大数据处理框架之Strom: Storm拓扑的并行机制和通信机制
一、并行机制
Storm的并行度 ,通过提高并行度可以提高storm程序的计算能力。
1.组件关系:
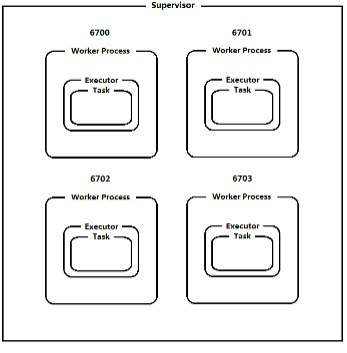
Supervisor node物理节点,可以运行1到多个worker,不能超过supervisor.slots.ports数量;
worker:工作进程,即jvm.为特定拓扑的一个或者多个组件Spout/Bolt产生一个或者多个Executor。默认情况下一个Worker运行一个Executor
Executor:线程Thread,为特定拓扑的一个或者多个组件Spout/Bolt实例运行一个或者多个Task。默认情况下一个Executor运行一个Task。
Task:任务
2.代码配置并行度
//工作进程Worker数量
Config config = new Config();
config.setNumWorkers(3); //注意此参数不能大于supervisor.slots.ports数量。 //执行器Executor数量 线程数量
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(id, spout, parallelism_hint); //设置Spout的Executor数量参数parallelism_hint
builder.setBolt(id, bolt, parallelism_hint); //设置Bolt的Executor数量参数parallelism_hint //任务Task数量 指定任务数 会平均分配到执行器里
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(id, spout, parallelism_hint).setNumTasks(val); //设置Spout的Executor数量参数parallelism_hint,Task数量参数val
builder.setBolt(id, bolt, parallelism_hint).setNumTasks(val); //设置Bolt的Executor数量参数parallelism_hint,Task数量参数val
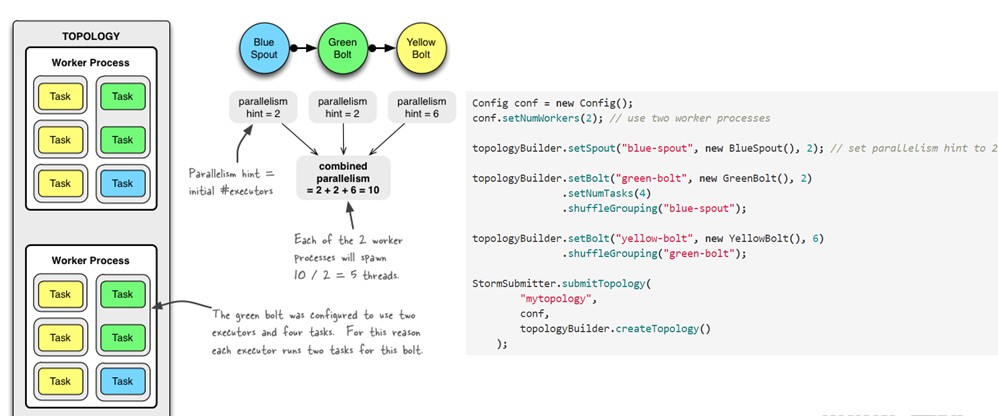
图解并行度:
2.1 默认1个worker,1个Executor,1个task
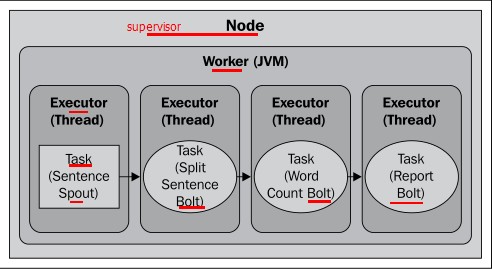
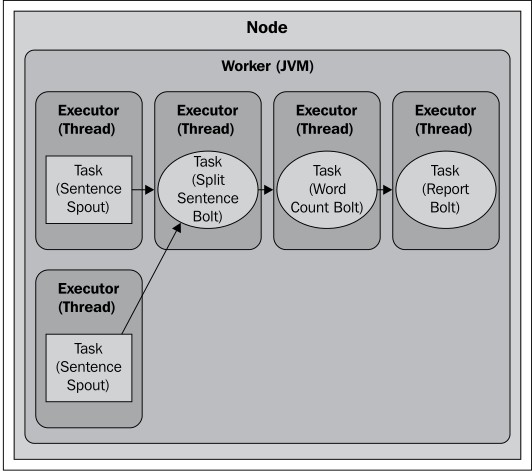
2.2 spout 设置并行度2
builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
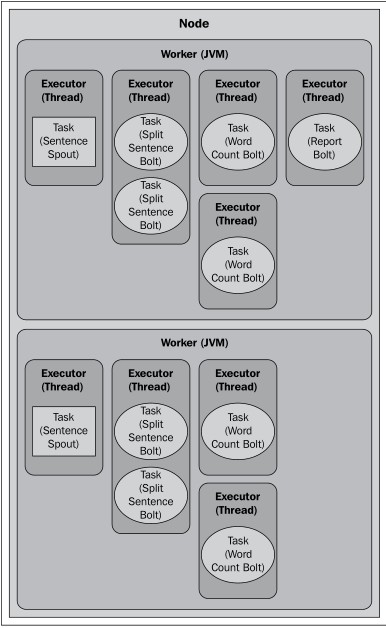
2.3 设置多worker 多并行度,多任务
#设置两个worker
Config config = new Config();
config.setNumWorkers(2);
#splitBolt并行度2,任务数4
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2).setNumTasks(4).shuffleGrouping(SENTENCE_SPOUT_ID);
#splitBolt并行度4
builder.setBolt(COUNT_BOLT_ID, countBolt, 4).fieldsGrouping(SPLIT_BOLT_ID, newFields("word"));
3.并行度再平衡
使用storm命令或者storm UI 操作
# 重新配置拓扑
# -w 设置10秒超时时间
# -n “myTopology” 拓扑使用5个Worker进程
# -e “blue-spout” Spout使用3个Executor
# -e “yellow-blot” Bolt使用10个Executor
storm rebalance myTopology -w 10 -n -e blue-spout= -e yellow-blot=
附示例:
二、通信机制:
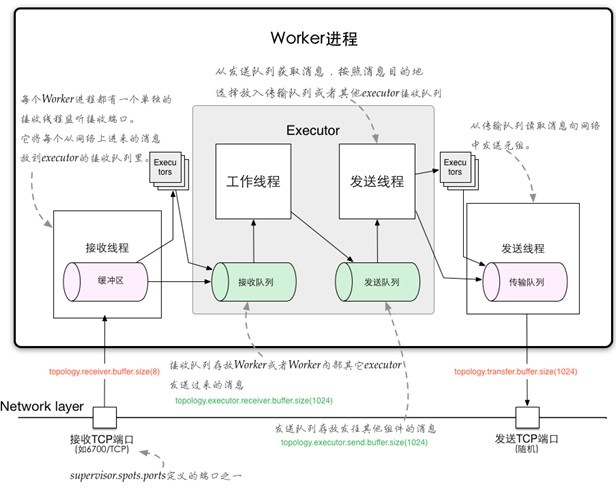
1、Worker进程间的数据通信
ZMQ
ZeroMQ 开源的消息传递框架,并不是一个MessageQueue
Netty
Netty是基于NIO的网络框架,更加高效。(之所以Storm 0.9版本之后使用Netty,是因为ZMQ的license和Storm的license不兼容。)
2、Worker内部的数据通信
Disruptor
实现了“队列”的功能。
可以理解为一种事件监听或者消息处理机制,即在队列当中一边由生产者放入消息数据,另一边消费者并行取出消息数据处理。
参考:
Storm拓扑的并行度(parallelism)
大数据处理框架之Strom: Storm拓扑的并行机制和通信机制的更多相关文章
- 大数据处理框架之Strom:Storm集群环境搭建
搭建环境 Red Hat Enterprise Linux Server release 7.3 (Maipo) zookeeper-3.4.11 jdk1.7.0_80 Pyth ...
- 大数据处理框架之Strom: Storm----helloword
大数据处理框架之Strom: Storm----helloword Storm按照设计好的拓扑流程运转,所以写代码之前要先设计好拓扑图.这里写一个简单的拓扑: 第一步:创建一个拓扑类含有main方法的 ...
- 大数据处理框架之Strom:认识storm
Storm是分布式实时计算系统,用于数据的实时分析.持续计算,分布式RPC等. (备注:5种常见的大数据处理框架:· 仅批处理框架:Apache Hadoop:· 仅流处理框架:Apache Stor ...
- 大数据处理框架之Strom:Flume+Kafka+Storm整合
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 apache-flume-1.6.0 ...
- 大数据处理框架之Strom:redis storm 整合
storm 引入redis ,主要是使用redis缓存库暂存storm的计算结果,然后redis供其他应用调用取出数据. 新建maven工程 pom.xml <project xmlns=&qu ...
- 大数据处理框架之Strom:kafka storm 整合
storm 使用kafka做数据源,还可以使用文件.redis.jdbc.hive.HDFS.hbase.netty做数据源. 新建一个maven 工程: pom.xml <project xm ...
- 大数据处理框架之Strom:DRPC
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 一.DRPC DRPC:Distri ...
- 大数据处理框架之Strom:容错机制
1.集群节点宕机Nimbus服务器 单点故障,大部分时间是闲置的,在supervisor挂掉时会影响,所以宕机影响不大,重启即可非Nimbus服务器 故障时,该节点上所有Task任务都会超时,Nimb ...
- 大数据处理框架之Strom:事务
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 apache-flume-1.6.0 ...
随机推荐
- eslint 代码检测工具
jshint 检测工具不够灵活下,道格拉斯(何许人也?json创造者,javascript重要任务,犀牛那本书就是他写的). 文档地址: 中文地址 English 安装 利用npm全局安装eslint ...
- Android Studio 下载与安装配置
一.下载 Android Studio下载链接:http://www.android-studio.org/ 1.进入安卓中文社区官网进行下载. 2.下载完成. 二.安装与配置环境 1.选择“此电脑” ...
- 对CountDownLatch的初步学习
CountDownLatch的中文翻译为"闭锁",在JDK1.5中 CountDownLatch类加入进来.为程序猿进行并发编程提供有利的帮助. 首先我们先看看JDK文档中对于Co ...
- Linux下Redis的安装与启动
一. 进入目录(我们准备将redis装入opt文件夹) $ cd /opt/ 二.下载redis压缩包 $ wget http://download.redis.io/releases/redis-4 ...
- SVN服务的模式和多种访问方式 多种访问原理图解与优缺点
SVN企业应用场景 SVN任是当前企业的主流.git正在发展,未来会成为主流.如果大家精力足够,建议同时掌握. 1.4运维人员掌握版本管理 对于版本管理系统,运维人员需要掌握的技术点: 1.安装.部署 ...
- docker+Nexus Repository Manager 搭建私有docker仓库
使用容器安装Nexus3 1.下载nexus3的镜像: docker pull sonatype/nexus3 2.使用镜像启动一个容器: docker run -d -p 8081:8081 -p ...
- 20190228 搭建Hadoop基础环境
下载VMware 12 版本以上 下载CentOS 7以上版本 安装虚拟机,安装系统时,注意设置root 账号和密码 虚拟机配置网络,命令ip addr 查看IP 地址,(配置网络网上有很多办法,百度 ...
- v-show 和 v-if 对 v-chart的影响
借鉴:https://blog.csdn.net/xiaxiangyun/article/details/78909991 使用v-show控制tab切换 其中一个tab数据请求后显示第二个tab,第 ...
- one order 处理流程
- CentOS在VMware中 网络配置
一. 将centos安装好之后,发现ping, ifconfig等常见的命令都用不了,出现unknown service或command not found这样的字眼,这让我十分无语.查了一下资料,i ...