hadoop 0.20.2伪分布式安装详解
adoop 0.20.2伪分布式安装详解
hadoop有三种运行模式:

伪分布式不需要安装虚拟机,在同一台机器上同时启动5个进程,模拟分布式。
完全分布式至少有3个节点,其中一个做master,运行名称节点(namenode)、作业跟踪器(jobtracker)等主要进程,另外两个做datanode,运行tasktracker,最好有两个,否则没有冗余,谈不上集群。
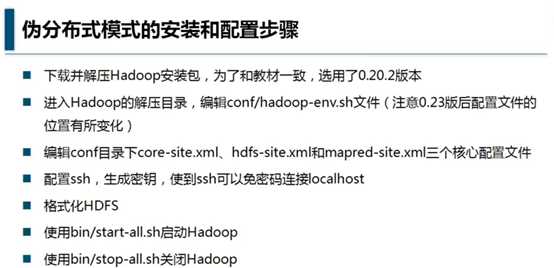
下载hadoop 0.20.2安装包:
http://archive.apache.org/dist/hadoop/core/hadoop-0.20.2/hadoop-0.20.2.tar.gz
解压后,放置在合适的位置,如/opt/Hadoop-0.20.2,执行以下命令:
tar -zxvf /opt/haddop-0.20.2
x表示展开文件,-x | --extract | --get 从存档展开文件
z表示用gzip对文档进行压缩或解压,-z | --gzip | --ungzip 用gzip对存档压缩或解压
-v | --verbose 详细显示处理的文件
-f | --file [HOSTNAME:]F 指定存档或设备(缺省为 /dev/rmt0)
如果指定解压目录,则最一个字符应当是“/”,否则就是文件了
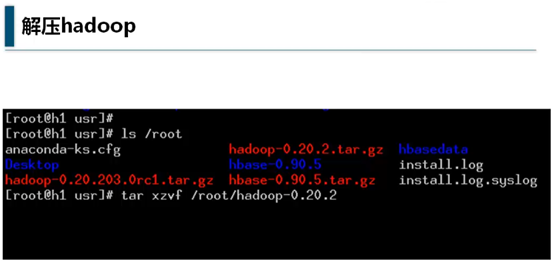
进入Hadoop-0.20.2目录
vim conf/Hadoop-env.sh
其中的conf目录是config的缩写,通常是用来放置配置文件的目录,很多开源软件习惯于使用这个目录名称。Hadoop版本不同,配置文件可能也不同,要根据实际情况有所调整。
解压后,进入Hadoop-0.20.2目录,进行配置

本文配置这四个文件。
修改hadoop-env.sh文件
进入conf目录,找到图中的三个文件
vim hadoop-env.sh
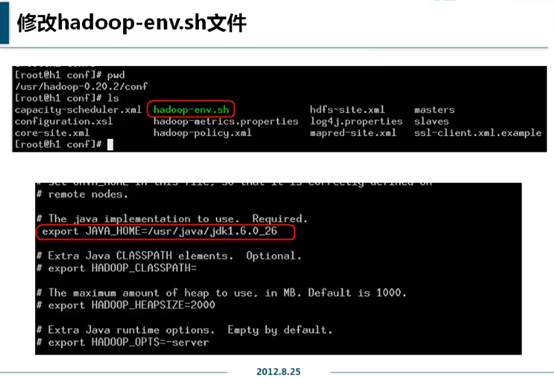
找到JAVA_HOME那一项,或修改,或增加,由你选择,最后使
export JAVA_HOME=你的java目录
这一行生效。
此文件暂时仅配置这一项即可。
修改core-site.xml文件
然后
vim core-site.xml
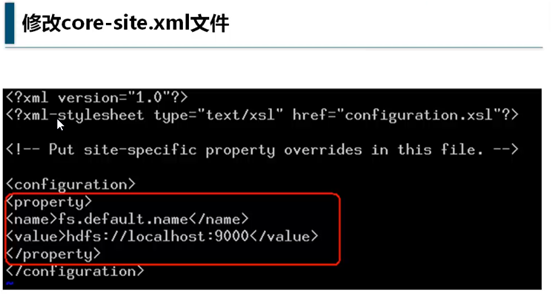
最初的<configuration>项是空的,伪分布式完全按照图中的<property>部分添加即可。
完全分布式要把hdfs:项的主机名部分换成对应的IP或主机名,不管是什么,不会是localhost,此处要注意。
其中的fs.default.name用来指定namenode的IP地址和端口,用于和对应的节点联系。
修改hdfs-site.xml文件
vim hdfs-site.xml
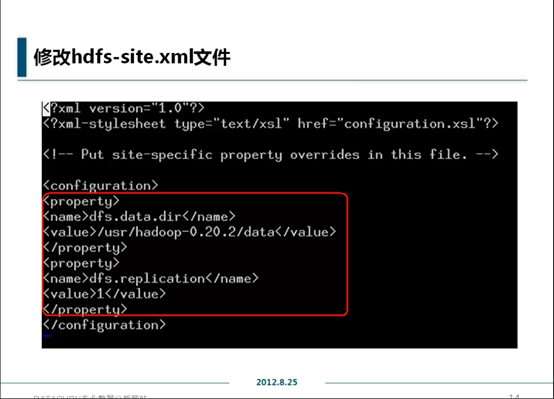
与core-site相同,第一次进入时<configuration>项是空的,伪分布式完全按照红圈部分添加即可。完全分布式要修改dfs.replication部分的value,因为hadoop会往多个节点中复制数据用于备份,此处设置的是最大份数,也就是数据节点的数量,也就是小弟的数量,伪分布式只有一个节点,所以是1,写多了也没用。dfs.data.dir是数据节点的数据的存放位置。

其它参数不多讲。
修改mapred-site.xml
vim mapred-site.xml
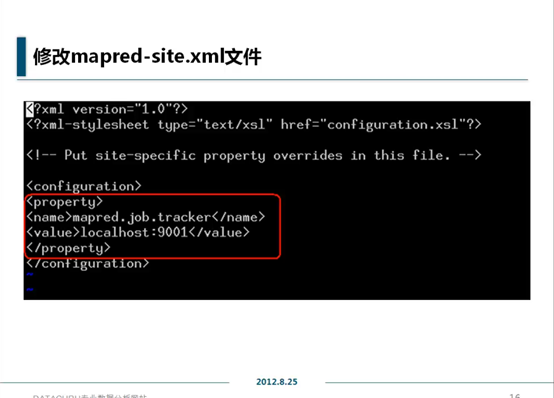
作业跟踪器的位置,端口默认,无须修改。作业跟踪器是整个mapreduce系统调度的核心。
伪分布式照搬上图,完全分布式修改主机名。

其它参数,暂时不动。
生成SSH密钥对
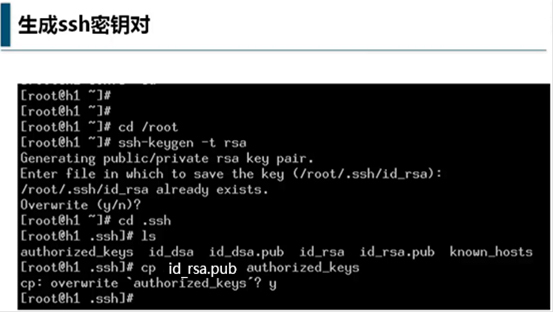
- 输入su,切换到root用户
- cd /root,进入root目录
- 运行ssh-kengen -t rsa
给root用户创建一对密钥,公钥和私钥,不对称(不一样),公钥可公开,别人拿到公钥后,可对文件需要加密的内容进行加密,然后传给服务器,服务器可用私钥解密。公钥加密的,只有私钥才能解密。反之亦然,可以用私钥加密,用公钥可以解密,私钥本身无法解密,但这样做没有意义。
拿到公钥,反推私钥,基本上不可能,以目前的计算能力,需要几百年。
RSA算法,产生密钥过程时间很短,但反推消耗时间非常长。例如,两个上千位的素数相乘,所得到的结果,如果反推,可能性太多,只能逐一尝试,这样就会消耗非常长的时间。
Enter file in which to save the key,这一句是问把生成的公钥和私钥存放在哪个文件,如果输入a,则生成a.pub和a两个文件。如果不输入,直接回车,则生成默认文件名id_rsa.pub和id_rsa。
可以使用任何编辑工具查看它们的内容,比如cat id_rsa.pub,里面是人类无法理解的字符串。
然后执行命令:
cp id_isa.pub authorized_keys
authorized_keys中存在id_rsa.pub公钥,就可以免密码连入
至此,hadoop0.20.2的伪分布式就配完了。
格式化分布式文件系统
hadoop目录下执行bin/hadoop namenode -format
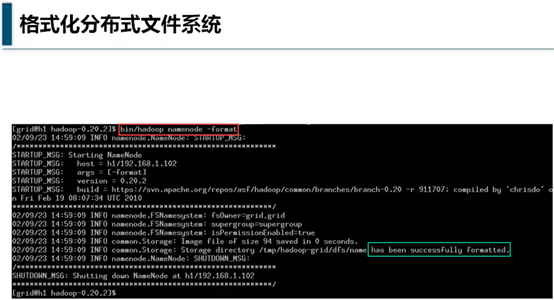
此操作的目的在于,在“名称节点”上建立一系列结构,用来存放整个HDFS的元数据,
出现绿圈的提示has been successfully formatted即是配置成功。
下面在hadoop目录下执行以下命令:
bin/start-all.sh
(如果进入bin目录,然后执行start-all.sh,会报“未找到命令”)
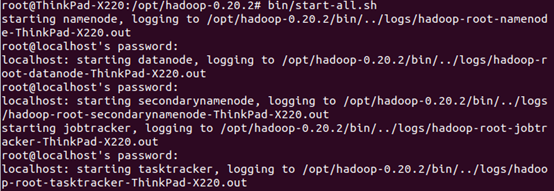
如果没有看到denied之类的提示,就是启动成功了。
检测守护进程启动情况
在root用户下,使用java的jps,会看到类似以下的提示:
一样的规则,不能进入到java的bin目录下执行jps,而是java目录下执行bin/jps

表示伪分布式hadoop0.20.2配置成功。
hadoop 0.20.2伪分布式安装详解的更多相关文章
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- centos 7下Hadoop 2.7.2 伪分布式安装
centos 7 下Hadoop 2.7.2 伪分布式安装,安装jdk,免密匙登录,配置mapreduce,配置YARN.详细步骤如下: 1.0 安装JDK 1.1 查看是否安装了openjdk [l ...
- hadoop 2.7.3伪分布式安装
hadoop 2.7.3伪分布式安装 hadoop集群的伪分布式部署由于只需要一台服务器,在测试,开发过程中还是很方便实用的,有必要将搭建伪分布式的过程记录下来,好记性不如烂笔头. hadoop 2. ...
- hadoop-0.20.2伪分布式安装简记
1.准备环境 虚拟机(redhat enterprise linux 6.5) jdk-8u92-linux-x64.tar.gz hadoop-0.20.2.tar.gz 2.关闭虚拟机的防火墙,s ...
- Hadoop新生报到(一) hadoop2.6.0伪分布式配置详解
首先先不看理论,搭建起环境之后再看: 搭建伪分布式是为了模拟环境,调试方便. 电脑是win10,用的虚拟机VMware Workstation 12 Pro,跑的Linux系统是centos6.5 , ...
- Hadoop伪分布安装详解(五)
目录: 1.修改主机名和用户名 2.配置静态IP地址 3.配置SSH无密码连接 4.安装JDK1.7 5.配置Hadoop 6.安装Mysql 7.安装Hive 8.安装Hbase 9.安装Sqoop ...
- Hadoop + Hive + HBase + Kylin伪分布式安装
问题导读 1. Centos7如何安装配置? 2. linux网络配置如何进行? 3. linux环境下java 如何安装? 4. linux环境下SSH免密码登录如何配置? 5. linux环境下H ...
- Hadoop伪分布安装详解(三)
目录: 1.修改主机名和用户名 2.配置静态IP地址 3.配置SSH无密码连接 4.安装JDK1.7 5.配置Hadoop 6.安装Mysql 7.安装Hive 8.安装Hbase 9.安装Sqoop ...
- Hadoop伪分布安装详解(二)
目录: 1.修改主机名和用户名 2.配置静态IP地址 3.配置SSH无密码连接 4.安装JDK1.7 5.配置Hadoop 6.安装Mysql 7.安装Hive 8.安装Hbase 9.安装Sqoop ...
随机推荐
- httpclient检查某个链接是否可用
private boolean checkUrlIsValid(String url) { CloseableHttpClient httpClient = HttpClients.createDef ...
- s3cmd用法总结
概述 S3是亚马逊AWS提供的简单存储服务(可以理解为有公网域名的大容量高可用存储) S3配合CloudFront服务可作为CDN使用,它提供多节点全球发布 安装 方法一: yum install s ...
- 物联网架构成长之路(14)-SpringBoot整合thymeleaf
使用thymeleaf作为模版进行测试 在pom.xml 增加依赖 <dependency> <groupId>org.springframework.boot</gro ...
- Java知多少(62)线程同步
当两个或两个以上的线程需要共享资源,它们需要某种方法来确定资源在某一刻仅被一个线程占用.达到此目的的过程叫做同步(synchronization).像你所看到的,Java为此提供了独特的,语言水平上的 ...
- laravel中artisan的用法
如:
- Spark学习笔记——Spark Streaming
许多应用需要即时处理收到的数据,例如用来实时追踪页面访问统计的应用.训练机器学习模型的应用, 还有自动检测异常的应用.Spark Streaming 是 Spark 为这些应用而设计的模型.它允许用户 ...
- Android图片处理(Matrix,ColorMatrix)
转发说明:原文链接http://www.cnblogs.com/leon19870907/articles/1978065.html 在编程中有时候需要对图片做特殊的处理,比如将图片做出黑白的,或者老 ...
- SSM框架整合搭建教程
自己配置了一个SSM框架,打算做个小网站,这里把SSM的配置流程详细的写了出来,方便很少接触这个框架的朋友使用,文中各个资源均免费提供! 一. 创建web项目(eclipse) File-->n ...
- .NET中进行Base64加密解密
方法一: /// <summary> /// Base64加密 /// </summary> /// <param name="Message"> ...
- 使用UWA GOT优化Unity性能和内存
优化百科: https://blog.uwa4d.com/archives/Index.html https://blog.uwa4d.com/archives/Introduction_UWAGOT ...