【Python】爬虫-2
8、 urllib2.urlopen可以接受一个Request对象或者url,(在接受Request对象时候,并以此可以来设置一个URL的headers),urllib.urlopen只接收一个url
9、 urllib 有urlencode,urllib2没有,这也是为什么总是urllib,urllib2常会一起使用的原因
10、 urlencode不能直接处理unicode对象,所以如果是unicode,需要先编码,有unicode转到utf8,举例:
urllib.urlencode (u'bl'.encode('utf-8'))
11、 编解码示例 urllib.quote(空格用%20代替)和urllib.urlencode(空格用+代替)都是编码,但用法不一样

8、 IV. urlretrieve() urlretrieve多数适用单纯的只下载的功能或者显示下载的进度,直接把url链接网页内容下载到retrieve_index.html里了,适用于单纯的下载的功能

8、 在对字典数据编码时候,用到的是urllib.urlencode()
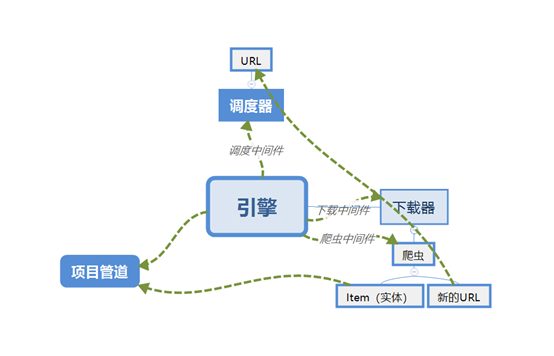
9、 Scrapy组成
(1)引擎(Scrapy Engine):用来处理整个系统的数据流处理,触发事务。
(2)调度器(Scheduler):用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。可以决定下载器下一步要下载的网址并去除重复的网址。
(3)下载器(Downloader):用来下载网页内容,并将网页内容返回给爬虫(Spiders)。
(4)爬虫(Spiders):从特定的网页中提取出需要的信息。可以用它来制定特定网页的解析规则,提取特定的实体(Item)或URL链接。每一个Spider负责一个或多个特定的网站。
(5)项目管道(Item Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
(6)下载器中间件(Downloader Middlewares):位于Scrapy引擎和下载器之间的子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
(7)爬虫中间件(Spider Middlewares):介于Scrapy引擎和爬虫之间的框架,主要工作是处理爬虫的响应输入和请求输出。
(8)调度中间件(Scheduler Middewares):介于Scrapy引擎和调度之间的中间件,处理从Scrapy引擎发送到调度的请求和响应。
10、 Scrapy执行流程
(1) 创建一个Scrapy项目
(2) 引擎从调度器取出一个URL用于抓取
(3) 引擎把URL封装成一个Requests请求然后传给下载器把相应结果下载下来并封装成应答包
(4) 解析应答包
(5) 定义解析规则(Item)
(6) 根据定义规则解析内容后交给实体管道等待处理
(7) 解析出URL交给调度器继续等待被抓取
【Python】爬虫-2的更多相关文章
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python 爬虫(二)
python 爬虫 Advanced HTML Parsing 1. 通过属性查找标签:基本上在每一个网站上都有stylesheets,针对于不同的标签会有不同的css类于之向对应在我们看到的标签可能 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- [python]爬虫学习(一)
要学习Python爬虫,我们要学习的共有以下几点(python2): Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
随机推荐
- rac 关库 启库
关库顺序 先关闭数据库 然后关闭节点资源 [root@rac1 ~]# srvctl stop database -d prod[root@rac1 ~]# srvctl stop inst ...
- Beta阶段——第2篇 Scrum 冲刺博客
Beta阶段--第2篇 Scrum 冲刺博客 标签:软件工程 一.站立式会议照片 二.每个人的工作 (有work item 的ID) 昨日已完成的工作 人员 工作 林羽晴 完成https安全连接的问题 ...
- Oracle 11.2.0.4.0 Dataguard部署和日常维护(1)-数据库安装篇
本次测试环境 系统版本 CentOS release 6.8 主机名 ec2t-userdata-01 ec2t-userdata-01 IP地址 10.189.102.118 10.189.100. ...
- python爬虫---requests库的用法
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多 因为是第三方库,所以使用前需要cmd安装 pip install requests 安装完成后import一下 ...
- 改写了禁用或启用oracle数据库的约束的存储过程
改写了网上某位大侠(最开始的源头是哪位没记住)写的禁用或启用oracle数据库所有约束的存储过程,增加了异常控制,以使发生异常时也可以执行下去. –调用过程: 执行前先 set serveroutpu ...
- const 内联 枚举 宏
const 常量 程序运行时在常量表中,系统为它分配内存,在堆栈分配了空间:const常量有数据类型:语句末有分号:有类型检查:可以限制范围 //将所有不希望改变的变量加const修饰 const ...
- ActiveMQ queue和topic,持久订阅和非持久订阅
消息的 destination 分为 queue 和 topic,而消费者称为 subscriber(订阅者).queue 中的消息只会发送给一个订阅者,而 topic 的消息,会发送给每一个订阅者. ...
- 思科恶意加密TLS流检测论文记录——由于样本不均衡,其实做得并不好,神马99.9的准确率都是浮云啊,之所以思科使用DNS和http一个重要假设是DGA和HTTP C&C(正常http会有图片等)。一开始思科使用的逻辑回归,后面17年文章是随机森林。
论文记录:Identifying Encrypted Malware Traffic with Contextual Flow Data from:https://songcoming.github. ...
- java反序列化漏洞原理研习
零.Java反序列化漏洞 java的安全问题首屈一指的就是反序列化漏洞,可以执行命令啊,甚至直接getshell,所以趁着这个假期好好研究一下java的反序列化漏洞.另外呢,组里多位大佬对反序列化漏洞 ...
- ID基本操作(新建文档,页面编码)5.8
“文件”“新建”“文档”选择页数,页面大小.页面方向,“边距和分栏”设置上下左右的边距,栏数,如三栏 还可以改变分栏距离·改变排版方向,如图,垂直 单击“页面”可以查看我们的页面情况 超过两页会可以看 ...