抓取epsg.io的内容
简述
epsg.io是一个查询EPSG坐标系相关信息的好网站,内容很全。有各种格式的定义可以直接下载,也有坐标系的范围名称等相关信息,所以想抓取这些信息下来,方便对接各个系统。
epsg.io本身是开源的,代码在https://github.com/klokantech/epsg.io上,但是这个我分析出数据来源,应该是在epsg.io/gml/gml.sqlite文件中,但是我打开这个文件发现没有相关的记录。
抓取说明
抓取的时候使用的是proj4项目里的nad/epsg文件中的记录作为索引,找到对应的epsg代码去拼成对应url去下载。
下面是代码,用的是libcurl进行的相关操作。日志记录简单的用了一下glog,可以去掉,去掉之后就是纯C的代码了。
抓取的结果直接写在程序目录下的epsg.io目录下,请先创建好这个目录。
保存的html文件的解析,可以参考HTML解析库Gumbo简单使用记录
抓取好的文件可以在这里epsg.io.7z下载,解压压缩之后会有三百多兆,共5754个文件。
分析后提取的内容,生成了一个超大的JSON文件,可以再这里epsg.io.json.7z下载。
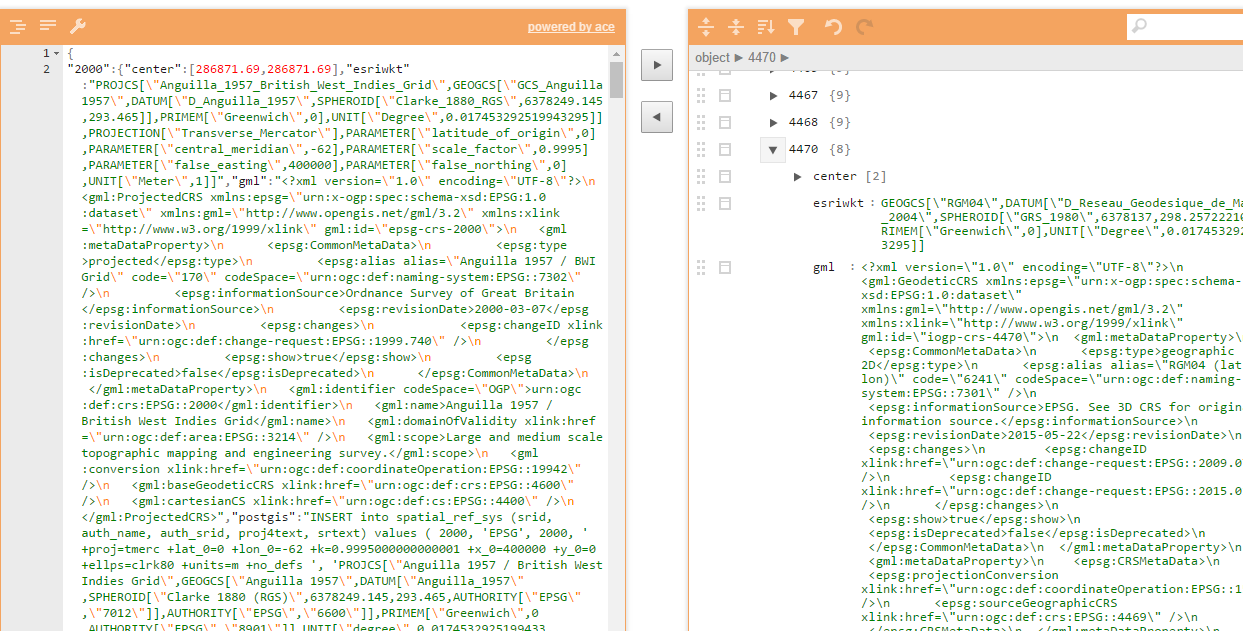
我把抓取的内容处理成json后,又将其导入了MongoDB数据库。
这里将数据备份后上传在这里https://files.cnblogs.com/files/oloroso/epsg.io.mongodb.7z,这个数据可以直接使用mongorestore工具恢复到数据库。
导入MongoDB的数据中,wgs84_bound字段名改为84box,proj_bound字段改为projbox,中心点坐标经过处理,不会有null出现。
代码
// g++ epsg.spider.cpp -o epsg.spider -lcurl -lglog -lpthread
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>
#include <curl/curl.h>
#include <glog/logging.h>
int downpage(int epsgcode)
{
int ret = 0;
char url[1024];
sprintf(url,"./epsg.io/%d.html",epsgcode);
FILE* fp = fopen(url,"wb");
if(fp == NULL){
fprintf(stderr,"\n创建输出文件失败i\n");
ret = -1;
return ret;
}
sprintf(url,"http://epsg.io/%d",epsgcode);
CURL *hnd = curl_easy_init();
curl_easy_setopt(hnd, CURLOPT_CUSTOMREQUEST, "GET");
curl_easy_setopt(hnd, CURLOPT_URL, url);
curl_easy_setopt(hnd, CURLOPT_COOKIEFILE, "./epsg.spider.cookie");
//curl_easy_setopt(hnd, CURLOPT_COOKIE, cookie_buffer);
curl_easy_setopt(hnd, CURLOPT_WRITEDATA, fp);
CURLcode res = (CURLcode)curl_easy_perform(hnd);
if(res != CURLE_OK) {
fprintf(stderr,"\n%s curl_easy_perform failed:%s\n",url,curl_easy_strerror(res));
ret = -2;
}
fclose(fp);
curl_easy_cleanup(hnd);
return ret;
}
int main(int c,char** v)
{
// 打开epsg文件
FILE* fp = fopen("epsg","r");
if(fp == NULL){
puts("open epsg fiaild");
return 0;
}
google::InitGoogleLogging(v[0]);
FLAGS_log_dir = ".";
/*
* 这个函数只能用一次,如果这个函数在curl_easy_init函数调用时还没调用,
* 它讲由libcurl库自动调用,所以多线程下最好在主线程中调用一次该函数以防止在线程
* 中curl_easy_init时多次调用
*/
curl_global_init(CURL_GLOBAL_ALL);
char s[4096];
puts("开始下载:");
while(!feof(fp) && limit > 0){
int epsgcode = 0;
static char name[1024];
static char proj[1024];
fgets(s,sizeof s,fp);
if(s[0] == '#' ){
sscanf(s,"# %[^\n]s",name);
}
sscanf(s,"<%d> %[^\n<]s",&epsgcode,proj);
if(epsgcode == 0){
continue;
}
char path[128];
sprintf(path,"./epsg.io/%d.html",epsgcode);
struct stat st;
if(stat(path,&st) == 0) {
if(st.st_size > 1024){
// printf("%5d %s exsits\n",epsgcode,path);
continue;
}
}
printf("\r正在下载:http://epsg.io/%d ",epsgcode);
LOG(INFO) << "begin download http://epsg.io/"<<epsgcode;
if( downpage(epsgcode) != 0){
break;
}
LOG(INFO) << "finish download http://epsg.io/"<<epsgcode;
}
//在结束libcurl使用的时候,用来对curl_global_init做的工作清理。类似于close的函数
curl_global_cleanup();
fclose(fp);
return 0;
}
抓取epsg.io的内容的更多相关文章
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写 ...
- C#抓取AJAX页面的内容
原文 C#抓取AJAX页面的内容 现在的网页有相当一部分是采用了AJAX技术,所谓的AJAX技术简单一点讲就是事件驱动吧(当然这种说法可能很不全面),在你提交了URL后,服务器发给你的并不是所有是页面 ...
- php抓取网页中的内容
以下就是几种常用的用php抓取网页中的内容的方法.1.file_get_contentsPHP代码代码如下:>>>>>>>>>>>&g ...
- Java 抓取网页中的内容【持续更新】
背景:前几天复习Java的时候看到URL类,当时就想写个小程序试试,迫于考试没有动手,今天写了下,感觉还不错 内容1. 抓取网页中的URL 知识点:Java URL+ 正则表达式 import jav ...
- 【新手向】使用nodejs抓取百度贴吧内容
参考教程:https://github.com/alsotang/node-lessons 1~5节 1. 通过superagent抓取页面内容 superagent .get('http://www ...
- 还没被玩坏的robobrowser(4)——从页面上抓取感兴趣的内容
背景 本节的知识实际上是属于Beautiful Soup的内容. robobrowser支持Beautiful Soup,一般来说通过下面3个方法获取页面上感兴趣的内容 find find_all s ...
- python3抓取淘宝评论内容
好久没有写爬虫了,今天研究了下淘宝商品评论的内容. 一开始用最简单的方法,挂代理,加请求头,对网页请求,是抓不到数据的,在网上找了一些相关文章,也基本已经过时了,就是网站逻辑有改动,用旧的方法是抓不到 ...
- 用C#抓取AJAX页面的内容
现在的网页有相当一部分是采用了AJAX技术,不管是采用C#中的WebClient还是HttpRequest都得不到正确的结果,因为这些脚本是在服务器发送完毕后才执行的! 但我们用IE浏览页面时是正常的 ...
- sax 动态切换 抓取感兴趣的内容(把element当做documnet 处理)
由switch 类触发事件 import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.hel ...
随机推荐
- 《剑指offer》-数字在排序数组中出现的次数
统计一个数字在排序数组中出现的次数. 首先吐槽下出题人的用词,啥叫排序数组?"排序"是个动词好么,"有序"作为一个形容词表示状态,修饰"数组" ...
- DailyWallpaper v1.03 released
根据这一段时间的使用发现了一些问题,重新修正一下. 修正电脑从休眠状态中恢复时如果没有网络连接程序报错的bug. 添加了异常处理语句,防止抓取网页数据时的错误. 这个版本将是最后一个bug fix版本 ...
- D 矩阵快速幂
Description <英雄联盟>(简称LOL)是由美国Riot Games开发,腾讯游戏运营的英雄对战网游.<英雄联盟>除了即时战略.团队作战外,还拥有特色的英雄.自动匹配 ...
- google gcr.io、k8s.gcr.io 国内镜像
1.首先添加docker官方的国内镜像 sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ...
- HDU 2896 病毒侵袭【AC自动机】
<题目链接> Problem Description 当太阳的光辉逐渐被月亮遮蔽,世界失去了光明,大地迎来最黑暗的时刻....在这样的时刻,人们却异常兴奋——我们能在有生之年看到500年一 ...
- HDU 2955_Robberies 小偷抢银行【01背包】
<题目链接> 题意: 先是给出几组数据,每组数据第一行是总被抓概率p(最后求得的总概率必须小于他,否则被抓),然后是想抢的银行数n.然后n行,每行分别是该银行能抢的钱数m[i]和被抓的概率 ...
- 001.HAProxy简介
一 HAProxy简介 HAProxy是可提供高可用性.负载均衡以及基于TCP(从而可以反向代理mysql等应用)和HTTP应用的代理,支持虚拟主机,它是免费.快速并且可靠的一种解决方案.HAProx ...
- Android入门笔记
Android项目的目录结构(Eclipse版) src:项目源代码文件夹 R.java:存放项目中所有资源文件的资源id,永远不要修改 Android.jar:Android的jar包,导入此包方可 ...
- 简述synchronized和java.util.concurrent.locks.Lock的异同?
主要相同点:Lock能完成synchronized所实现的所有功能 . 主要不同点:Lock有比synchronized更精确的线程语义和更好的性能.synchronized会自动释放锁,而Lock一 ...
- 洛谷.4180.[模板]次小生成树Tree(Kruskal LCA 倍增)
题目链接 构建完MST后,枚举非树边(u,v,w),在树上u->v的路径中找一条权值最大的边(权为maxn),替换掉它 这样在 w=maxn 时显然不能满足严格次小.但是这个w可以替换掉树上严格 ...