爬虫---Beautiful Soup 爬取图片
上一篇简单的介绍Beautiful Soup 的基本用法,这一篇写下如何爬取网站上的图片,并保存下来
爬取图片
1.找到一个福利网站:http://www.xiaohuar.com/list-1-1.html
2.通过F12进行定位图片
3.通过下图可以看到标签为img,然后通过width="210"的属性
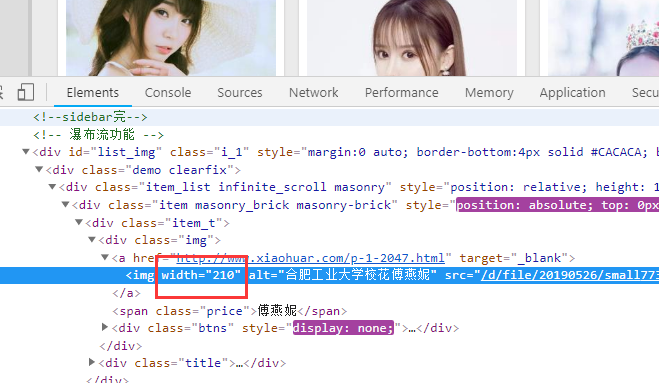
爬取方法
1.通过find_all()的方法进行查找图片位置
2.筛选出图片的URL和图片名称
3.筛选后会发现其中有一些图片URL不完整
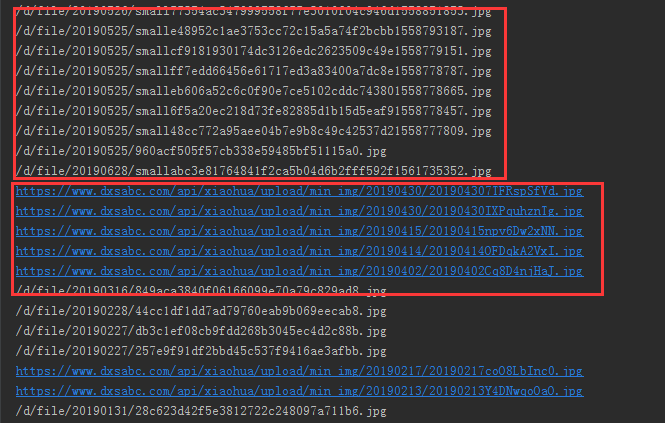
4.这个时候需要在代码中加一个判断,如何URL不完整 我们就给他补充完整
import requests
from bs4 import BeautifulSoup
import os
# 请求地址
url = 'http://www.xiaohuar.com/list-1-1.html'
html = requests.get(url).content
# BeautifulSoup 实例化
soup = BeautifulSoup(html,'html.parser')
jpg_data = soup.find_all('img',width="")
for i in jpg_data:
data = i['src']
name = i['alt']
# 判断URL是否完整
if "https://www.dxsabc.com/" not in data:
data = 'http://www.xiaohuar.com'+ data
保存图片
1.判断一个文件夹是否存在,不存在就重新创建
2.request模块请求图片的URL
3.通过content返回图片二进制,进行写入文件夹中
# coding:utf-8
import requests
from bs4 import BeautifulSoup
import os
# 创建一个文件夹名称
FileName = 'tupian'
if not os.path.exists(os.path.join(os.getcwd(), FileName)): # 新建文件夹
print(u'建了一个名字叫做', FileName, u'的文件夹!')
os.mkdir(os.path.join(os.getcwd(),'tupian'))
else:
print(u'名字叫做', FileName, u'的文件夹已经存在了!')
url = 'http://www.xiaohuar.com/list-1-1.html'
html = requests.get(url).content # 返回html
soup = BeautifulSoup(html,'html.parser') # BeautifulSoup对象
jpg_data = soup.find_all('img',width="") # 找到图片信息
for i in jpg_data:
data = i['src'] # 图片的URL
name = i['alt'] # 图片的名称
if "https://www.dxsabc.com/" not in data:
data = 'http://www.xiaohuar.com'+data
r2 = requests.get(data)
fpath = os.path.join(FileName,name)
with open(fpath+'.jpg','wb+')as f : # 循环写入图片
f.write(r2.content)
print('保存成功,快去查看图片吧!!')
图片就不贴了,喜欢的可以自己动手写一写。
爬虫---Beautiful Soup 爬取图片的更多相关文章
- 一起学爬虫——使用Beautiful Soup爬取网页
要想学好爬虫,必须把基础打扎实,之前发布了两篇文章,分别是使用XPATH和requests爬取网页,今天的文章是学习Beautiful Soup并通过一个例子来实现如何使用Beautiful Soup ...
- 使用Beautiful Soup爬取猫眼TOP100的电影信息
使用Beautiful Soup爬取猫眼TOP100的电影信息,将排名.图片.电影名称.演员.时间.评分等信息,提取的结果以文件形式保存下来. import time import json impo ...
- 爬虫---Beautiful Soup 初始
我们在工作中,都会听说过爬虫,那么什么是爬虫呢? 什么是网络爬虫 爬虫基本原理 所谓网络爬虫就是一个自动化数据采集工具,你只要告诉它要采集哪些数据,丢给它一个 URL,就能自动地抓取数据了.其背后的基 ...
- 爬虫---Beautiful Soup 通过添加不同的IP请求
上一篇爬虫写了如何应付反爬的一些策略也简单的举了根据UA的例子,今天写一篇如何根据不同IP进行访问豆瓣网获取排行版 requests添加IP代理 如果使用代理的话可以通过requests中的方法pro ...
- 爬虫---Beautiful Soup 反反爬虫事例
前两章简单的讲了Beautiful Soup的用法,在爬虫的过程中相信都遇到过一些反爬虫,如何跳过这些反爬虫呢?今天通过知乎网写一个简单的反爬中 什么是反爬虫 简单的说就是使用任何技术手段,阻止别人批 ...
- scrapy爬虫系列之三--爬取图片保存到本地
功能点:如何爬取图片,并保存到本地 爬取网站:斗鱼主播 完整代码:https://files.cnblogs.com/files/bookwed/Douyu.zip 主要代码: douyu.py im ...
- 爬虫-Beautiful Soup模块
阅读目录 一 介绍 二 基本使用 三 遍历文档树 四 搜索文档树 五 修改文档树 六 总结 一 介绍 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通 ...
- python3爬虫-快速入门-爬取图片和标题
直接上代码,先来个爬取豆瓣图片的,大致思路就是发送请求-得到响应数据-储存数据,原理的话可以先看看这个 https://www.cnblogs.com/sss4/p/7809821.html impo ...
- Python爬虫学习 - day1 - 爬取图片
利用Python完成简单的图片爬取 最近学习到了爬虫,瞬时觉得很高大上,想取什么就取什么,感觉要上天.这里分享一个简单的爬取汽车之家文章列表的图片教程,供大家学习. 需要的知识点储备 本次爬虫脚本依赖 ...
随机推荐
- CUDA 与 OpenGL 的互操作
CUDA 与 OpenGL 的互操作一般是使用CUDA生成数据,然后在OpenGL中渲染数据对应的图形.这两者的结合有两种方式: 1.使用OpenGL中的PBO(像素缓冲区对象).CUDA生成像素数据 ...
- hibernate之主键生成策略
1. hibernate的主键生成器: generator元素:表示了一个主键生成器,它用来为持久化类实例生成唯一的标识 . 连接数据库的xml hibernate.cfg.xml <?xml ...
- 借助meta影藏顶部菜单
1===>报错 Cannot find module 'webpack/lib/Chunk' 删除node_modules 然后重新下载 4==> 现在已进入页面,底部就有四个菜单,在点击 ...
- 详解C++ STL multiset 容器
详解C++ STL multiset 容器 本篇随笔简单介绍一下\(C++STL\)中\(multiset\)容器的使用方法及常见使用技巧. multiset容器的概念和性质 \(set\)在英文中的 ...
- luoguP5227 [AHOI2013]连通图(线性基做法)
题意 神仙哈希做法. 随便找个生成树,给每个非树边赋一个值,树边的值为所有覆盖它的边的值得异或和. 删去边集使得图不联通当且即当边集存在一个子集异或和为0,可以用线性基. 证明的话好像画个图挺显然的 ...
- 使用Qiniu-JavaScript-SDK上传文件至七牛云存储
一.Qiniu-JavaScript-SDK介绍 基于 JS-SDK 可以方便的从浏览器端上传文件至七牛云存储,并对上传成功后的图片进行丰富的数据处理操作. JS-SDK 兼容支持 H5 File A ...
- matlab练习程序(DBSCAN)
DBSCAN全称Density-Based Spatial Clustering of Applications with Noise,是一种密度聚类算法. 和Kmeans相比,不需要事先知道数据的类 ...
- CF1207F Koala and Notebook(BFS)
你可能会好奇为什么只有一个 BFS 的标签,却还能够排到 F 的位置. 因为它实在是太 简 单 了 有更新 首先,比较两个数,可以先比较两个数的长度,然后比较两个数看成数字串后的字典序. 不妨先把每条 ...
- idea2019最新注册码(亲测有效)
序言 最近发现经常用的idea注册用的License Server 又不能用了,估计是被"约谈了".内容如下: 虽然Community版本是免费使用的,但是在使用的过程中会出现各种 ...
- D3力布图绘制--节点间的多条关系连接线的方法(转)
在项目中遇到这样的场景,在使用D3.js绘制力布图的过程中,需要在2个节点间绘制多条连接线,找到一个不错的算法,在此分享下. 效果图: HTML中要连接 <!DOCTYPE html> & ...