Python基础2 字符编码和逻辑运算符
字符编码
为什么要编码
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理
AscII码 :标准ASCII码是采用7位二进制码来编码的,最高为0,没有0000 0000,所以就是2**7-1=127个字符 , 当用1个字节(8位二进制码)来表示ASCII码时,就在最高位添加1个0。1个字节表示一个英文字母。扩充的ASCII码最高位为1,相应的十进制为1~255。
一个英文字母占一个字节
8位(bit)==一个字节(byte)
1024byte=1KB
1024kb==1MB
1024MB=1GB
1024GB==1TB
Unicode:当时为了解决ASCII全球化的问题,就出现了Unicode,Unicode规定一个中文用4个字节表示,一个英文用2个字节表示。python3用四个字节来表示一个字符包含英语字母和汉字。
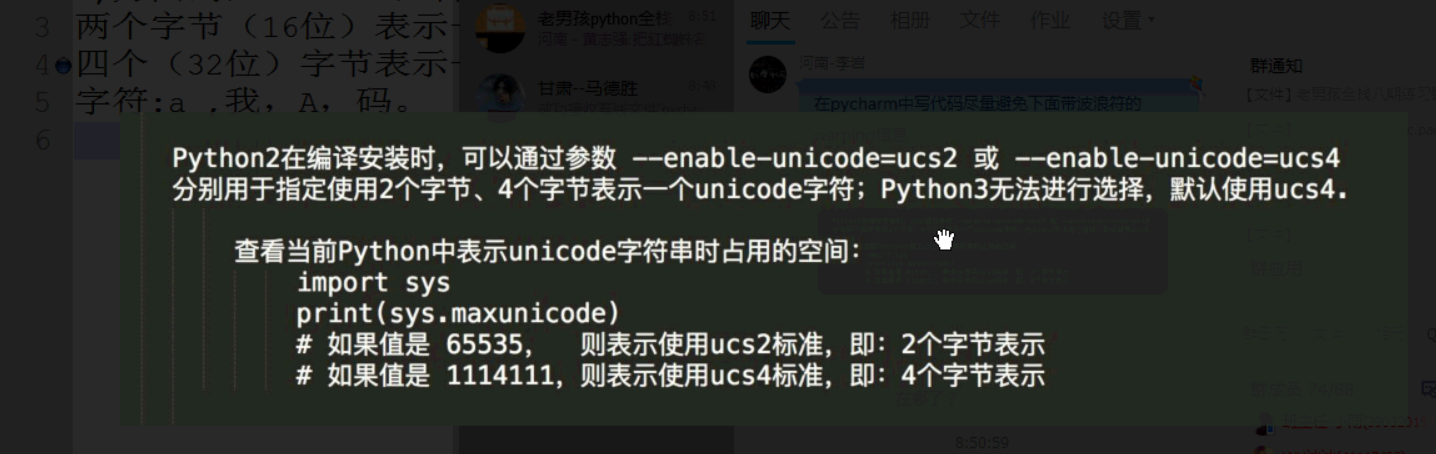
utf-8:其实就是Unicode的升级版,规定英文用1个字节表示,汉字用3个字节表示。
GBK:英文占用一个字节,汉字占用两个字节。
字符编码重点
关于字符编码困扰我好久了,今天我终于弄明白了,
编码(encode):将unicode编码的str转化为其他编码bytes类型的过程
解码:将其他编码的bytes类型转换为unicode编码的str字符串的过程
你要把gbk编码的字符串转换为utf的字符串必须这么办?
s = "你好"
print(s.encode("gbk").decode("gbk").encode("utf-8"))
结果:
b'\xe4\xbd\xa0\xe5\xa5\xbd'
问题一为什么要字符编码?
因为机器语言只能识别01010101,所以你编写的任何东西最后都要转化为bytes的类型。才能够让机器识别运行,bytes和二进制编码可以直接转换
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分
文本在内存中是用Unicode编码方式编码而存储的.其表现形式是str类型,这里很重要,你在解释器中看到的所有的变量函数等都是unicode在解释器中的表现形式,它在内存中就是unicode的字节码
import json
s='中国'
t=json.dumps(s)
print(t)
结果:
#在内存中就是以这种格式存在的
"\u4e2d\u56fd" #\u+16进制
文本在硬盘中和网络传输中是以(utf-8(python3默认),gbk,gb2312)编码方式编码成字节串而保存在硬盘中或网络传输的.这是因为这几种方式编码占用内存小.
s='中国'
t=s.encode()#默认utf-8
print(t)
结果:
b'\xe4\xb8\xad\xe5\x9b\xbd'
字符编码的补充版本:
新添加一个数据类型:
bytes 类型其表现形式为 s= b"alex" 内部储存是以(UTF-8,GBK,GB2312)编码方式编码的,Bytes 对象是由单个字节作为基本元素(8位,取值范围 0-255)组成的序列,为不可变对象。
str类型 其表现形式为s="alex" 内部存储是以Unicode编码方式编码的。
汉字如果在python2中显示要注释#-*-coding:utf-8-*-,python 2 中默认编码方式为ASCII,python3中默认为utf-8
encode: 方法以 encoding 指定的编码格式编码字符串(用unicode编码)。把字符串编码成bytes类型(utf-8),编码其实就是加密的意思 返回bytes
decode: 以encdoing指定的编码格式解码,解码为对应的字符串
内存中字符串是以Unicode的编码方式,占用内存大,但是可以兼容更多的编码方式
硬盘中字符串是以utf-8的编码方式编码的,
关于字符编码我又想了很长时间,得到了一些新的体会,继续补充说明。
a='你好'
a_b=a.encode('utf-8')
print(a_b) #得到a的二进制形式
for i in a_b: #这步的主要作用是把16进制转换为十进制
print(i)
for i in a_b:
print(bin(i)) #这步主要的作用是把十进制转化为二进制
结果:
b'\xe4\xbd\xa0\xe5\xa5\xbd' #这里a的二进制数据类是用十六进制数字表示的,因为这样看起来比较清晰,其中\xe4代表1个字节,a总共有6个字节,这也印证了在uft-8中每个汉字用3个字节表示
228 #原来十六进制中的xe4就是十进制中的228
189
160
229
165
189
0b11100100 #这就是为什么a的二进制数据类型不用二进制表示的原因,这样太乱了,完全懵逼
0b10111101
0b10100000
0b11100101
0b10100101
0b10111101
bin(number):一个整数转换为一个二进制字符串。注意这个二进制是str类型的并不是bytes类型。
范例:
b=bin(100)
print(b,type(b))
结果:
0b1100100 <class 'str'>
范例
s="你好"
b=bytes(s,encoding="gbk")
print(b)
print(s.encode("utf-8")) #告诉python解释器你要把这个字符串汉字以什么方式编码,如果你要以utf-8我就3个字节(24位二进制)来表示每个汉字,如果你是要以GBK方式编码来编码字符,我就用2个字节(16位二进制来表示每个汉字)
结果:
b'\xc4\xe3\xba\xc3' #印证了GBK2个字节表示一个汉字
b'\xe4\xbd\xa0\xe5\xa5\xbd'
bytes():将字符串str类型转换成bytes类型,和字符串中的encode一样。
范例
s="你好"
b=bytes(s,encoding="gbk")
print(b)
print(s.encode("utf-8"))
结果:
b'\xc4\xe3\xba\xc3'
b'\xe4\xbd\xa0\xe5\xa5\xbd'
python2和python3编码区别
总结一下:
在python3中 文件默认编码方式是utf-8,字符串默认编码方式是unicode,以utf-8和gbk编码的代码加载到内存中会自动转化为unicode编码,window默认编码方式是gbk,unicode可以和gbk之间互相转化,这就是为什么你可以在显示屏中看到正常的字符了
在python 2中文件的默认编码方式是ascii,字符串默认编码方式也是ascii,但是ascii和unicode编码并不能互相转化,所以我们在文件头声明了utf-8,文件默认编码也会变成utf-8,这样中文也就能够在window的显示瓶中显示了.
默认编码改成unicode的话是不现实的, 因为很多软件就是基于之前的默认编码ASCII开发的,编码一换,那些软件的编码就都乱了。所以Python 2
就直接 搞了一个新的字符类型,就叫unicode类型,比如你想让你的中文在全球所有电脑上正常显示,在内存里就得把字符串存成unicode类型。

>>> s = "路飞"
>>> s
'\xe8\xb7\xaf\xe9\xa3\x9e'
>>> s2 = s.decode("utf-8")
>>> s2
u'\u8def\u98de'
>>> type(s2)
<type 'unicode'>
比较运算符和逻辑运算符
比较运算符的级别比逻辑运算符高。
逻辑运算符有not,or, and.
这几个逻辑运算符的运算优先级为:()>not>and>or
同等优先级从左到右开始运算
print(7>4==4) #the same as 7>4 and 4==4
True #其实这个表达式有多个隐形的式子组成。
例如:
A=(1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8)
print(a)
结果:
False
int与bool之间的转换:除了0,都是True
A=int(True)
B=int(False) print(a,b)
结果:
1,0
print(bool(1))
print(bool(3))
print(bool(0))
结果:
True
True
False
bool和str之间的转换:bool()非空字符都是true,空格也是True,空字符为False
例子
s="sdfa"
s1="a"
s2=""
s3=" "
结果:
s True
s1 True
s2 False
s3 True
例子:
print(str(2>1))
结果:
True
例子:
name=""
if name:
print("输入正确")
else:
print("请输入内容")
结果:
请输入内容
此题关键空字符串就是false,接着就运行到了else。注意“”表示的是空字符串,而不是空格。空格就是True。
面试题:
1. print( x or y) ,如果bool(x)为True,则结果为x。否则结果为Y。
例题:
print(3 or 5)
print(0 or 8)
print(-1or 0)
结果为:
3
8
-1
2. print(X and y),如果bool(x)为True,则结果为y,如果bool(x)为False,则结果为X。
例子:
print(3 and 5)
print(0 and 8)
print(-1 and 0)
结果为:
5
0
0
例子:
print(3 or 4 or 0 and 1 or 2)
结果为:
3
in 和 not in 的运用:
例子
sl="abcdefg"
print("a"in sl)
print("ad" in sl) #"ad" 作为一个整体相当于一个元素,而不是像这样"a""b"拆开。
结果:
True
False
题目要求:评论的内容不能有敏感词如“习大大”,“国民党”,“蒋介石”
答案:
comment=input("请输入评论")
if ("习大大"in comment )or ("国民党" in comment )or ("蒋介石"in comment):
print("评论中包含敏感词")
else:
print("评论成功")
稍微高级的解法:
list_1=["习大大","蒋介石","国民党"]
conment=input("请输入内容")
for i in list_1:
if i in conment:
print("涉及非法字符")
break
else:
print(conment) #不知道是不是新方法:for else 方法
注意:此题的关键在于敏感词要in 评论而不是commet in 敏感词。
Python基础2 字符编码和逻辑运算符的更多相关文章
- python基础_字符编码
字符编码的历史 阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII 阶段二:为了满足中文,中国人定制了GBK 阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的 ...
- python 基础之字符编码和文件处理
一.字符编码 (1)计算机基础知识 (2)python 解释器执行py文件的原理 <1>python 解释器启动 <2>python解释器相当于一个文本编辑器,打开txt.py ...
- python基础4 ----字符编码
python基础---字符编码 一.了解字符编码 1. 文本编辑器存取文件的原理(nodepad++,pycharm,word) 打开编辑器就打开了启动了一个进程,是在内存中的,所以在编辑器编写的内容 ...
- 第二篇.2、python基础之字符编码
一 了解字符编码的知识储备 一 计算机基础知识 二 文本编辑器存取文件的原理(nodepad++,pycharm,word) #1.打开编辑器就打开了启动了一个进程,是在内存中的,所以,用编辑器编写的 ...
- 第1章 Python基础之字符编码
阅读目录 一.什么是字符编码 二.字符编码分类 三.字符编码转换关系 3.1 程序运行原理 3.2 终极揭秘 3.3 补充 总结 回到顶部 一.什么是字符编码 计算机要想工作必须通电,也就是说'电'驱 ...
- Python基础之字符编码
前言 字符编码非常容易出问题,我们要牢记几句话: 1.用什么编码保存的,就要用什么编码打开 2.程序的执行,是先将文件读入内存中 3.unicode是父编码,只能encode解码成其他编码格式 utf ...
- (Python基础)字符编码与转码
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧 ...
- Python全栈开发之路 【第三篇】:Python基础之字符编码和文件操作
本节内容 一.三元运算 三元运算又称三目运算,是对简单的条件语句的简写,如: 简单条件语句: if 条件成立: val = 1 else: val = 2 改成三元运算: val = 1 if 条件成 ...
- 第一章:python基础语法| 字符编码| 条件语句...
1.编程语言介绍 编程就是写代码,让计算机帮你做事情.计算机底层是电路,只认识二进制0和1.机器语言&汇编语言语言进化历史:机器.汇编.高级.机器语言只接受二进制代码:汇编语言是采用英文缩写的 ...
随机推荐
- 51nod-1181-两次筛法
1181 质数中的质数(质数筛法) 题目来源: Sgu 基准时间限制:1 秒 空间限制:131072 KB 分值: 0 难度:基础题 收藏 关注 如果一个质数,在质数列表中的编号也是质数,那么就 ...
- Leetcode 1022. 可被 K 整除的最小整数
1022. 可被 K 整除的最小整数 显示英文描述 我的提交返回竞赛 用户通过次数74 用户尝试次数262 通过次数75 提交次数1115 题目难度Medium 给定正整数 K,你需要找出可以被 ...
- 数据结构与算法之PHP查找算法(顺序查找)
对于查找数据来说,最简单的方法就是从列表的第一个元素开始对列表元素逐个进行判断,直到找到了想要的结果,或者直到列表结尾也没有找到,这种方法称为顺序查找. 一.基本写法 顺序查找的实现很简单.只要从列表 ...
- rexec/rlogin/rsh介绍
服务 是否需要密码 是否明文 功能 端口 rexec 是 是 远程执行命令 512 rlogin 是 是 远程登录得到shell 513 rsh 是 是 可远程执行命令,也可远程登录得到shell 5 ...
- 运行B/s项目时,出现尝试访问类型与数组不兼容元素问题?
1.问题描述 运行B/s项目时,浏览器出现应用程序中服务器错误(尝试访问类型与数组不兼容的元素) 2.问题原因 本人是项目引用的dll版本不一致问题,引用的System.Web.Mvc版本是4.0.0 ...
- MAVEN ECLIPSE JAR工程
在eclipse 空白处点击鼠标右键选择新建 project 选择maven project: 选择Create a simple project Group ID: Artifact ID:创建项目 ...
- 尚学堂java 参考答案 第八章
一.选择题 1.BD 解析:B:Integer是对象,所以默认的应该是null对象.D使用的是自动装箱 2.A 解析:String类的对象是final型,是不能修改的,concat()方法是生成一个新 ...
- 分布式锁与实现(一)基于Redis实现
目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题.分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency).可用性( ...
- bzoj1798
题解: 同洛谷2023 代码: #include<bits/stdc++.h> using namespace std; typedef long long ll; ; ll p,v,su ...
- day06 小数据池,再谈编码
今日所学 一. 小数据池 二. is 和==的区别 三. 编码的问题 一.小数据池的作用 用来缓存数据 可以作用的数据类型: 整数(int), 字符串(str), 布尔值(bool). 什么是块 ...