Python3第三方组件最新版本追踪实现
一、说明
在安全基线中有一项要求就是注意软件版本是否是最新版本,检查是否是最新版本有两方面的工作一是查看当前使用的软件版本二是当前使用软件的最新版本。在之前的“安全基线自动化扫描、生成报告、加固的实现(以Tomcat为例)”中只是做了前一项把当前使用的软件版本查出来,并没有做当前使用软件的最新版本。
当然其实这也是没办法的事,因为基线扫描一般而言都是离线扫描,而追踪最新版本肯定需要联网查询;一般就一个应用来说,少说也会用到几十个第三方库,我们不如索性把最新版本追踪功能单独独立出来实现。
追踪最新版本,直观上就只是从监测页面上把最新版本提取出来没有什么难度,但实际上总有一些坑所以还是值得提一提;另外自己一般重思路胜于重具体形式,所以某个功能用什么函数具体怎么实现就算写时很熟事后也经常忘记每次都得重新百度,所以也需要记一记。
二、新版本追踪实现难点及处理办法
2.1 确认需要的内容在哪个请求中返回
现在越来越多网站是restful的,所以当你打开某个url看到的内容并不一定直接是该url的请求中返回的;而爬虫工具(如requests)只会执行给定的请求(顶多会重定向一下),并不会解析和执行javascript进行后续相关联的请求,所以我们第一步要确认我们要提取的内容是在哪个请求中返回的。
确定的方法推荐直接使用开发者工具的Network选项卡,比如Nginx中我们要提取最新stable版本,操作如下:
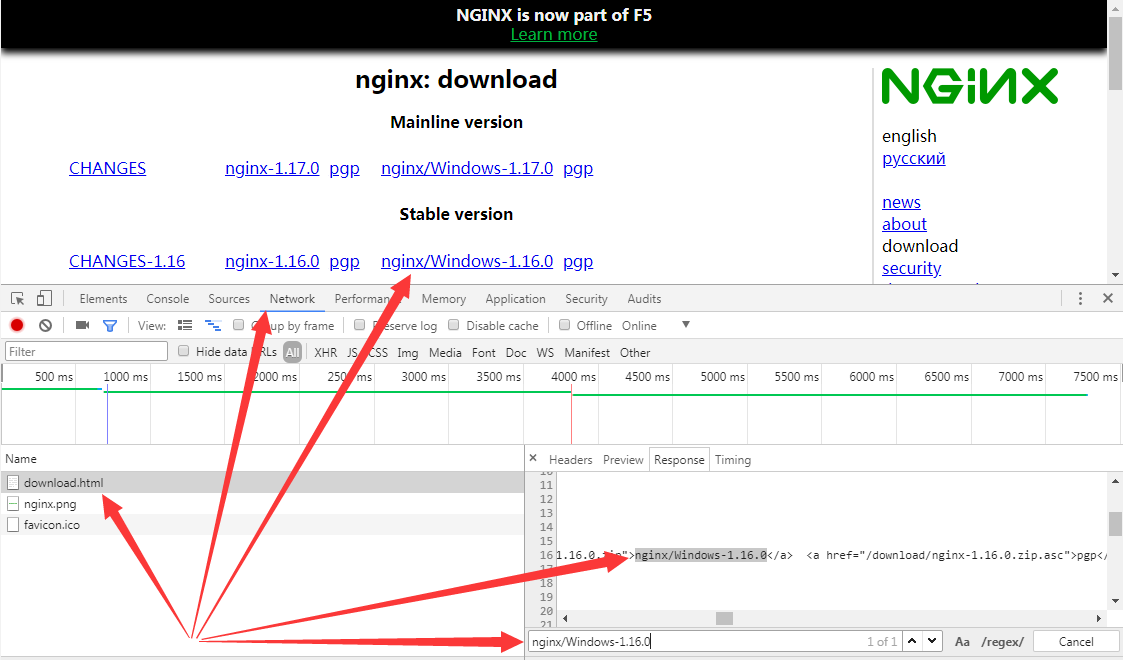
2.2 禁用javascript防止页面调整
有些页面返回后会被javascript调整(比如原来在div[3]的内容),我们前面也说过爬虫工具一般不会分析和执行javascript,如果任由浏览器执行javascript那么浏览器的内容将和爬虫工具中的内容不一致,这将会导致后续从浏览器获取的提取路径不适用于爬虫工具,所以我们需要在浏览器中禁用javascript。
chrome禁用方式:设置----高级----内容设置----JavaScript----已屏蔽
firefox禁用方式:打开about:config----过滤出javascript.enabled项----在其上双击将其值设为false
2.3 获取标签提取路径
提取标签通常有css selector和xpath selector两种形式。手动去分析确定css和xpath表达式那是比较费劲的,因为比如在<body>和你的目标标签中间有一个<div>标签有id,人工去看一是代码很长不一定能注意到,二是就算注意到了你还得确定你的目标标签是不是这个<div>的内部。
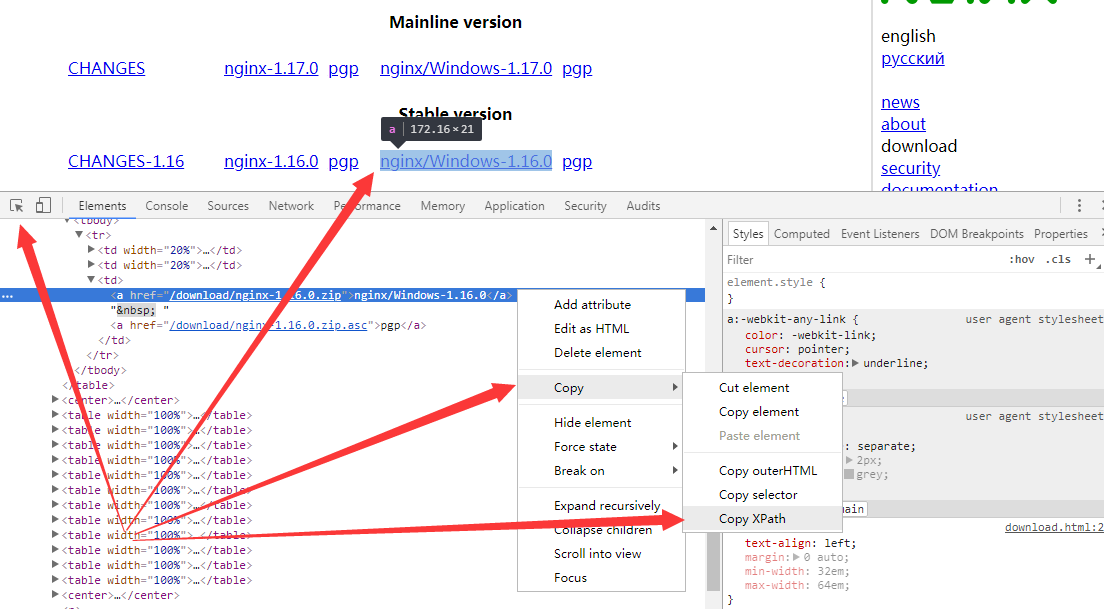
有一有一种快速的方式能获取css和xpath表达式呢,答案是有的,chrome和firefox的开发者工具就集成了。先选中目标内容,然后在其上右键,最后“Copy XPath”即可。
firefox和chrome的区别是,firefox耿直一些xpath都是绝对路径,chrome智能一些如果中间有标签有id则会使用该标签做跳板,也因此一般个人喜欢用chrome的多一些。
2.4 requests_html与lxml.html在xpath上的区别
个人喜欢用xpath胜于css,python实现xpath上通常有requests_html和lxml.html两种形式,个人又喜欢requests_html多一点。
一是requests_html天然与requests相集成;二是requests_html筛选出来的标签可以直接查看其html内容而lxml.html需要使用tostring(element)方法(from lxml.html import tostring)打印才能看到标签的html内容;三是requests_html筛选出标签后该标签即以当前自己html的最外层标签作为根节点,而lxml.html不管怎么筛选始终以最初的那个标签为根结点即直接使用xpath("//a")出来的不是当前节点下的所有a标签而是最始页面下的所有a标签,虽然可以使用xpath(".//a")的形式作折中但总是不太符合直接的认识。
当然,可以看到在代码中我们也用到了lxml.html,所以lxml.html也不是一无是处,其用处就是使用requests_html解析github的releases页面始终提取不到标签而lxml.html可以。
2.5 反爬虫----User-Agent监测
不管是爬虫还是其他一些攻击工具,出于道义,在实现时他们都会在User-Agent标识是自己(比如requests的User-Agent形如“User-Agent: python-requests/2.22.0”)。部分网站会监测User-Agent头,如果发现不是常规的浏览器会禁止访问或返回不一样的内容。
而不管是爬虫还是其他一些攻击工具,出于实用,在实现时他们都会提供一个参数来修改User-Agent。所以应对User-Agent监测,我们只要使用相应参数把当前工具的User-Agent修改成和正常浏览器一样的User-Agent即可。
应该来说监测版本号只需要访问一两个页面,不会发起大量请求,所以也就不会触发大量访问时针对User-Agent的限制规则,但为了统一我们这里还是使用随机User-Agent的方式。
我们这里通过给headers[“User-Agent”]赋值覆盖原先requests的User-Agent;另外注意我们这里的用词,不是自定义的headers替换原先的headers而只是自定义的headers项去覆盖原先的headers的项,也就是说如果原先的headers存在的头如果自定义的headers中没重新赋值那该头部就仍保持原先的值(而不是就没了)。
总的代码逻辑如下:
- user_agents = [
- 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36',
- 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:60.0) Gecko/20100101 Firefox/60.0',
- 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
- ]
- headers["User-Agent"] = select_one_user_agent()
- response = session.get(url, headers=headers, verify=False)
2.6 反爬虫----页面内容会随时间变化
实际追踪中发现网站www.elastic.co页面标签的id值会随时间变化,比如前几分钟返回的标签的id可能是“react-tabs-13165”,但过几分钟再访问可能就变成了“react-tabs-12345”。
这时如果是使用chrome获取xpath,chrome会以该id为跳板(如“//*[@id="react-tabs-13165"]/div[1]/div[1]/div[2]”),这个表达式在这几分钟可能是对的,但再过几分钟就提取不到想要的内容了。我这里的处理办法是直接使用firefox的绝对路径形式。
2.7 请求超时处理
请求超时抛出异常是很常见的,我们一是不能说任由异常抛出致使程序中断,二是不能说当前页面请求超时了就直接跳过;应当的做法是继续请求当前页面直到成功。
我这是使用捕获异常就再次递归的方式进行处理,推荐封装成一个函数,然后所有url请求都使用该函数实现,这样就不会有多处url请求然后多处都要进行处理了。
- def get_url_response(url):
- session = HTMLSession()
- print(f"request start: {url}")
- try:
- response = session.get(url, headers=headers, verify=False)
- except:
- print(f"request error, will to try again: {url}")
- # 如果异常递归调用
- return get_url_response(url)
- print(f"request success: {url}")
- session.close()
- # 最终的出口只有这一个
- return response
2.8 最新版本提取的五种情况
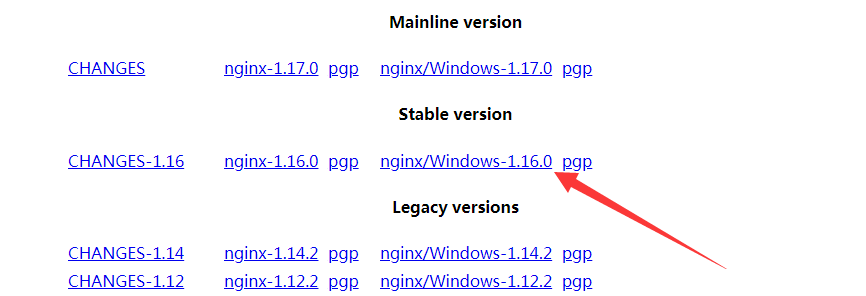
第一种----页面只有一个系列只有一个版本,直接提取。比如nginx,最新的稳定版本总在下图那个标签那里,每次只要提取该标签的内容即可得到最新的稳定版本。
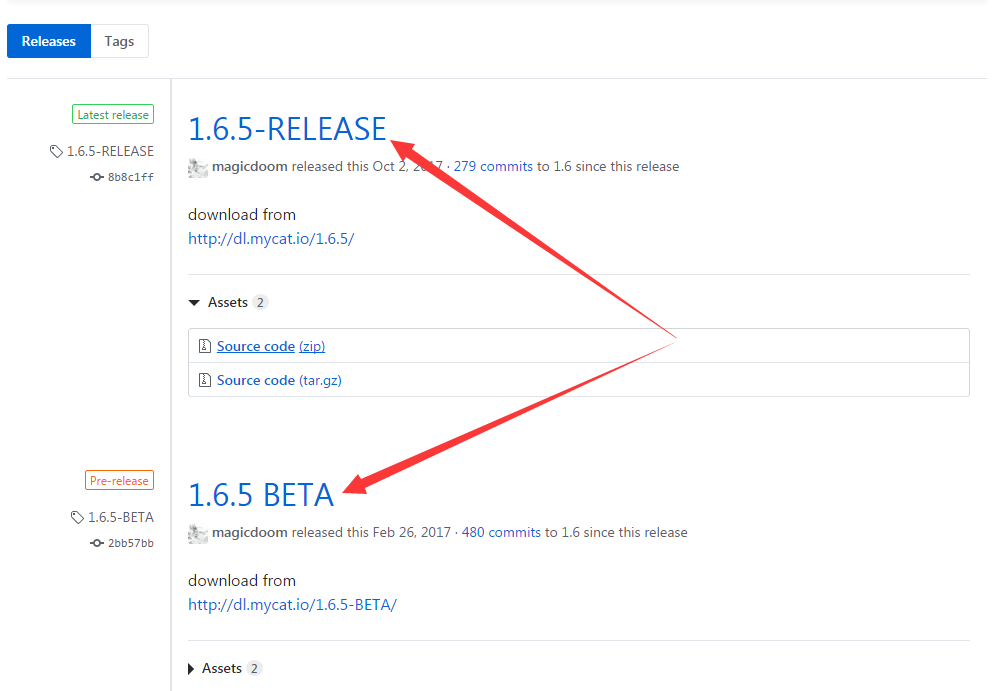
第二种----有时间顺序有多个版本只有一个分支,直接提取第一个(或最后一个)。比如mycat只有一个分支,其最后发布的版本一定是其最新版本,所以我们每次只要去读取其最新发布的那个位置就能获取到他的最新版本。
第三种----有时间顺序有多个版本有多个分支,取出版本字符串各系统取找到的第一个。比如ceph,从上往下第一个12.x版本就是12系列的最新版本,所以找到第一个包含"v12."字眼的直接return即可;其他13系列14系统一样。但这种方法如果新出一个系列那会漏掉(如v16系列)
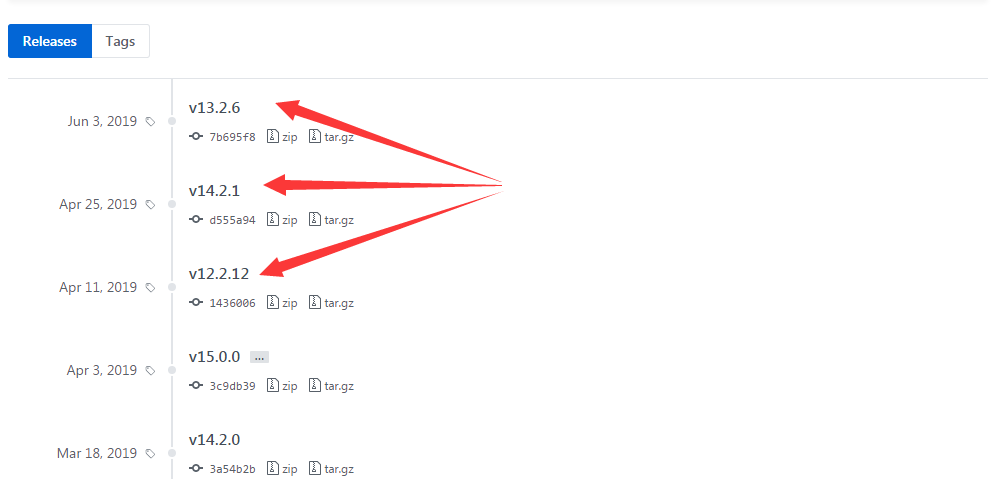
第四种----没有时间顺序有多个版本只有一个分支,那就从所有版本号字符串中提取出版本号进行比较,选出最大的那个版本号。版本号比较说明见“Python3版本号比较代码实现”。

第五种----没有时间顺序有多个版本有多个分支,这种情况就先筛选出系列,然后各系列进行版本号比较即可。
2.9 读写excel文件
python操作excel其他不懂但感觉openpyxl就挺好用,下面简单说一下使用方法:
- import openpyxl
- # 一、文件操作
- # 创建一个新的excel文件
- mywb = openpyxl.Workbook()
- # 打开一个已有excel文件,返回的对象与创建新excel文件一样
- mywb = openpyxl.load_workbook('test.xlsx')
- # 二、表操作
- # 查看当前excel文件的所有表
- mywb.get_sheet_names()
- # 创建新表,test_sheet是新创建的表的表名
- mysheet = mywb.create_sheet("test_sheet")
- # 获取已有表对象,返回的对象与创建新表一样
- # test_sheet改成自己要获取的表的表名
- # 旧方法:mysheet = mywb.get_sheet_by_name("test_sheet")
- mysheet = mywb["test_sheet"]
- # 三、表内容操作
- # 查看指定单元格内容,以A3单元格为例
- mysheet["A3"].value
- # 修改指定单元格内容,以A3单元格为例
- mysheet["A3"] = "new value"
- # 四、保存excel文件
- # test.xlsx改成自己想要的名字
- # 比较不符合认知的是,即便mywb是打开已有文件得来的也要有文件名参数
- mywb.save("test.xlsx")
三、代码实现
3.1 目录结构说明
- |
|--Common.py--公共函数文件
|
|--Config.py--配置文件
|
|--LibExample.xlsx--版本监测示例文件
|
|--LibLatestVersionTracer.py--最新版本追踪实现的主要文件,一个库一个函数,名字形如"xxx_latest_version_tracer()"
|
|--README.md--说明文件
3.2 环境构建
语言:Python3
依赖库:pip install requests-html lxml openpyxl
使用:python LibLatestVersionTracer.py
源代码:https://github.com/PrettyUp/LibLatestVersionTracer
3.3 实现效果演示
原始输入excel表格如下(其实并不从中读取数据用处只是帮助定位后边的最新版本和链接应输出到哪):
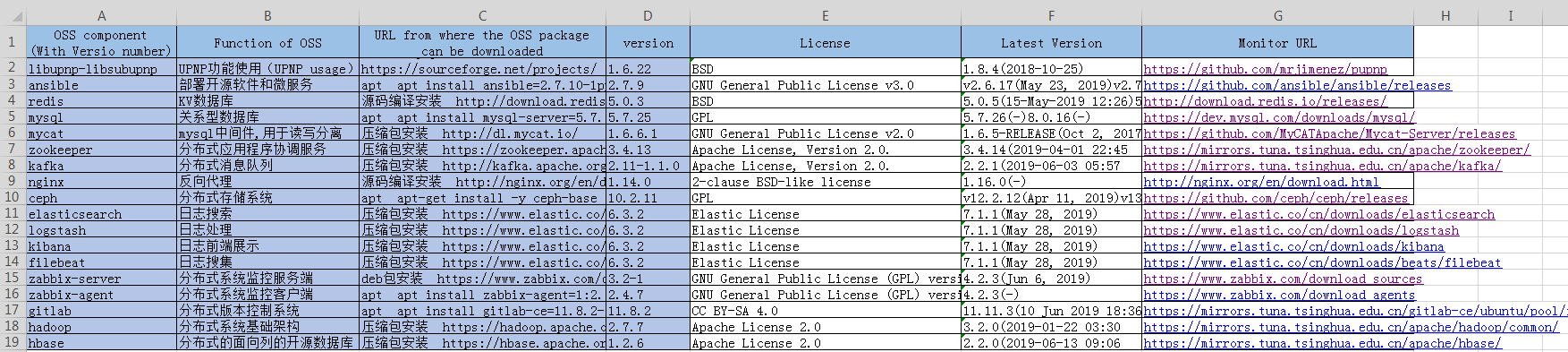
运行程序后新输出表格如下,新填写了Latest Version和Monitor URL列。(要强调我这里不是随便按格式写个库在上边,运行程序然后就得出了其最新版本和版本监测URL,那就成玄学了;每个库都得自己写代码实现追踪的):
Python3第三方组件最新版本追踪实现的更多相关文章
- Robot Framework 使用【1】-- 基于Python3.7 + RIDE 最新版本搭建
前言 Robot Framework作为公司能快速落地实现UI自动化测试的一款框架,同时也非常适合刚入门自动化测试的朋友们去快速学习自动化,笔者计划通过从搭建逐步到完成自动化测试的过程来整体描述它的使 ...
- mac下安装Python3.*(最新版本)
前言:mac系统自带python,不过以当前mac系统的最新版本为例,自带的python版本都是2.*版本,虽然不影响老版本项目的运行,但是python最新的3.*版本的一些语法与2.*版本并不相同, ...
- 【我的Android进阶之旅】如何快速寻找Android第三方开源库在Jcenter上的最新版本
问题描述 解决方法 先了解compile comsquareupokhttpokhttp240的意义 了解Jcenter和Maven jcenter Maven Central 理解jcenter和M ...
- 大规模数据分析统一引擎Spark最新版本3.3.0入门实战
@ 目录 概述 定义 Hadoop与Spark的关系与区别 特点与关键特性 组件 集群概述 集群术语 部署 概述 环境准备 Local模式 Standalone部署 Standalone模式 配置历史 ...
- C#通过第三方组件生成二维码(QR Code)和条形码(Bar Code)
用C#如何生成二维码,我们可以通过现有的第三方dll直接来实现,下面列出几种不同的生成方法: 1):通过QrCodeNet(Gma.QrCodeNet.Encoding.dll)来实现 1.1):首先 ...
- .net开发中常用的第三方组件
.net开发中常用的第三方组件 2013-05-09 09:33:32| 分类: dotnet |举报 |字号 订阅 下载LOFTER 我的照片书 | RSS.NET.dll RSS. ...
- 如何安装最新版本的memcached
转载自孟叔的博客: https://learndevops.cn/index.php/2016/06/10/how-to-install-the-latest-version-of-memcache ...
- phpstudy2016最新版本mysql无法使用innodb的问题解决
这里顺便记录一下今天遇见的神奇问题,在使用官方最新版本的phpstudy中,其它组件一切正常,但是奇怪的发现mysql是无法开启innodb的,以下为最新的下载地址: http://www.phpst ...
- React Native学习-控制横竖屏第三方组件:react-native-orientation
在项目中,有时候可能会想使不同的页面显示的横竖屏也不一样,比如前一段我做的<广播体操>的项目,在首页面,肯定是想使页面为竖屏显示,但是播放页面要为横屏显示,即使用户的手机可以转屏,我们的播 ...
随机推荐
- Java 多线程编程——多线程
如果要想在Java之中实现多线程的定义,那么就需要有一个专门的线程主体类进行线程的执行任务的定义,而这个主体类的定义是有要求的,必须实现特定的接口或者继承特定的父类才可以完成. 1. 继承Thread ...
- js中面向对象(创建对象的几种方式)
1.面向对象编程(OOP)的特点: 抽象:抓住核心问题 封装:只能通过对象来访问方法 继承:从已有的对象下继承出新的对象 多态:多对象的不同形态 注:本文引用于 http://www.cnblogs. ...
- Delphi中destroy, free, freeAndNil, release用法和区别
Delphi中destroy, free, freeAndNil, release用法和区别 1)destroy:虚方法 释放内存,在Tobject中声明为virtual,通常是在其子类中overri ...
- 正则表达式,匹配非本站图片网址去掉img标签内容实例
正则表达式,匹配非本站图片网址去掉img标签内容实例 在线正则表达式测试http://tool.oschina.net/regex/# 测试内容: <div><p>eee< ...
- OL7.6上RPM方式安装Oracle 19c
设置主机名 [root@localhost ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localh ...
- Mysql-修改用户连接数据库IP地址和用户名
将用户连接数据库(5.7.14-7)的IP地址从 10.10.5.16 修改为 10.11.4.197 Mysql> rename user 'username'@'10.10.5.16' ...
- Redis_数据类型
Redis支持的键值数据类型如下: 字符串类型 散列类型 列表类型 集合类型 有序集合类型 一.字符串类型 字符串类型是Redis中最基本的数据类型,它能存储任何形式的字符串,包括二进制数据.一个字 ...
- MySQL数据库(六)-- SQL注入攻击、视图、事物、存储过程、流程控制
一.SQL注入攻击 1.什么是SQL注入攻击 一些了解sql语法的用户,可以输入一些关键字 或合法sql,来导致原始的sql逻辑发生变化,从而跳过登录验证 或者 删除数据库 import pymysq ...
- Logstash 学习资料
学习资料 网址 Logstash Reference(官方) https://www.elastic.co/guide/en/logstash/current/introduction.html
- 常见bug类别