配置named服务之前的 相关术语意思
putty: [p^ti]: 油灰, 腻子,像 clay 粘土一样起 连接作用.
非常简洁,只有500多kB, 不需要安装,纯绿色的,版本还是0.x, Simon Tatham, 甚至没有主界面,没有菜单/工具栏什么的, 仅仅只有一个创建连接的对话框, 连接后就只有一个方框了.
通常 没有如果没有什么特殊原因, 都是直接使用 这个 putty (油灰/腻子) 来连接的了.
- 更深刻地理解linux的安装和目录
编译安装有点类似于win安装到指定的目录如d:\program files\fooSoft, 而dnf/yum安装相当于win的默认的安装到 c:\program files..
编译安装的东西几乎全部集中放到一个同一个地方; 而dnf安装的东西是分散的 分别的放在各个默认的目录中
通常安装一个软件的时候,按类别放置:
基础架构的东西放在include, lib中
配置文件放在conf目录, 少数有的放在etc中
服务的 管理 启动 停止等放在 sbin中
而对于服务的工具类如调试, utils等放在bin中
软件包的资源文件通常放在share中, 比如软件的css,js, images, man, scripts, documents帮助文档等等...
还有一个很重要的目录: var, 通常是对于服务器软件来说的, 就是一些服务器 向外提供的内容, 一些经常会变化的内容, 比如httpd的 /var/www目录, dns的 /var/named目录等. 通常各种服务器的经常变换的实体内容都集中放在/var目录中
还有一些 辅助目录, 如: log等.
dns的配置文件实际上只有两个, 一个是主配置文件named.conf, 另一个是区域数据文件.
对于区域文件的命名, 通常用 .zone结尾,比如: file "localdomain.zone"; 或者: file "0.0.127.zone"named.ca 中的ca是cache的意思, 是缓存的意思, 因为dns系统 支持暂存盘, 但是只有 root根才可以这样命名.
动态dns系统是指 存在 主/从 master:slave dns-server的情况下, 当然得要安装其他dns支持组件
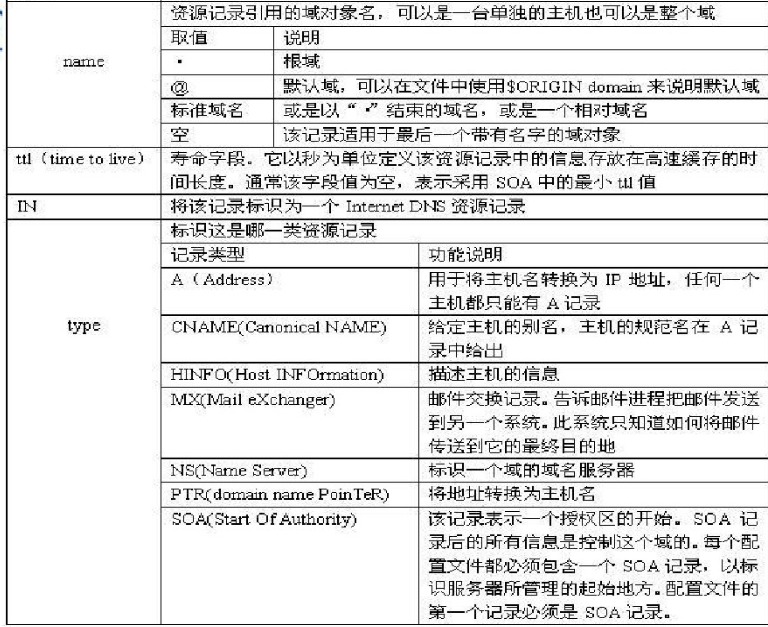
在dns中的IN, 指的是: IN = internet 资源类型.
区域zone文件中的 allow-update {none;}; 表示的是是否 允许 客户机/和当前dns服务器 自行更新自己的dns记录.
dns的运行命令和服务名称叫named, 但是提供他的包名称是bind. bind: Barkley internet named daemon. 这是用得最多的 一种dns服务器软件(也还有其他的dns服务器软件包).
通常要安装的包有: bind, bind-utils ([i]或[ai] 是utility的缩写,一些工具包性质的软件), 还有 caching-nameserver
notepad中保存文件时光标会乱跳? 这是一个小bug? 解决方法是: 一种是取消"格式中的 自动换行", 第二种是: 打开文件时什么都不要操作, 先ctrl-s保存一下,以后保存时就不会乱跑了
- 为什么要告诉dns服务器主机的resolv.conf中的 域名服务器呢?
就是要有一个最原始的"鸡"来生蛋: 因为最开始的dns服务器的缓存是空的: 仔细看这篇文章: http://blog.csdn.net/bpingchang/article/details/38377053
如果您了解 DNS 的查询模式﹐您会知道 DNS 服务器在查询非自己管辖的 zone 的时候﹐首先会向 root 查询下一级的 zone 在哪里﹐然后逐级查询下去。但问题是﹕当 named 刚启动的时候﹐在 cache 里面一片空白﹐它怎么知道 root zone 的 servers 在哪里呢﹖这不是一个矛盾吗﹖所以﹐就必须靠这个档案告诉 named 关于 root zone 的 servers 有哪些﹖以及在哪里﹖ --- 明白了吗﹖
- 终于知道这个A类型是什么意思了: A= Address 地址正向解析类型 的意思, 而 反向解析区域的命名是:
zone "0.0.127.in-addr.arpa" IN { ....}这里的 in-addr.arpa 表示的是 internet - address. 这个是固定的写法, 直接添加在 反ip地址后面就行了.
要知道in-addr.arpa究竟是什么意思? 看RFC的官方文档说的:
This address mapping domain is calledIN-ADDR.ARPA Within that domain are subdomains for each network, based on network number. 原来它是一个官方专门取的一个名字, 一个域的名字
named 的日志查看: named -g
查看所有的服务信息: service --status-all
bind-utils 是bind-utilities for querying name servers
为什么named要用rndc来管理?
因为bind在设计的时候, 就是这样设计的, 主要是为了 dns不中断解析(通常生产环境中的dns服务器很繁忙的), 可以通过rndc( 让你得逞) 来在线更新 named. 所以named服务在启动时, 必须通过 rndc来管理启动: ** bind的named服务在启动的时候, 会去通过rndc 和named之间的 TCP的套接字(hmac md5证书)来连接rndc服务器. 如果找不到rndc服务及其配置文件(如: /etc/rndc.conf) ,就会报错,虽然你看 named服务进程是 running, 但是dns解析会error! **
为什么要用 下载的方式 编译安装? 因为虽然用yum也可以安装 bind, 但是由于它安装的版本通常来说比较旧, 也可能会有一些 已知的安全 通知问题 所以 用在 官网下载较新版本的 bind包来编译安装 会更好? 但是 yum安装 会自动解决 包的dependencies 问题和 包的更新update问题. 更省心...
- 如果用putty 登录 无X界面,就要使用 wget 来下载bind-9.10.6:
wget https://www.isc.org/downloads/file/bind-9-10-6/下载下来的名字就是bind-9-10-6, 要将这个文件改名为: ...tar.gz - will be updated: 是说低版本的包将要被升级, will be an update : 是说升级到哪个版本的包
- 安装包的时候, 会首先 "处理依赖" Processing Dependency", 然后进行 "Running transaction check" 交易检查(交易检查 就是 : 主要是检查被依赖包的版本是否恰当会不会过低, 需要升级" 如果 transaction check error错误,可能是版本冲突的原因, 需要: 先卸载低版本,然后执行: yum update).
关于thinkphp的版本?
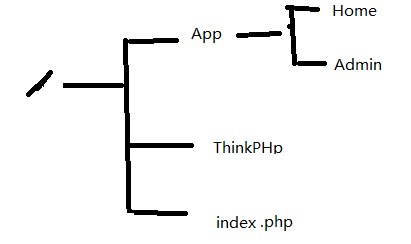
在新的版本中, 使用了应用分组.
以前是使用多个 应用程序, 平级的, 比如最常见的两个独立的应用程序, 前台和后台, Home和Admin.它们是平级的, 且目录跟tp是在同一个地方.
而现在分组后, Home和Admin是作为 一个大的/总的应用程序 App下的两个应用分组,是两个目录. 而App跟ThinkPHP是平级的.
tp版本从3.0, 3.1, 3.2. 其中3.1和3.2 的修订版最后都是3,即最大的版本: 3.1.3, 和3.2.3
3.1.2是 比较低的, 旧的版本, 而3.2.x是一个比较大的 重大的升级, 变化较大, 可以认为是 4.0的版本. 比如: 3.1中的库核心目录叫lib, 而在3.2中叫 Library, 3.1中还没有现成的index.php入口文件, 3.2中就已经给你写了一个入口文件了. 而且在开发分组和独立分组上也有了较大的差别.
通常对于 编译安装的软件, 默认的是 放在 /usr/local 目录中, 但是要注意的是, 放在local中的时候, 被安装软件的内容是按类别分别的/分散地 放在 /usr/local/bin, /usr/local/sbin /usr/local/lib, include ,share, etc等中的, 实际上, 还是没有按软件名称进行 集中放置的, 所以 通常应该设置 --prefix=/usr/local/soft_name, 这样就会在soft_name下分别创建bin, sbin, lib, etc等进行集中放置该软件的内容了.
杂项
- 在vim的正则表达式中, 要表示行号, 该用什么?
如果是在 normal模式下, 到行首和行尾是使用的 gg, G(shift + g). 而$ 则表示 到当前行的 末尾
但是, 如果是在 command模式下, 即vim的正则搜索/替换/删除的冒号模式下, 要表示第一行和最后一行则不是用 gg,和 G了 , 而是1, 和 $ (即, 这个$, 在不同的模式下, 表示不同的含义: 在normal下, 它是当前行的末尾, 而在editor模式下, 他表示的是 最后一行)
通常, 在 vim冒号模式/编辑模式下, 正则模式下, 表示行号的方式有这么几种:
- 用 1, 或者0 表示第一行,
- 用 $ 表示最后一行, 注意不是用 G
- 用点号. 表示 当前行, 这个就不必用set nu去查看行号了.
- 用 + 或 - 表示相对行, 比如
.,.+8 - 最重要的是, 不管是替换还是 删除命令, 前面的范围部分, 以及命令部分, 都可以有 空格的, 而且空格的数量可以随便加, 但是 在正则表达式部分, 则要严格控制 空格的写法. 因为在 非正则匹配部分, 空格只是起分割的作用, 不管多少, 而正则匹配部分则是有严格的实际意义的! 不能随便加
比如, 摘自网页的:
以下命令将文中所有的字符串idiots替换成managers:
:1,$s/idiots/manages/g
通常我们会在命令中使用%指代整个文件做为替换范围:
:%s/search/replace/g
以下命令指定只在第5至第15行间进行替换:
:5,15s/dog/cat/g
以下命令指定只在当前行至文件结尾间进行替换:
:.,$s/dog/cat/g
以下命令指定只在后续9行内进行替换:
:.,.+8s/dog/cat/g
**你还可以将特定字符做为替换范围。比如,将SQL语句从FROM至分号部分中的所有等号(=)替换为不等号(<>):**
:/FROM/,/;/s/=/<>/g
要注意理解正则匹配中, 要替换的内容, 指的是 你正则表达式仅仅匹配到的内容, 如果没有匹配的部分, 是不会被替换的. 比如: . , $-1 s/^#\ //g 就是将当前行 到倒数第一行的内容 表达式中的正号 负号, 可以看作是加减号, 也可以看作是 相对 行号...比如: $-1, .+8, ...
tail +n的用法
- tail和head本身可以直接带文件名, 而不只是对 管道过来的数据进行操作
- head 和 tail 都应该带上 -n选项, 否则后面的数字会被当作是文件名 而报错
- head和tail的 行数 都可以是 带正负号 的数字, 其中正负号和 不带符合的数字相同 时 遵循的规则是: 头正尾负, 即
head -n 5 foo.txt 等同于 head -n +5 foo.txt而tail -n 10 foo.txt 等同于 tail -n -10 foo.txt - 而如果后面的数字 是相反数的时候, 代表的含义略有不同:
head -n -3 foo.txt表示的是 去掉 末尾的 3行文字 而tail -n +5 foo.txt表示的是 从开头的 第5行开始(注意, 要包括这个第5行)直到末尾的行数全部显示。 - 为什么会这样呢? 因为head 表示的总是输出 文件前面的部分(开头的部分), 而 tail 表示的总是输出 文件末尾的部分。
killall和 kil的区别
- 第一, killall是杀死这个命令程序的 所有 进程, 而kill指的是 只杀死指定pid 进程号的程序
- 第二, killall因为要杀死所有 同名的进程(或线程),所以,后面跟的是 程序的名称; 而kill 后面就只能跟进程的id号pid。
但是 他们都需要发送 -9 的停止信号.
dns中的术语?
dns中 soa是什么意思: start of authority: 开始授权, 后面开始写 区域定义
rndc是什么: "让你得逞", remote name deamon control, 是名字服务的远程控制, named 服务, 必须要有rndc服务, 而且要rndc服务起来并由 rndc来管理它. named服务才能正常运行和解析
dig -t NS . 是什么意思 : 去挖掘 . 这个根域名服务器的记录和信息, 当获得 控制台输出后,就可以 重定向到named.ca文件
named.ca是什么文件? 他表示 dns服务器的所有 的 根域名服务器的 信息. 当我们本地的 生产性 域名服务器本地 没有顶级 域名的信息时, 要把dns查询请求发送给 根, 然后让 根dns服务器去返回 其他 下级(子级)域名服务器的信息. 那么这个根域名服务器的信息就放在 named.ca中.
hint表示链接? 表示 named.ca这个文件, 只是一个链接, 其数据库并没有在本地机器上.
最重要的是: 全球的 根 dns服务器共有 13个, 那么 named.ca这个文件 中, 应该包含有 这13个 服务器的 A (address ip) 记录内容才行, 而不只是 这13个根dns服务器的域名
dhcp的协议为什么叫bootp? shutdown和reboot的区别? tail -f的用法 -F
- 关机的命令有很多, 要了解他们的层次. 总的来说, 最终的实现都是交给
init ?这个命令, 当? =0 的时候,init 0就表示 关机,init 6就表示重启.
但是, 规范的, 安全的关机命令, 以后都应该使用: shutdown, 因为shutdown 是一个安全的关机命令, 他会做一些处理善后工作, 比如: 会发送 通告/广播消息给其他 同时登录到这台机器的终端, 告诉他们机器即将关闭; 会指定 关机时间; 而且会 写入 缓存(flush cache). 这样 会避免程序内容和数据的丢失等.
而 halt是直接关机, 不会 做这些善后工作;
reboot是 重启命令, 关机后 再重启.
相对应的, 实际上, shutdown都有 对应的选项 : 比如: shutdown -h = halt, shutdown -r = reboot.
所以以后都用 shutown命令就好了. 而且 shutdown 有很多实用的选项:
-h, -r, -c: cancel 表示取消先前发出的shutdown命令
-k: 只是发出警告信息, 并不真的关机.
他的 命令格式是: shutdown [options] TIME [memssage]
shutdown 如果没有指明 message, 会默认的 报告: for maintenance. maintain的名词, maintenance: during routine maintenance
**注意: time参数是 必须的, 否则会报错, 他要知道 什么时候关机? 有三种表示方法: ** 有意义的单词 NOW; +m 表示多少分钟后关机, m表示分钟的数字; hh:mm指定关机的绝对时间.
- bootp分服务器端和客户端, 服务器端的叫 bootps, 使用的是 67号端口的tcp/udp, 客户端的叫bootpc 使用 68端口的tcp/udp
[root@localhost foo]# cat /etc/services | grep -nE 'boot'
71:bootps 67/tcp # BOOTP server
72:bootps 67/udp
73:bootpc 68/tcp dhcpc # BOOTP client
74:bootpc 68/udp dhcpc
bootp 是比较老的分配协议, dhcp(注意就是dhcp后面没有d) 是bootp的升级版. 有两个优点: bootp需要事先知道客户端的mac地址, 而dhcp不需要; bootp分配地址后, 通常是静态的地址, 而dhcp是动态可变化的.
- tail -f 是可以 跟踪 文件末尾的变化和新增内容 的, 其中 -f是follow的意思, 但是 当 被跟踪文件 被移动或删除的情况下, -f可能会停止继续输出, 而这时候, 可以用 -F 来一直跟踪, 他可以重建 被跟踪文件...
linux的shell 编程中, 凡是 循环语句, 不管是while 还是用for, 其中的循环体, 都是放在 do ... done 之间的
关于 shell中的 双圆括号的运用 , 看这篇文章讲透了: https://www.cnblogs.com/linuxprobe/p/5634208.html , 很好.
双圆括号, 是对 [, [[, test等的扩展. 可以只 使用双圆括号代替他们: features:
双括号中的运算完全支持c语言的所有运算符号,比如 a++, a--, a>1?true: false, 其次, 双括号中的所有变量引用都不需要加 $; 可以扩展 四则运算\逻辑运算\结构运算if while for等; 但是要注意的是, 双括号中的是表达式, 可以是多个表达式, 之间用逗号分割, 但是要获得 双括号的值, 比如你要 echo, 你要赋值, 则必须在双括号前面加上 $
关于单中括号 和 双中括号的区别: 参考: http://blog.csdn.net/good_habits/article/details/27708745
一个最大的区别是: 单中括号会进行 变量的扩展(如果是多个单词的字符串, 会把它们当作多个单词来看待, 这时候会产生错误), 所以像 name="Smith Jonh" ; if [ $name = "Smith Jonh" ]; echo ... 会报语法错误, 因为单中括号 会将 $name 扩展成 if [ Smith John = "Smith John" ], 从而认为 Smith 是多余的单词 而报错, 这时候, 使用单中括号, 应该将 变量用 双引号括起来, 明确地告诉这是一个 完整的 字符串.
而使用 双 中括号 则不会扩展, if [[ $name = "Smith John" ]] ... 则不会报错...
linux的shell脚本 的语句和语句之间 需要分割. 有两种分割方式, 一种是 用 分号, 另一种是 用 回车符 两种都可以.
另外: 一个大的原则是 : 凡是在结构语句中, 比如if, for, while前面的条件 语句(注意这些if while for 分句都是 一个语句, 一个判断 语句! 它 跟后面的do语句, 之间都需要加 分号或回车进行分割.
然后就是 凡是shell中的所有结构体(if, while, for ,until等 ) 中的body部分, 都必须有 类似 C语言中的 大括号 进行括起来. shell是用 关键字 进行来 "括起来"来的, 比如: if 结构体中, 要用 then...else....fi来括起来, while和for等要用 do ...done 来括起来. 这样的话, 就不会忘记写then或do等关键字了.
关于echo的一个用法是: echo 本身会照原样输出 后面的内容, 不管你有没有加 双引号. 但是有一点: echo 遇到 $(()) 等之类的 计算表达式的时候, 会 先将 表达式的值计算出来然后再打印,比如:
[root@localhost foo]# echo b=$((a+3))
b=6
### 关于shell编程, 这一篇就够了: http://blog.csdn.net/crazyhacking/article/details/10182563
就是关于 可以用在if while for等语句中 表示条件判断的情形
主要有三种条件判断: 1. 是关于字符串的逻辑运算 2. 是关于 整数的逻辑运算, 3. 是关于文件的逻辑运算
- 关于字符串的逻辑运算有: =, !=, -n, -z, 如果要比较大小, 使用 反斜杠转义后的
\>, 或 \<, 最重要的是字符串支持 单个字符串判断, 比如:if [ "$name"], 但是 整数就不支持这种单个的逻辑运算 - 关于整数的逻辑运算, 要用 字符运算符, 如: -eq, -ne, -gt, -lt, -ge...
- 关于文件的逻辑运算, 包括: -f, -d, -r, -w, -x, -l, -s(文件大小非零)
而多个逻辑表达式 的 混合运算 可以用 -a, -o, ! , 也可以用对应的 &&, || ,! 但是 前者要放在一个 中括号内, 而后者要放在两个 单独的 中括号里面,比如: if [ $a -eq 1 -a $b -eq 2] 用&&就是 if [ $a -eq 0 ] && [ $b -eq 2 ];
**关于字符串匹配的if判断是 **: if [ 反引号echo $name | grep -e pattern ] ; then ... 反引号
要注意的是: 在 比较字符串是否相等的时候, 后面要加上一个附加的 额外字符(任意字符,比如x), 如果某个变量为空 str= 在判断是否为空的时候, 不能这样写if [ $str = '' ] 而是 直接加上一个 末尾的附加字符串 来比较, 比如: if [ "$str"x = "x" ];
在shell中, 跟其他编程语言对字符串变量的 认定是一样的, 即变量取名的时候, 都是"最大程度的 贪婪匹配", 比如, 本来有一个变量是 str, 但是如果你写成: `if [ $strx = 'x' ] ` 那么这时候, 他不会认为是 变量 `$str` 和字符x的连接, 而是直接把他当成 变量 `$strx`了, 因为之前 的 `$strx` 变量没有申明, 变量为空, 所以仍然会报错: unary operator expected.... 即:
### 凡是你 需要将变量和后面的字符/字符串 相区别, 而不想让 shell认为是一个整体的变量名的时候, 就应该用 双引号 进行 分割 /界定
[root@localhost ~]# str=
[root@localhost ~]# if [ $strx = "x" ]; then echo 'right'; fi
-bash: [: =: unary operator expected
[root@localhost ~]# if [ "$str"x = "x" ]; then echo 'right'; fi
right
比较两个字符串是否相等的办法是:
if [ "$test"x = "test"x ]; then
这里的关键有几点:
1 使用单个等号
2 注意到等号两边各有一个空格:这是unix shell的要求
3 注意到"$test"x最后的x,这是特意安排的,因为当$test为空的时候,上面的表达式就变成了x = testx,显然是不相等的。而如果没有这个x,表达式就会报错:[: =: unary operator expected
- pidof和pgrep 都是列出进程的id号的命令.
pidof 需要 精确 程序的名字, 而 pgrep 只是需要 程序的 大致名字, 可以进行模糊匹配.
而pkill 则是根据 程序的名字, 杀死程序.
at命令的使用
garble: [ga:bl], 断章取义, 曲解, 歪曲, 篡改.
at 命令提示 garbled time表示时间设置不对.
at命令表示的是, 在将来某个指定的时间 执行某个事件。相当于win的 计划任务
格式是:at [options] 时间 + 要执行的具体任务
也可以有at 交互式命令输入
**在交互式的at命令中, 结束命令的输入 是 按 ctrl+d , 注意不是 ctlr_c, ctrl_c是放弃, 取消当前输入的命令, 取消at 安排! **
at每设置一次, 设置一个job, 显示已经设置的 job是: job 序号 at 执行时间. 显示的时候, 总是从 上到下 显示最近设置的 at . 即按 job 从大到小的顺序进行
at 有很多别名, 比如: at -l =atq, at -d =atrm 等等.
at 也可以把要执行的命令放在 一个文件中, 使用 -f 选项:
at -f jobs.at_todo 23:00 2010-12-12
运行at命令需要开启 atd 服务
at命令的其他细节
- at命令是在指定的时间 **必须执行 一次, 而如果不是很重要的/紧急的任务, 非必须的任务, 可以使用 batch命令. 而如果是 周期性的执行预订的命令则使用 crond文件...
- at 命令指定命令的时候, 要指定命令的 全路径, 比如 要指定 /bin/echo, /bin/cp 而不要只是说 echo, cp等.
- at默认的是显示你已经设置了那些jobs, 要查看具体的某个job的内容, 要使用 at -c jobid (其中的-c表示 --content内容的意思).
- at 的配置是/etc/at.allow, /etc/at.deny限制哪些用户可以使用at, 哪些用户不允许使用.. 规则是: 如果allow和deny都不存在, 则只有root用户可以使用at命令, 如果 allow和deny都存在, 则按里面写的用户决定.
linux系统中 很多经常变化的内容都 放在 /var目录中, 有的直接放在 /var下, 有的放在/var下的spool, 一般的进程号放在 /var/run/目录下, 等等, at命令的 内容项要放在 /var/spool/at, /var/run/at/里面放的是pid文件.
quota是什么意思
是磁盘对用户的配额设置, 他会首先去读取 /etc/filesystems中的内容, 然后显示所有的fs的配额
echo >> 是 添加, 那么要删除 某一行呢? : 使用 sed命令. 很简单: sed -i -e '$d' foo.txt
NURBS曲线: 是非统一有理B样条曲线:
Non-Uniform 是指一个控制顶点的影响力范围可以能够改变,
Rational 有理, 是指曲线可以用数学表达式来定义
B 样条曲线 spline : 因为在模拟 拟合多个点构成的曲线时, 是用 有弹性的木条来拟合的, 所以叫样条曲线.
如何设置ip地址和网关和dns服务器?
route add default gw ...dev eth0? : dev是说要设置哪个网卡的默认网关? 你可以具体的指定是 哪个 网卡的 默认网关...
动名词和名词的区别?
比如,amazing, 动名词具有动词的性质,所以可以带其他成分宾语、或状语成分。而其他普通的名词则不能。
彻底地掌握 sed 工具了:
sed 是流编辑, 它会把后面跟的文件 中的内容, 一行一行地读出来, 然后进行处理, 然后默认的输出到控制台. 他的格式是: sed [options] '编辑的命令脚本' files
即sed的后面是选项, 和 你要对文件进行什么样的编辑命令, 最后是要编辑的文件名称.
一句话深入到sed的实质: sed实际上就是跟 vim的 编辑命令/冒号命令 完全是一样的! 你知道vim的冒号命令/命令模式的使用, 就一样的使用sed命令了. 只是sed命令不需要打开文件...
命令脚本组成: 编辑范围 + 编辑命令,
默认的是 对所有的行都进行相应的编辑, (相当于%), 当然你也可以 指定只 编辑哪些范围, 其他的不满足条件的行不编辑
编辑的时候, 是把当前行 读取 -> 拷贝 到 缓冲区, 然后进行编辑操作.
编辑范围比如: 1 | 1, $| /^a.A$/ | /^a.A/, $ 等等
编辑命令包括: 增删该: i , d , s , a , c \ 等, 命令的格式是 单字符命令中间加一个空格后, 然后 用 反斜杠 . 不过注意的是, 命令后面可以不加 空格, 也可以不加反斜杠, 什么都不加, 加上空格, 反斜杠只是 便于阅读和理解.
总之, sed是很智能的, 基本上, 你不写 一些辅助代码的时候, 都尽量 来解析...
sed -e 'script - expression' 命令中的 -e 等于 --expression=script... , -e可以不要, 不写.
script-expression表示的是 "add the script to the commands to be executed" 要添加到命令中去执行的脚本...
i, a,c,d, s等命令中, 后面的空格和反斜杠不是必须的, 只有当解析出现错误的时候, 才去添加空格或反斜杠.
注意a和i的 含义, 他们是表示 在当前 正在处理的行 的前面或后面 添加/插入一行.
c是替换 整个处理的行, 而s只是替换 行中的 字符串. 两个不一样.
同时 在执行sed 的时候, 可以同时指定多个 -e脚本命令表达式, 来一次性地执行多个指令, 比如: cat /etc/at.deny | sed -e ' $a \foo' -e '$a \bar' -e '$a \ itoto'
- 为什么dhcp服务器不是挨着依次分配ip地址的? dhcp服务器有的是从大到小分配地址, 而有的是从小到大分配地址的呢?
这个要看os的不同, linux是从大到小分配ip地址的. 而win与之相反, 是从小到大进行分配的.
还有的是要分配静态地址, 而有的还要和client进行ip地址的协商. 通常如果没有其他抢地址的话, 都是在refresh时间到了的时候, 还是分配原来的ip地址.
ARP和DNS是一样的吗?
虽然他们 都是 进行 ip地址转换的, 但是转换的 目标不同 arp是将 ip -> mac 地址. 而dns 是将 域名 dn: domain name ->ip地址.
gra'tuitous arp: 免费arp, 无故arp, 是在启动的时候, 发送一个 arp请求,得到ip地址对应的mac地址
ARP协议是“Address Resolution Protocol”(地址解析协议)的缩写。 就是在 局域网中, (同一个网段, 或连接在 同一个 交换机上的 所有机器) 进行通信的协议. 那为什么要进行解析呢?
因为, 在第三层传输的时候, 使用 是 ip地址, 传输单位是包 package, 而当包下传到 第二层的时候, 分到局域网中时,进行传输的是“帧”,帧里面要封装 目标主机的MAC地址的。
在以太网中,一个主机要和另一个主机进行直接通信,必须要知道目标主机的MAC地址。但这个目标MAC地址是如何获得的呢?它就是通过地址解析协议获得的。 ARP协议的基本功能就是通过目标设备的IP地址,查询目标设备的MAC地址,以保证通信的顺利进行。ARP协议的工作原理
在每台安装有TCP/IP协议的电脑里都有一个 ARP缓存表,表里的IP地址与MAC地址是一一对应的.
以主机A(192.168.1.5)向主机B(192.168.1.1)发送数据为例。当发送数据时,主机A会在自己的ARP缓存表中寻找是否有目标IP地址。如果找到了,也就知道了目标MAC地址,直接把目标MAC地址写入帧里面发送就可以了;
但是, 如果在ARP缓存表中没有找到相对应的IP地址,主机A就会在网络上发送一个广播,目标MAC地址是“FF.FF.FF.FF.FF.FF”,这表示向同一网段内的所有主机发出这样的询问:“192.168.1.1的MAC地址是什么?”网络上其他主机并不响应ARP询问,只有主机B接收到这个帧时,才向主机A做出这样的回应:“192.168.1.1的MAC地址是00-aa-00-62-c6-09”。这样,主机A就知道了主机B的MAC地址,它就可以向主机B发送信息了。
ARP的缓存?? : : 当 第一次 找到 主机B的 mac地址后 , 为了避免后面再多次进行询问, 需要暂时将 这个B 主机的条目保存下来, 即就是要 更新了自己的ARP缓存表,下次再向主机B发送信息时,直接从ARP缓存表里查找就可以了。
ARP的老化, 如同你注册一个邮箱一样, 如果你注册后, 在一段时间内都没有用过, 那么它就会给你删除 即老化 机制:::: 但是有一个问题, 如果把每次 曾经通过信的主机的mac地址条目不管时间 过了多久 都永远保存, 那样, arp表将会很大, 既不便于存储, 浪费存储空间, 又不便于查询 将会浪费很多的查询时间...
所以:: ARP缓存表采用了老化机制,在一段时间内如果表中的某一行没有使用,就会被删除,这样可以大大减少ARP缓存表的长度,又 加快查询速度。
ARP攻击 就是通过伪造IP地址和MAC地址实现ARP欺骗,能够在网络中产生大量的ARP通信量使网络阻塞,攻击者只要持续不断的发出伪造的ARP响应包就能更改目标主机ARP缓存中的IP-MAC条目,造成网络中断或中间人攻击。 ARP攻击主要是存在于局域网网络中,局域网中若有一个人感染ARP木马,则感染该ARP木马的系统将会试图通过“ARP欺骗”手段截获所在网络内其它计算机的通信信息,并因此造成网内其它计算机的通信故障。
名称服务有三种情况: hosts文件解析, nis/nis+/nisplus(3.0版本) 网络信息服务, 和dns服务
那么这三种 名称服务的 采用的 先后次序是 怎样规定的呢? 由 文件: /etc/nsswitch.conf : 即: 名称服务切换...
named 区域文件中的各个术语和 名称记录的含义: 参考 https://wenku.baidu.com/view/63544d8ea0116c175f0e4897.html
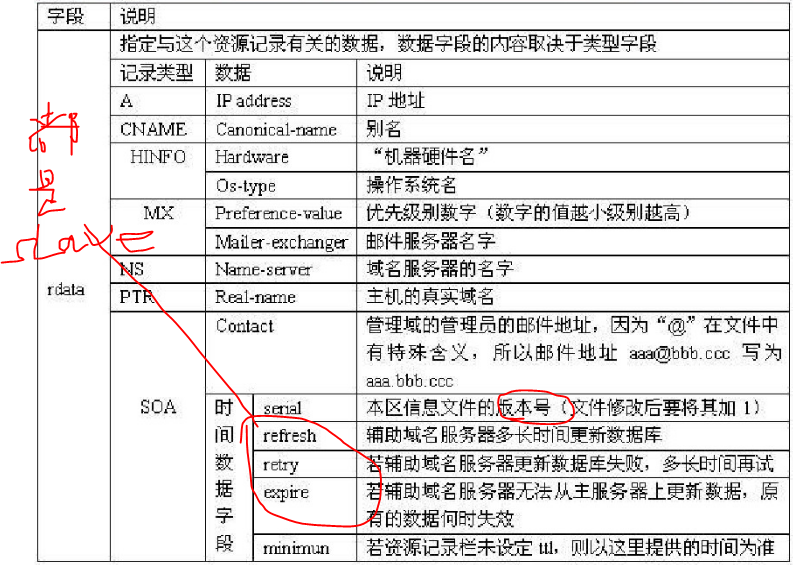
cname: 命名(aliases):
配置named服务之前的 相关术语意思的更多相关文章
- 性能测试学习之路 (三)jmeter常见性能指标(相关术语、聚合报告 && 服务器性能监控配置 && 图形结果 && 概要报告)
1 性能测试目的 性能测试的目的:验证软件系统是否能够达到用户提出的性能指标,同时发现软件系统中存在的性能瓶颈,以优化软件. 最后起到优化系统的目的性能测试包括如下几个方面: 1.评估系统的能力:测试 ...
- Service系统服务(六):rsync基本用法、rsync+SSH同步、配置rsync服务端、访问rsync共享资源、使用inotifywait工具、配置Web镜像同步、配置并验证Split分离解析
一.rsync基本用法 目标: 本例要求掌握远程同步的基本操作,使用rsync命令完成下列任务: 1> 将目录 /boot 同步到目录 /todir 下 2> 将目录 /boot 下的 ...
- 软件测试相关术语(测试策略 && 测试方案 ....)
软件测试有几种不同的定义方法: a.软件测试是为了发现程序中的错误而执行程序的过程. b.软件测试是根据软件开发各阶段的规格说明和程序的内部结构而精心设计的一批测试用例,并运用这些测试用例运行程序,以 ...
- Liunx下配置DNS服务
当Ping 主机名时可以映射出该主机的IP地址,反之亦然.配置并指定DNS服务器可以快速部署集群,不需要每台主机都去修改HOSTS文件即可实现IP与主机名的相互解析.而在Linux下的DNS是用bin ...
- RHEL5.8配置NFS服务
机器配置:4C+16GB 操作系统:RedHat Enterprise Linux 5.8 NFS基础 NFS(Network File System)是Linux系统之间使用最为广泛的文件共享协议, ...
- [转]Ubuntu下配置NFS服务
[转]Ubuntu下配置NFS服务 http://blog.163.com/liu8821031%40126/blog/static/111782570200921021253516/ Table ...
- OpenVAS漏洞扫描基础教程之OpenVAS概述及安装及配置OpenVAS服务
OpenVAS漏洞扫描基础教程之OpenVAS概述及安装及配置OpenVAS服务 1. OpenVAS基础知识 OpenVAS(Open Vulnerability Assessment Sys ...
- Ubuntu下配置tftp服务
Ubuntu下配置tftp服务 1.安装TFTP软件 sudo apt-get install tftp-hpa tftpd-hpa tftp-hpa是客户端,tftpd-hpa是服务器端 2.建立t ...
- Kali Linux常用服务配置教程安装及配置DHCP服务
Kali Linux常用服务配置教程安装及配置DHCP服务 在Kali Linux中,默认没有安装DHCP服务.下面将介绍安装并配置DHCP服务的方法. 1.安装DHCP服务 在Kali Linux中 ...
随机推荐
- MongoDB下,启动服务
D:\MongoDB>mongod --dbpath D:\MongoDB\Data --logpath D:\MongoDB\Log\MongoDB.log --logappend --ser ...
- SpringBoot的json序列化及时间序列化处理
使用场景:前台的多种时间格式存入后台,后台返回同时的时间格式到前台. 1 在config目录下配置jscksonConfig.java package com.test.domi.config; im ...
- Core Java Fundation
http://www.cnblogs.com/cmfwm/p/7671188.html http://blog.csdn.net/fuckluy/article/details/50614983 ht ...
- <3>lua字符串
1.字符串 <1>字符串相连/加法 .. local str = "abc" str = str .. 7 --字符串与数字相连 print(str) --abc7 ...
- url中是否加斜杠/
通常来说,不加斜杠的形式(如”example.jsp”)请求的是相对于当前页面路径的资源 http://localhost:8080/webapp/examole:加斜杠的形式(”/example.j ...
- workerman 7272端口被占用
1/问题:workerman 7272端口被占用 2/策略: 1.查找被占用的端口 netstat -tln netstat -tln | grep 8083 netstat -tln 查看端口使用情 ...
- E. Gerald and Giant Chess
E. Gerald and Giant Chess time limit per test 2 seconds memory limit per test 256 megabytes2015-09-0 ...
- sitecore系统教程之体验编辑器中创建一个项目
您可以使用体验编辑器创建新项目并将其直接插入网页. 注意 如何在Sitecore中创建项目可能会有所不同,具体取决于您拥有的安全角色以及网站的设置方式. 要插入新项目: 在体验编辑器中,导航到要添加新 ...
- 入坑tensorflow
win10 CPU版,anaconda prompt命令行一句话,pip install --upgrade tensorflow搞定.比caffe好装一万倍. gpu版没装成,首先这个笔记本没装cu ...
- 变量为空代表false
name = ''#名字为空即代表False while not name:#not name=False即 真,将执行循环体 print('Enter your name:') name = inp ...