关于Zookeeper选举机制
一.Zookeeper集群
配置多个实例共同构成一个集群对外提供服务以达到水平扩展的目的,每个服务器上的数据是相同的,
每一个服务器均可以对外提供读和写的服务,这点和redis是相同的,即对客户端来讲每个服务器都是平等的。
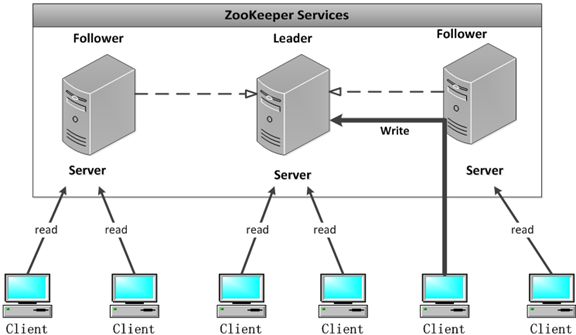
这篇主要分析leader的选择机制,zookeeper提供了三种方式:
(1)LeaderElection;
(2)AuthFastLeaderElection;
(3)FastLeaderElection;
默认的算法是FastLeaderElection,下面分析它的选举机制。
二.选择机制中的概念
1、服务器ID
比如有三台服务器,编号分别是1,2,3。
编号越大在选择算法中的权重越大。
2、数据ID
服务器中存放的最大数据ID.
值越大说明数据越新,在选举算法中数据越新权重越大。
3、逻辑时钟
或者叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加,然后与接收到的其它服务器返回的投票信息中的数值相比,根据不同的值做出不同的判断。
4、选举状态
(1)LOOKING,竞选状态。
(2)FOLLOWING,随从状态,同步leader状态,参与投票。
(3)OBSERVING,观察状态,同步leader状态,不参与投票。
(4)LEADING,领导者状态。
5、选举消息内容
在投票完成后,需要将投票信息发送给集群中的所有服务器,它包含如下内容。
(1)服务器ID;
(2)数据ID;
(3)逻辑时钟;
(4)选举状态。
6、选举流程图
因为每个服务器都是独立的,在启动时均从初始状态开始参与选举,下面是简易流程图。

7、选举状态图
描述Leader选择过程中的状态变化,这是假设全部实例中均没有数据,假设服务器启动顺序分别为:A,B,C。

8、源码分析
QuorumPeer
主要看这个类,只有LOOKING状态才会去执行选举算法。每个服务器在启动时都会选择自己做为领导,然后将投票信息发送出去,循环一直到选举出领导为止。
public void run() {
//.......
try {
while (running) {
switch (getPeerState()) {
case LOOKING:
if (Boolean.getBoolean("readonlymode.enabled")) {
//...
try {
//投票给自己...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
} finally {
//...
}
} else {
try {
//...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
}
}
break;
case OBSERVING:
//...
break;
case FOLLOWING:
//...
break;
case LEADING:
//...
break;
}
}
} finally {
//...
}
}
FastLeaderElection
它是zookeeper默认提供的选举算法,核心方法如下:具体的可以与本文上面的流程图对照。
public Vote lookForLeader() throws InterruptedException {
//...
try {
HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();
int notTimeout = finalizeWait;
synchronized(this){
//给自己投票
logicalclock.incrementAndGet();
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
//将投票信息发送给集群中的每个服务器
sendNotifications();
//循环,如果是竞选状态一直到选举出结果
while ((self.getPeerState() == ServerState.LOOKING) &&
(!stop)){
Notification n = recvqueue.poll(notTimeout,
TimeUnit.MILLISECONDS);
//没有收到投票信息
if(n == null){
if(manager.haveDelivered()){
sendNotifications();
} else {
manager.connectAll();
}
//...
}
//收到投票信息
else if (self.getCurrentAndNextConfigVoters().contains(n.sid)) {
switch (n.state) {
case LOOKING:
// 判断投票是否过时,如果过时就清除之前已经接收到的信息
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
//更新投票信息
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(),
getInitLastLoggedZxid(),
getPeerEpoch());
}
//发送投票信息
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
//忽略
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
//更新投票信息
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//判断是否投票结束
if (termPredicate(recvset,
new Vote(proposedLeader, proposedZxid,
logicalclock.get(), proposedEpoch))) {
// Verify if there is any change in the proposed leader
while((n = recvqueue.poll(finalizeWait,
TimeUnit.MILLISECONDS)) != null){
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)){
recvqueue.put(n);
break;
}
}
if (n == null) {
self.setPeerState((proposedLeader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(proposedLeader,
proposedZxid, proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING:
//忽略
break;
case FOLLOWING:
case LEADING:
//如果是同一轮投票
if(n.electionEpoch == logicalclock.get()){
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//判断是否投票结束
if(termPredicate(recvset, new Vote(n.leader,
n.zxid, n.electionEpoch, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, n.electionEpoch)) {
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
//记录投票已经完成
outofelection.put(n.sid, new Vote(n.leader,
IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state));
if (termPredicate(outofelection, new Vote(n.leader,
IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, IGNOREVALUE)) {
synchronized(this){
logicalclock.set(n.electionEpoch);
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
}
Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
default:
//忽略
break;
}
} else {
LOG.warn("Ignoring notification from non-cluster member " + n.sid);
}
}
return null;
} finally {
//...
}
}
判断是否已经胜出
默认是采用投票数大于半数则胜出的逻辑。
9、选举流程简述
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
(1)服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking。
(2)服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
(3)服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
(4)服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
(5)服务器5启动,后面的逻辑同服务器4成为小弟。
关于Zookeeper选举机制的更多相关文章
- 学习笔记:Zookeeper选举机制
1.Zookeeper选举机制 Zookeeper虽然在配置文件中并没有指定master和slave 但是,zookeeper工作时,是有一个节点为leader,其他则为follower Leader ...
- Zookeeper选举机制(转)
源:http://blog.csdn.net/tototuzuoquan/article/details/54426684 1.Zookeeper选举机制 Zookeeper虽然在配置文件中并没有指定 ...
- 理解zookeeper选举机制
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- 【转】Zookeeper学习---zookeeper 选举机制介绍
[原文]https://www.toutiao.com/i6593162565872779784/ zookeeper集群 配置多个实例共同构成一个集群对外提供服务以达到水平扩展的目的,每个服务器上的 ...
- zookeeper选举机制
在上一篇文章中我们大致浏览了zookeeper的启动过程,并且提到在Zookeeper的启动过程中leader选举是非常重要而且最复杂的一个环节.那么什么是leader选举呢?zookeeper为什么 ...
- zookeeper 选举机制 和 eruake
zookeeper简介: 在分布式环境中,多个服务之间协调一致.有提供分布式锁.服务配置.实现分布式领域CAP(consistency一致性,Availiablity高可用,patition tolr ...
- 8.8.ZooKeeper 原理和选举机制
1.ZooKeeper原理 Zookeeper虽然在配置文件中并没有指定master和slave但是,zookeeper工作时,是有一个节点为leader,其他则为follower,Leader是通 ...
- Zookeeper的概述、安装部署及选举机制
一.Zookeeper概述 1.Zookeeper是Hadoop生态的管理者,它致力于开发和维护开源服务器,实现高度可靠的分布式协调. 2.Zookeeper的两大功能: (1)存储数据 (2)监听 ...
- zookeeper leader选举机制
最近看了下zookeeper的源码,先整理下leader选举机制 先看几个关键数据结构和函数 服务可能处于的状态,从名字应该很好理解 public enum ServerState { LOOKING ...
随机推荐
- 【leetcode】66-PlusOne
problem Plus One code class Solution { public: vector<int> plusOne(vector<int>& digi ...
- input标签(按钮)
按钮: <input type="button" name="..." value="..." /> <input typ ...
- Gym - 101002D:Programming Team (01分数规划+树上依赖背包)
题意:给定一棵大小为N的点权树(si,pi),现在让你选敲好K个点,需要满足如果如果u被选了,那么fa[u]一定被选,现在要求他们的平均值(pi之和/si之和)最大. 思路:均值最大,显然需要01分数 ...
- 20155208徐子涵 2016-2017-2 《Java程序设计》第10周学习总结
#### **教材学习总结**网络编程 网络编程就是在两个或两个以上的设备(例如计算机)之间传输数据.程序员所作的事情就是把数据发送到指定的位置,或者接收到指定的数据,这个就是狭义的网络编程范畴. * ...
- javascrpit的理解
1.什么是Javascrpt? 轻量级 .编程语言 HTML+css -->设计 参数的默认值设置 函数的闭包: 浏览器加载整个页面的过程 浏览器:多线程 1.js引擎 2.UI渲染 3.事件线 ...
- Go Example--原子计数器
package main import ( "fmt" "runtime" "sync/atomic" "time" ) ...
- 【HAOI2014】遥感监测
独立博客被硬盘保护干掉了真不爽啊…… 原题: 外星人指的是地球以外的智慧生命.外星人长的是不是与地球上的人一样并不重要,但起码应该符合我们目前对生命基本形式的认识.比如,我们所知的任何生命都离不开液态 ...
- zabbix——拓扑图入门
zabbix的拓扑图是动态的,当你配置好拓扑图后,一旦网络中那个节点出现了问题,很容易在拓扑图中看出问题具体出在哪个位置. 新建一个拓扑图 我们常用到的图标有rack(机柜)还有rackmountab ...
- MySQL DataType--数值类型
=========================================================MySQL常见的整数类型有:TINYINT: 占用8位空间SMALLINT: 占用16 ...
- .NET本质论 方法
方法和JIT编译 CLR只执行本机的机器代码.如果一个方法体由CIL组成,那么它就必须在调用之前被转换为本机的机器码(将MSIL编译为本机代码,运行库提供了两种方式.一种就是在安装与部署时的预编译(由 ...