scrapy 下载图片 from cuiqingcai
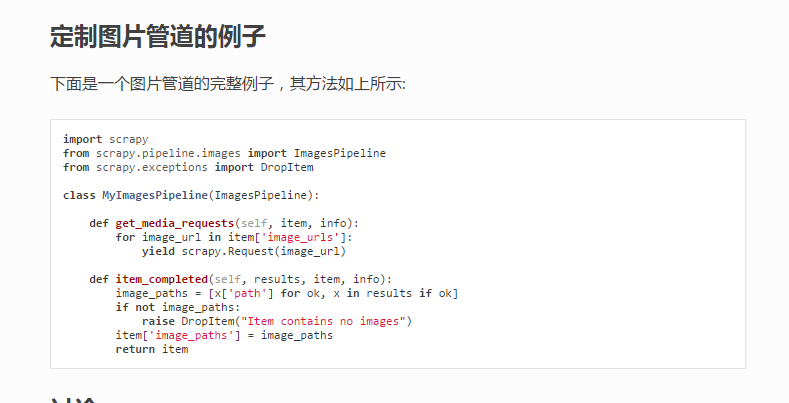
import scrapy class MzituScrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
image_urls = scrapy.Field()
url = scrapy.Field()
pass
官方的:
https://doc.scrapy.org/en/latest/topics/media-pipeline.html?highlight=item_complete#scrapy.pipelines.images.ImagesPipeline.item_completed
https://doc.scrapy.org/en/latest/topics/media-pipeline.html?highlight=item_complete
没有分类,很难看, 再重写一下ImagesPipeline中的file_path方法!
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy import Request
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
import re class MzituScrapyPipeline(ImagesPipeline): def file_path(self, request, response=None, info=None):
"""
:param request: 每一个图片下载管道请求
:param response:
:param info:
:param strip :清洗Windows系统的文件夹非法字符,避免无法创建目录
:return: 每套图的分类目录
"""
item = request.meta['item']
folder = item['name']
folder_strip = strip(folder)
image_guid = request.url.split('/')[-1]
filename = u'full/{0}/{1}'.format(folder_strip, image_guid)
return filename def get_media_requests(self, item, info):
"""
:param item: spider.py中返回的item
:param info:
:return:
"""
for img_url in item['image_urls']:
referer = item['url']
yield Request(img_url, meta={'item': item,
'referer': referer}) def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
return item # def process_item(self, item, spider):
# return item def strip(path):
"""
:param path: 需要清洗的文件夹名字
:return: 清洗掉Windows系统非法文件夹名字的字符串
"""
path = re.sub(r'[?\\*|“<>:/]', '', str(path))
return path if __name__ == "__main__":
a = '我是一个?\*|“<>:/错误的字符串'
print(strip(a))
写一个中间件来处理图片下载的防盗链:
class MeiZiTu(object):
def process_request(self, request, spider):
'''设置headers和切换请求头
:param request: 请求体
:param spider: spider对象
:return: None
'''
referer = request.meta.get('referer', None)
if referer:
request.headers['referer'] = referer
最后一步设置ImagesPipeline的存储目录!
在settings.py中写入:
IMAGES_STORE = 'F:\mzitu\\'
在settings.py中写入以下配置。
# 30 days of delay for images expiration
DOWNLOADER_MIDDLEWARES = {
scrapy 下载图片 from cuiqingcai的更多相关文章
- scrapy下载图片到自己的目录,创建缩略图,存储入库
环境和工具:python2.7,scrapy 实验网站:http://www.27270.com/tag/333.html 爬去所有兔女郎图片,下面的推荐需要过滤 逻辑:分析网站信息,下载图片和入库 ...
- Scrapy下载图片及自定义分类下载路径
配置下载图片的流程如下 在items中定义两个属性,image_urls 和images .image_urls是用来存储需要下载的图片url链接,列表类型: 当文件下载完成后会把相关下载信息存入im ...
- 利用scrapy下载图片保存到本地
1.先声明一下,起始位置已经是将所有的图片链接都能到pipelines.py中 2.创建一个类,继承于ImagesPipeline,因此也就需要导入ImagesPipeline from scrapy ...
- [转]解决scrapy下载图片时相对路径转绝对路径的问题
专注自:http://blog.csdn.net/hjy_six/article/details/6862648 这段时间一直在研究利用scrapy抓取图片的问题,我发觉,用官网的http://doc ...
- Scrapy 下载图片时 ModuleNotFoundError: No module named'PIL'
使用scrapy的下载模块需要PIL(python图像处理模块)的支持,使用pip安装即可
- Scrapy 下载图片
参考 : https://www.jianshu.com/p/6c8d2730d088 https://docs.scrapy.org/en/latest/topics/item-pipeline.h ...
- scrapy下载图片报[scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt:错误
本文转自:http://blog.csdn.net/zzk1995/article/details/51628205 先说结论,关闭scrapy自带的ROBOTSTXT_OBEY功能,在setting ...
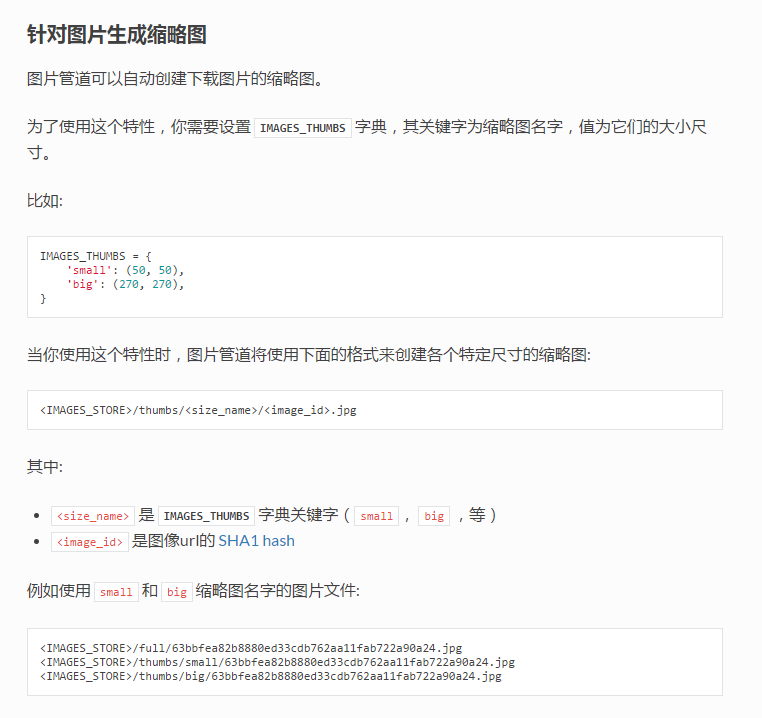
- Day3-scrapy爬虫下载图片自定义名称
学习Scrapy过程中发现用Scrapy下载图片时,总是以他们的URL的SHA1 hash值为文件名,如: 图片URL:http://www.example.com/image.jpg 它的SHA1 ...
- 用Scrapy爬虫下载图片(豆瓣电影图片)
用Scrapy爬虫的安装和入门教程,这里有,这篇链接的博客也是我这篇博客的基础. 其实我完全可以直接在上面那篇博客中的代码中直接加入我要下载图片的部分代码的,但是由于上述博客中的代码已运行,已爬到快九 ...
随机推荐
- [dj]django常用设置
关于django版本说明: Django 1.11.x 支持 Python 2.7, 3.4, 3.5 和 3.6(长期支持版本 LTS) 最后一个支持 Python 2.7 的版本 Django 2 ...
- 安装OpenSSL中出现的问题及解决
1.报错:install-record.txt --single-version-externally-managed --compile" failed with error code 1 ...
- [LeetCode] 434. Number of Segments in a String_Easy
Count the number of segments in a string, where a segment is defined to be a contiguous sequence of ...
- 【产品案例】我是如何从零搭建起一款健身O2O产品的?
作者: Wander_Yang 我在年初参与到“SHAPE”这款健身产品的研发中,也算是第一次以产品经理的身份,从0开始负责一个产品的建立. 产品是一款O2O的智能健身连锁店,目前产品已经上线8个月, ...
- canvas原生js写的贪吃蛇
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Selenium基础知识(五)多窗口切换
说到多窗口切换必须想到driver.switch_to.window()方法 driver.switch_to.window() 实现在不同窗口之间切换 driver.current_window_h ...
- python时间和日期
一.time 和 calendar 模块可以用于格式化日期和时间 import time; # 引入time模块 ticks = time.time() print "当前时间戳为:&quo ...
- c# webapi 跳转
c# webapi 跳转 public HttpResponseMessage Post() { // ... do the job // now redirect Http ...
- 关于hdfs 和hive的数据迁移
1. 迁移hdfs,使用hadoop 命令 hadoop distcp -pugp hdfs://localhost:9000/ hdfs://localhost:9000/ 此处示例仅作说明用 2 ...
- SV通过DPI调用C
Verilog与C之间进行程序交互,PLI(Programming Language Interface)经过了TF,ACC,VPI等模式. 使用PLI可以生成延时计算器,来连接和同步多个仿真器,并可 ...