webuploader之大文件分段上传、断点续传
文件夹数据库处理逻辑
public class DbFolder
{
JSONObject root;
public DbFolder()
{
this.root = new JSONObject();
this.root.put("f_id", "");
this.root.put("f_nameLoc", "根目录");
this.root.put("f_pid", "");
this.root.put("f_pidRoot", "");
}
/**
* 将JSONArray转换成map
* @param folders
* @return
*/
public Map<String, JSONObject> toDic(JSONArray folders)
{
Map<String, JSONObject> dt = new HashMap<String, JSONObject>();
for(int i = 0 , l = folders.size();i<l;++i)
{
JSONObject o = folders.getJSONObject(i);
String id = o.getString("f_id");
dt.put(id, o);
}
return dt;
}
public Map<String, JSONObject> foldersToDic(String pidRoot)
{
//默认加载根目录
String sql = String.format("select f_id,f_nameLoc,f_pid,f_pidRoot from up6_folders where f_pidRoot='%s'", pidRoot);
SqlExec se = new SqlExec();
JSONArray folders = se.exec("up6_folders", sql, "f_id,f_nameLoc,f_pid,f_pidRoot","");
return this.toDic(folders);
}
public ArrayList<JSONObject> sortByPid( Map<String, JSONObject> dt, String idCur, ArrayList<JSONObject> psort) {
String cur = idCur;
while (true)
{
//key不存在
if (!dt.containsKey(cur)) break;
JSONObject d = dt.get(cur);//查父ID
psort.add(0, d);//将父节点排在前面
cur = d.getString("f_pid").trim();//取父级ID
if (cur.trim() == "0") break;
if ( StringUtils.isBlank(cur) ) break;
}
return psort;
}
public JSONArray build_path_by_id(JSONObject fdCur) {
String id = fdCur.getString("f_id").trim();//
String pidRoot = fdCur.getString("f_pidRoot").trim();//
//根目录
ArrayList<JSONObject> psort = new ArrayList<JSONObject>();
if (StringUtils.isBlank(id))
{
psort.add(0, this.root);
return JSONArray.fromObject(psort);
}
//构建目录映射表(id,folder)
Map<String, JSONObject> dt = this.foldersToDic(pidRoot);
//按层级顺序排列目录
psort = this.sortByPid(dt, id, psort);
SqlExec se = new SqlExec();
//是子目录->添加根目录
if (!StringUtils.isBlank(pidRoot))
{
JSONObject root = se.read("up6_files"
, "f_id,f_nameLoc,f_pid,f_pidRoot"
, new SqlParam[] { new SqlParam("f_id", pidRoot) });
psort.add(0, root);
}//是根目录->添加根目录
else if (!StringUtils.isBlank(id) && StringUtils.isBlank(pidRoot))
{
JSONObject root = se.read("up6_files"
, "f_id,f_nameLoc,f_pid,f_pidRoot"
, new SqlParam[] { new SqlParam("f_id", id) });
psort.add(0, root);
}
psort.add(0, this.root);
return JSONArray.fromObject(psort);
}
public FileInf read(String id) {
SqlExec se = new SqlExec();
String sql = String.format("select f_pid,f_pidRoot,f_pathSvr from up6_files where f_id='%s' union select f_pid,f_pidRoot,f_pathSvr from up6_folders where f_id='%s'", id,id);
JSONArray data = se.exec("up6_files", sql, "f_pid,f_pidRoot,f_pathSvr","");
JSONObject o = (JSONObject)data.get(0);
FileInf file = new FileInf();
file.id = id;
file.pid = o.getString("f_pid").trim();
file.pidRoot = o.getString("f_pidRoot").trim();
file.pathSvr = o.getString("f_pathSvr").trim();
return file;
}
public Boolean exist_same_file(String name,String pid)
{
SqlWhereMerge swm = new SqlWhereMerge();
swm.equal("f_nameLoc", name.trim());
swm.equal("f_pid", pid.trim());
swm.equal("f_deleted", 0);
String sql = String.format("select f_id from up6_files where %s ", swm.to_sql());
SqlExec se = new SqlExec();
JSONArray arr = se.exec("up6_files", sql, "f_id", "");
return arr.size() > 0;
}
/**
* 检查是否存在同名目录
* @param name
* @param pid
* @return
*/
public Boolean exist_same_folder(String name,String pid)
{
SqlWhereMerge swm = new SqlWhereMerge();
swm.equal("f_nameLoc", name.trim());
swm.equal("f_deleted", 0);
swm.equal("LTRIM (f_pid)", pid.trim());
String where = swm.to_sql();
String sql = String.format("(select f_id from up6_files where %s ) union (select f_id from up6_folders where %s)", where,where);
SqlExec se = new SqlExec();
JSONArray fid = se.exec("up6_files", sql, "f_id", "");
return fid.size() > 0;
}
public Boolean rename_file_check(String newName,String pid)
{
SqlExec se = new SqlExec();
JSONArray res = se.select("up6_files"
, "f_id"
,new SqlParam[] {
new SqlParam("f_nameLoc",newName)
,new SqlParam("f_pid",pid)
},"");
return res.size() > 0;
}
public Boolean rename_folder_check(String newName, String pid)
{
SqlExec se = new SqlExec();
JSONArray res = se.select("up6_folders"
, "f_id"
, new SqlParam[] {
new SqlParam("f_nameLoc",newName)
,new SqlParam("f_pid",pid)
},"");
return res.size() > 0;
}
public void rename_file(String name,String id) {
SqlExec se = new SqlExec();
se.update("up6_files"
, new SqlParam[] { new SqlParam("f_nameLoc", name) }
, new SqlParam[] { new SqlParam("f_id", id) });
}
public void rename_folder(String name, String id, String pid) {
SqlExec se = new SqlExec();
se.update("up6_folders"
, new SqlParam[] { new SqlParam("f_nameLoc", name) }
, new SqlParam[] { new SqlParam("f_id", id) });
}
}
1.在webuploader.js大概4880行代码左右,在动态生成的input组件的下面(也可以直接搜索input),增加webkitdirectory属性。
function FileUploader(fileLoc, mgr)
{
var _this = this;
this.id = fileLoc.id;
this.ui = { msg: null, process: null, percent: null, btn: { del: null, cancel: null,post:null,stop:null }, div: null};
this.isFolder = false; //不是文件夹
this.app = mgr.app;
this.Manager = mgr; //上传管理器指针
this.event = mgr.event;
this.Config = mgr.Config;
this.fields = jQuery.extend({}, mgr.Config.Fields, fileLoc.fields);//每一个对象自带一个fields幅本
this.State = this.Config.state.None;
this.uid = this.fields.uid;
this.fileSvr = {
pid: ""
, id: ""
, pidRoot: ""
, f_fdTask: false
, f_fdChild: false
, uid: 0
, nameLoc: ""
, nameSvr: ""
, pathLoc: ""
, pathSvr: ""
, pathRel: ""
, md5: ""
, lenLoc: "0"
, sizeLoc: ""
, FilePos: "0"
, lenSvr: "0"
, perSvr: "0%"
, complete: false
, deleted: false
};//json obj,服务器文件信息
this.fileSvr = jQuery.extend(this.fileSvr, fileLoc);
2.可以获取路径
this.open_files = function (json)
{
for (var i = 0, l = json.files.length; i < l; ++i)
{
this.addFileLoc(json.files[i]);
}
setTimeout(function () { _this.PostFirst(); },500);
};
this.open_folders = function (json)
{
for (var i = 0, l = json.folders.length; i < l; ++i) {
this.addFolderLoc(json.folders[i]);
}
setTimeout(function () { _this.PostFirst(); }, 500);
};
this.paste_files = function (json)
{
for (var i = 0, l = json.files.length; i < l; ++i)
{
this.addFileLoc(json.files[i]);
}
};
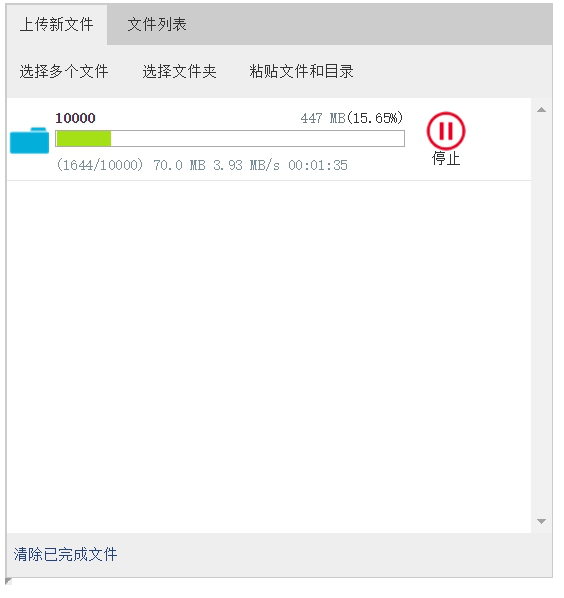
后端代码逻辑大部分是相同的,目前能够支持MySQL,Oracle,SQL。在使用前需要配置一下数据库,可以参考我写的这篇文章:http://blog.ncmem.com/wordpress/2019/08/07/java超大文件上传与下载/
webuploader之大文件分段上传、断点续传的更多相关文章
- Asp.net mvc 大文件上传 断点续传
Asp.net mvc 大文件上传 断点续传 进度条 概述 项目中需要一个上传200M-500M的文件大小的功能,需要断点续传.上传性能稳定.突破asp.net上传限制.一开始看到51CTO上的这 ...
- vue之大文件分段上传、断点续传
需求: 支持大文件批量上传(20G)和下载,同时需要保证上传期间用户电脑不出现卡死等体验: 内网百兆网络上传速度为12MB/S 服务器内存占用低 支持文件夹上传,文件夹中的文件数量达到1万个以上,且包 ...
- php之大文件分段上传、断点续传
前段时间做视频上传业务,通过网页上传视频到服务器. 视频大小 小则几十M,大则 1G+,以一般的HTTP请求发送数据的方式的话,会遇到的问题:1,文件过大,超出服务端的请求大小限制:2,请求时间过长, ...
- javascript之大文件分段上传、断点续传(一)
需求: 支持大文件批量上传(20G)和下载,同时需要保证上传期间用户电脑不出现卡死等体验: 内网百兆网络上传速度为12MB/S 服务器内存占用低 支持文件夹上传,文件夹中的文件数量达到1万个以上,且包 ...
- B/S之大文件分段上传、断点续传
4GB以上超大文件上传和断点续传服务器的实现 随着视频网站和大数据应用的普及,特别是高清视频和4K视频应用的到来,超大文件上传已经成为了日常的基础应用需求. 但是在很多情况下,平台运营方并没有大文件上 ...
- js之大文件分段上传、断点续传
文件夹上传:从前端到后端 文件上传是 Web 开发肯定会碰到的问题,而文件夹上传则更加难缠.网上关于文件夹上传的资料多集中在前端,缺少对于后端的关注,然后讲某个后端框架文件上传的文章又不会涉及文件夹. ...
- java之大文件分段上传、断点续传
文件上传是最古老的互联网操作之一,20多年来几乎没有怎么变化,还是操作麻烦.缺乏交互.用户体验差. 一.前端代码 英国程序员Remy Sharp总结了这些新的接口 ,本文在他的基础之上,讨论在前端采用 ...
- java+大文件分段上传
一. 功能性需求与非功能性需求 要求操作便利,一次选择多个文件和文件夹进行上传:支持PC端全平台操作系统,Windows,Linux,Mac 支持文件和文件夹的批量下载,断点续传.刷新页面后继续传输. ...
- 使用百度webuploader实现大文件上传
版权所有 2009-2018荆门泽优软件有限公司 保留所有权利 官方网站:http://www.ncmem.com/ 产品首页:http://www.ncmem.com/webapp/up6.2/in ...
随机推荐
- 2019-7-16 import / from...import... 模块的调用
模块调用的总结:如果你是pycharm打开文件,会自动帮你把文件根目录加到system.path中,你要调用模块直接以根目录为基准开始找.1.假如你要调用和文件根目录为同级的文件,你直接import ...
- C++ Primer中文第四版
C++ Primer中文第四版 在简书上发现有挂羊头卖狗肉的,发的plus,而且压缩包还得付钱获取密码,我直接去github搜到了第四版,在此分享一下. 格式:pdf 书签目录:有 下载地址: ...
- unity---为什么用Time.deltaTime * speed 表示每秒移动的距离的理解
Time.deltaTime:代表时间增量,即从上一帧到当前帧消耗的时间, 这个值是动态变化的. dt 表示 deltaTime. 假如 1s渲染10帧,沿X轴方向的移动速度 speed = 10m/ ...
- BZOJ1060或洛谷1131 [ZJOI2007]时态同步
BZOJ原题链接 洛谷原题链接 看上去就觉得是一道树形\(\mathtt{DP}\),不过到头来我发现我写了一个贪心.. 显然对越靠近根(记为\(r\))的边进行加权贡献越大,且同步的时间显然是从根到 ...
- 线程池及Executor框架
1.为什么要使用线程池? 诸如 Web 服务器.数据库服务器.文件服务器或邮件服务器之类的许多服务器应用程序都面向处理来自某些远程来源的大量短小的任务.请求以某种方式到达服务器,这种方式可能是通过 ...
- AESUtil
AESUtil package cn.ucaner.alpaca.common.util; import sun.misc.BASE64Decoder; import sun.misc.BASE64E ...
- Linux文件比对,批量复制
--背景 工作中突然有一天文件服务器空间满了,导致文件存不进去,立马换了另外一台服务器作为文件服务器,将服务器挂载上去,原来的服务器修复之后需要重新换回来,但是需要将临时使用的服务器内的文件迁移至原文 ...
- EF6 + MySql 建立项目引用失败
EF6 + MySql 建立项目 步骤 在项目中使用” NuGet” 包添加 EntityFramework 和 MySql.Data ,如下图 (1) 在NuGet界面中的“浏览”选项卡 ...
- MSP---企业上云需要考虑的问题
一.评估 1.应用是否可以上云: 2.时间:规划时间,迁移时间 2.成本:人力成本,资源成本 二.上云 1.如何上云:选择云厂商,选择MSP 2.云选择:公有云,私有云,混合云,多云(不要最贵的,也不 ...
- 【Win10】系统修改
1.删除“快速访问”[操作说明] a.打开HKEY_CLASSES_ROOT\CLSID\{679f85cb-0220-4080-b29b-5540cc05aab6}\ShellFolder ...