery参数是用来做集群之间节点通信的,默认超时时间是比较小的。我们把参数适当调大,避免集群GC时间较长导致节点的丢失、失联。discovery.zen.ping.timeout: 200sdiscovery.zen.fd.ping_timeout: 200sdiscovery.zen.fd.ping.interval: 30sdiscovery.zen.fd.ping.retries: 6# 设置集群中节点的探测列表,新加入集群的节点需要加入列表中才能被探测到。 discovery.zen.ping.unicast.hosts: ["10.10.1.244:9300",]# 是否打开广播自动发现节点,默认为truediscovery.zen.ping.multicast.enabled: falseindices.store.throttle.type: mergeindices.store.throttle.max_bytes_per_sec: 100mb |
十、调优建议
调优集群的稳定性
1、增大系统最大打开文件描述符数,65535
2、关闭swap,锁定进程地址空间,防止内存swap
JVM调优
1、 -Xms 和 -Xmx 设置成相同值
|
1
2
3
|
# 设置方法vim /etc/sysconfig/elasticsearchES_HEAP_SIZE=1g # 根据机器的实际情况设置 |
2、Heap Size不超过物理内存的一半,且小于32G
调优节点丢失问题
由于在Java里面GC是很常见的,但在GC时间比较长的时候。在默认配置下,节点会频繁失联。节点的失联又会导致数据频繁重传,甚至会导致整个集群基本不可用。我们可以通过参数调整来避免这些问题。
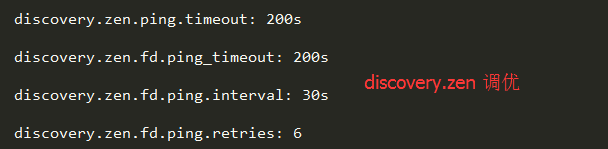
discovery参数ElasticSearch是用来做集群之间发现的,默认设置的超时时间是比较小的。我们把参数适当调大,避免集群GC时间较长导致节点的丢失、失联。
调优集群脑裂问题
建议采用角色分离的方法。
Master 节点不做数据节点
数据节点也没有资格竞选Master节点。
即不做Master节点,又不做数据节点,就是Client节点,用于响应请求,查询数据。
因为角色混合在一起会产生一个问题,当某个数据节点成为Master之后,它马上就会往其他节点发送数据以保证副本的冗余。如果数据量很大的情况下,这个Master就会一直在传送数据,而其他节点确认Master的请求可能就会被丢掉或者超时,这个时候其他节点就会重新选举新Master,造成集群脑裂。
调优索引写入速率
Index调优
index.refresh_interval: 120s 索引速率与搜索实时直接的平衡
index.translog.flush_threshold_ops: 50000 事务日志的刷新间隔,适当增大可降低磁盘IO
indices.store.throttle.max_bytes_per_sec: 100mb 当磁盘IO比较充足,可增大索引合并的限流值
这几个参数的调优原理,上面都有详细的解释。
提高查询速度
严格限制 fielddata cache 占用的内存,最好完全不用。
索引日常维护
定时删除过期索引,可以使用工具,或者写脚本跑计划任务
关闭暂时无需搜索的索引
对不再更新的索引进行optimize
转载自:
https://www.cnblogs.com/zhengchunyuan/p/8065335.html
参考文献:
http://it.dataguru.cn/article-9560-1.html
http://kibana.logstash.es/content/elasticsearch/principle/realtime.html
ES 基础理论 配置调优的更多相关文章
- Elasticsearch 基础理论 & 配置调优
一.简介 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作为 ...
- Linux下jetty报java.lang.OutOfMemoryError: PermGen space及Jetty内存配置调优解决方案
Linux下的jetty报java.lang.OutOfMemoryError: PermGen space及Jetty内存配置调优解决方案问题linux的jetty下发布程序后再启动jetty服务时 ...
- tomcat配置调优与安全总结
http://vekergu.blog.51cto.com/9966832/1672931 tomcat配置调优与安全总结 作为运维,避免不了与tomcat打交道,然而作者发现网络上关于tomcat配 ...
- (转)Tomcat配置调优与安全总结
tomcat配置调优与安全总结 作为运维,避免不了与tomcat打交道,然而作者发现网络上关于tomcat配置和调优安全的文章非常散,通过参考各位大神的相关技术文档,根据作者对tomcat的运维经验, ...
- Spark面试题(八)——Spark的Shuffle配置调优
Spark系列面试题 Spark面试题(一) Spark面试题(二) Spark面试题(三) Spark面试题(四) Spark面试题(五)--数据倾斜调优 Spark面试题(六)--Spark资源调 ...
- 一次看完28个关于ES的性能调优技巧,很赞,值得收藏!
因为总是看到很多同学在说Elasticsearch性能不够好.集群不够稳定,询问关于Elasticsearch的调优,但是每次都是一个个点的单独讲,很多时候都是case by case的解答,本文简单 ...
- MySQL 5.6初始配置调优
原文链接: What to tune in MySQL 5.6 after installation原文日期: 2013年09月17日翻译日期: 2014年06月01日翻译人员: 铁锚 随着 大量默认 ...
- eclipse定制化配置调优、初始化配置指南、可以解决启动慢等问题
配置eclipse的jvm参数 打开eclipse根目录下的eclipse.ini在最后面加上如下的jvm参数 -Xms400m -Xmx1400m -XX:NewSize=128m -XX:MaxN ...
- Tomcat--远程Debug以及参数配置调优
本文会讲解Tomcat远程Debug调试,Tomcat-manager监控(简单带过),psi-probe监控和Tomcat参数调优.本文基于Tomcat8.5版本. Tomcat远程Debug: 远 ...
随机推荐
- Linux基础系统优化(二)
SELinux功能 SELinux(Security-Enhanced Linux) 是美国国家安全局(NSA)对于强制访问控制的实现,这个功能管理员又爱又恨,大多数生产环境也是关闭的做法,安全手段使 ...
- 【LeetCode】 #9:回文数 C语言
目录 题目 思路 初步想法 进一步想法 最后想法 总结 最近打算练习写代码的能力,所以从简单题开始做. 大部分还是用C语言来解决. @(解法) 题目 判断一个整数是否是回文数.回文数是指正序(从左向右 ...
- 在bat批处理中简单的延时方法
使用for命令: 延时1s左右的方法: @echo off echo %time% ,,) do echo %%i>nul echo %time% pause %time%是用来显示延时时间,实 ...
- dubbo中使用动态代理
dubbo的动态代理也是只能代理接口 源码入口在JavassistProxyFactory中 public class JavassistProxyFactory extends AbstractPr ...
- AS3中 is,as,typeof的区别
AS3中 is,as,typeof的区别 . var my_num:Number=9;trace(typeof my_num);var my_object:Array=["语文", ...
- 3.01定义常量之define
[注:本程序验证是使用vs2013版] #include <stdio.h> #include <stdlib.h> #include <string.h> #pr ...
- windows 查看端口占用以及解决办法
windows 下查看所有端口程序1 netstat -ano 查看所有的端口占用情况2 netstat -ano|findstr "443" 查看端口为443的程序占用情况3 t ...
- [转]mongodb authentication 设置权限之后,新建个管理账户和一般数据库用户,在win 7 64bit 环境下测试使用实例
如果之前安装mongodb时没有使用 --auth,那么必须要卸载MongoDB服务,进行重新安装,设置账号权限才生效! 主要是解决在测试使用mongo db 时候,总是出现的MongoAuthent ...
- javascript高级程序设计阅读总结
5章 引用类型 1.object类型 创建 1.var obj ={} ---对象字面量 2.var obj = new Object(); ---new操作符 2.Array类型 创建 1.var ...
- CentOS 7 - 里面如何以root身份使用图形界面管理文件?
nautilus 是gnome的文件管理器,但是如果不是root账号下,权限受限,我们可以通过以下方式以root权限使用! 启动shll,随后在shell里面输入下面命令: sudo nautilus