熔断监控集群(Turbine)
Spring Cloud Turbine
上一章我们集成了Hystrix Dashboard,使用Hystrix Dashboard可以看到单个应用内的服务信息,显然这是不够的,我们还需要一个工具能让我们汇总系统内多个服务的数据并显示到Hystrix Dashboard上,这个工具就是Turbine。
添加依赖
修改 spring-cloud-consul-monitor 的pom文件,添加 turbine 依赖包。
注意:因为我们使用的注册中心是Consul,所以需要排除默认的euraka包,不然会有冲突启动出错。
pom.xml

<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-turbine</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</exclusion>
</exclusions>
</dependency>
启动类
启动类添加 @EnableTurbine 注解,开启 turbine 支持,添加 @EnableDiscoveryClient 注解,把自己也作为服务注册到注册中心。
ConsuleMonitorApplication.java
package com.louis.spring.cloud.consul.monitor; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.netflix.hystrix.dashboard.EnableHystrixDashboard;
import org.springframework.cloud.netflix.turbine.EnableTurbine; @EnableTurbine
@EnableHystrixDashboard
@EnableDiscoveryClient
@SpringBootApplication
public class ConsuleMonitorApplication { public static void main(String[] args) {
SpringApplication.run(ConsuleMonitorApplication.class, args);
}
}
修改配置
修改配置,配置注册服务信息,添加turbine配置。
application.yml
server:
port: 8531
spring:
application:
name: spring-cloud-consul-monitor
cloud:
consul:
host: localhost
port: 8500
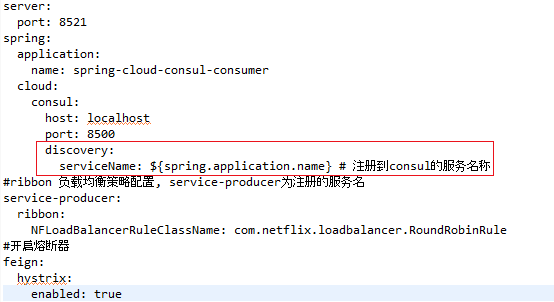
discovery:
serviceName: ${spring.application.name} # 注册到consul的服务名称
turbine:
instanceUrlSuffix: hystrix.stream # 指定收集路径
appConfig: spring-cloud-consul-consumer # 指定了需要收集监控信息的服务名,多个以“,”进行区分
clusterNameExpression: "'default'" # 指定集群名称,若为default则为默认集群,多个集群则通过此配置区分
combine-host-port: true # 此配置默认为false,则服务是以host进行区分,若设置为true则以host+port进行区分
注册消费者
因为turbine收集信息是从注册中心获取相关服务或集群的,所以需要把监控目标也注册到注册中心。
修改 spring-cloud-consul-consumer,在启动类添加 @EnableDiscoveryClient 注解,注册服务。

修改配置文件,写入配置服务名称。
测试效果
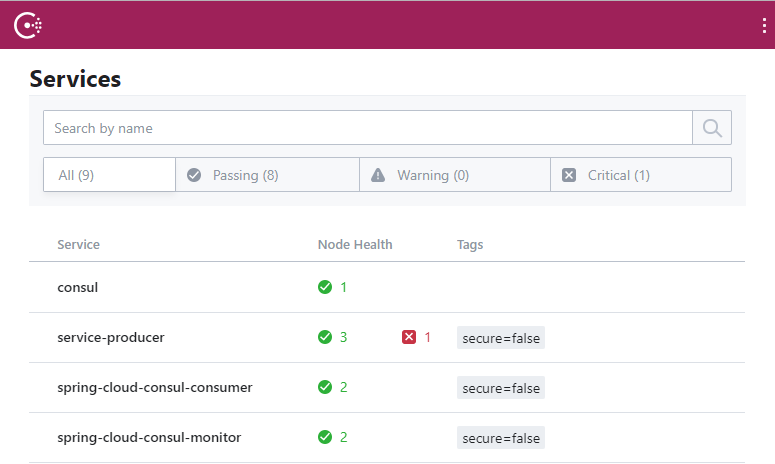
依次启动 spring-cloud-consul-producer、spring-cloud-consul-consumer、spring-cloud-consul-monitor,访问 http://localhost:8500 查看注册中心管理界面。
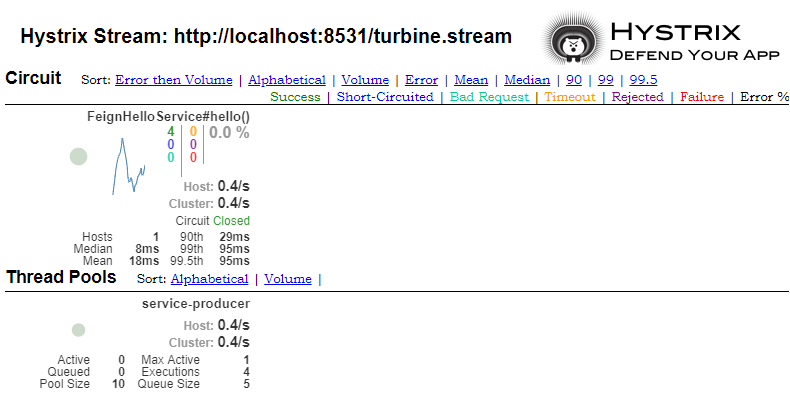
确认服务调用无误之后, 访问 http://localhost:8531/hystrix/,输入 http://localhost:8531/turbine.stream,查看监控图表。
如下图所示,就是聚合多个Hytrix消费者的信息显示,由于我内存有限只启了一个消费者,所以看起来是一样的。
内存足够的话复制几分消费者项目,修改下启动端口号启动就行了。
熔断监控集群(Turbine)的更多相关文章
- Spring Boot + Spring Cloud 构建微服务系统(六):熔断监控集群(Turbine)
Spring Cloud Turbine 上一章我们集成了Hystrix Dashboard,使用Hystrix Dashboard可以看到单个应用内的服务信息,显然这是不够的,我们还需要一个工具能让 ...
- Spring Cloud Hystrix理解与实践(一):搭建简单监控集群
前言 在分布式架构中,所谓的断路器模式是指当某个服务发生故障之后,通过断路器的故障监控,向调用方返回一个错误响应,这样就不会使得线程因调用故障服务被长时间占用不释放,避免故障的继续蔓延.Spring ...
- Hadoop YARN学习之监控集群监控Nagios(4)
doop YARN学习之监控集群监控Nagios(4) 1. Nagios是一个流行的开源监控工具,可以用来监控Hadoop集群. 2. 监控基本的Hadoop服务 调试好脚本后命名为chek_res ...
- Ubuntu 14.10 下安装Ganglia监控集群
关于 Ganglia 软件,Ganglia是一个跨平台可扩展的,高性能计算系统下的分布式监控系统,如集群和网格.它是基于分层设计,它使用广泛的技术,如XML数据代表,便携数据传输,RRDtool用于数 ...
- 用 Heapster 监控集群 - 每天5分钟玩转 Docker 容器技术(176)
Heapster 是 Kubernetes 原生的集群监控方案.Heapster 以 Pod 的形式运行,它会自动发现集群节点.从节点上的 Kubelet 获取监控数据.Kubelet 则是从节点上的 ...
- 用 Weave Scope 监控集群 - 每天5分钟玩转 Docker 容器技术(175)
创建 Kubernetes 集群并部署容器化应用只是第一步.一旦集群运行起来,我们需要确保一起正常,所有必要组件就位并各司其职,有足够的资源满足应用的需求.Kubernetes 是一个复杂系统,运维团 ...
- kubernetes之收集集群的events,监控集群行为
一.概述 线上部署的k8s已经扛过了双11的洗礼,期间先是通过对网络和监控的优化顺利度过了双11并且表现良好.先简单介绍一下我们kubernetes的使用方式: 物理机系统:Ubuntu-16.04( ...
- 用 Heapster 监控集群
Heapster 是 Kubernetes 原生的集群监控方案.Heapster 以 Pod 的形式运行,它会自动发现集群节点.从节点上的 Kubelet 获取监控数据.Kubelet 则是从节点上的 ...
- nagios新增监控集群、卸载监控集群批量操作
1.一定要找应用侧确认每台节点上需要监控的进程,不要盲目以为所有hadoop集群的zk.journal啥的都一样,切记! 2.被监控节点只需要安装nagios-plugin和nrpe,依赖需要安装xi ...
随机推荐
- python静态方法、类方法
常规: class Dog(object): def __init__(self,name): self.name=name def eat(self): print('%s is eating'%s ...
- Node.js 常用命令
1. 查看node版本 node --version 2. 查看npm 版本,检查npm 是否正确安装. npm -v 3. 安装cnpm (国内淘宝镜像源),主要用于某些包或命令程序下载不下来的情况 ...
- from import
from A import B # 只导入A里面的B
- Go语言学习之4 递归&闭包&数组切片&map&锁
主要内容: 1. 内置函数.递归函数.闭包2. 数组与切片3. map数据结构4. package介绍 5. 排序相关 1. 内置函数.递归函数.闭包 1)内置函数 (1). close:主要用来关闭 ...
- makefile 里的 := , = , +=
:= 是在这行代码的时候,直接展开右边的变量. = 是在最终左边变量被使用的时候,才把右边的变量展开. https://stackoverflow.com/questions/10227598/wha ...
- Dynamic Binding
调用方法时,如何决定调用对象还是其父类的方法呢? 在JVM中,根据实际类型(actual type)调用.而非声明类型(declared type),如果实际类型的类中没有该方法,就会沿着inheri ...
- android-------- 多渠道打包(借助友盟移动统计分析)
好久没有发博客了,原因是换工作了,今天端午假期,所以来发一篇博客, 多渠道打包,借助友盟移动统计分析,希望对各位有所帮助 多渠道打包的理解: 渠道包就是要在安装包中添加渠道信息,也就是channel, ...
- Linux中计划任务、周期性任务设置
Linux中计划任务.周期性任务设置 计划任务:指在未来的特定时间里,执行一次某一特定任务.当然,如果同一任务需要在不同时间点执行执行两次.三次或多次,可以视为多个一次看待. 周期性任务:指某一任务需 ...
- 『TensorFlow』分布式训练_其一_逻辑梳理
1,PS-worker架构 将模型维护和训练计算解耦合,将模型训练分为两个作业(job): 模型相关作业,模型参数存储.分发.汇总.更新,有由PS执行 训练相关作业,包含推理计算.梯度计算(正向/反向 ...
- 【微信公众号开发】【13】批量导出公众号所有用户信息到Excel
前言: 1,一次拉取调用最多拉取10000个关注者的OpenID,当公众号关注者数量超过10000时,可通过填写next_openid的值,从而多次拉取列表的方式来满足需求 2,获取OpenID列表后 ...