企业安全建设之搭建开源SIEM平台
https://www.freebuf.com/special/127172.html
https://www.freebuf.com/special/127264.html
https://www.freebuf.com/articles/network/127988.html
前言
SIEM(security information and event management),顾名思义就是针对安全信息和事件的管理系统,针对大多数企业是不便宜的安全系统,本文结合作者的经验介绍下如何使用开源软件搭建企业的SIEM系统,数据深度分析在下篇。
SIEM的发展
对比Gartner2009年和2016年的全球SIEM厂商排名,可以清楚看出,基于大数据架构的厂商Splunk迅速崛起,传统四强依托完整的安全产品线和成熟市场渠道,依然占据领导者象限,其他较小的厂商逐渐离开领导者象限。最重要的存储架构也由盘柜(可选)+商业数据库逐渐转变为可横向扩展的大数据架构,支持云环境也成为趋势。
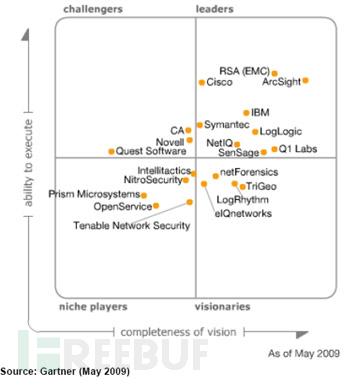
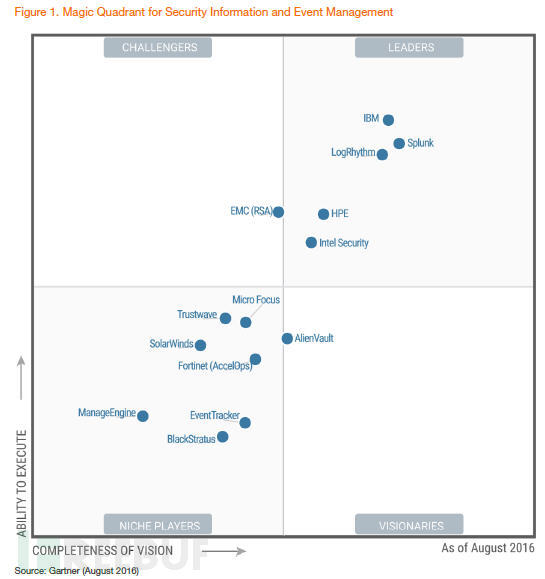
开源SIEM领域,比较典型的就是ossim和Opensoc,ossim存储架构是mysql,支持多种日志格式,包括鼎鼎大名的Snort、Nmap、 Nessus以及Ntop等,对于数据规模不大的情况是个不错的选择,新版界面很酷炫。
完整的SIEM至少会包括以下功能:
- 漏洞管理
- 资产发现
- 入侵检测
- 行为分析
- 日志存储、检索
- 报警管理
- 酷炫报表
其中最核心的我认为是入侵检测、行为分析和日志存储检索,本文重点集中讨论支撑上面三个功能的技术架构。
Opensoc简介
Opensoc是思科2014年在BroCon大会上公布的开源项目,但是没有真正开源其源代码,只是发布了其技术框架。我们参考了Opensoc发布的架构,结合公司实际落地了一套方案。Opensoc完全基于开源的大数据框架kafka、storm、spark和es等,天生具有强大的横向扩展能力,本文重点讲解的也是基于Opensoc的siem搭建。
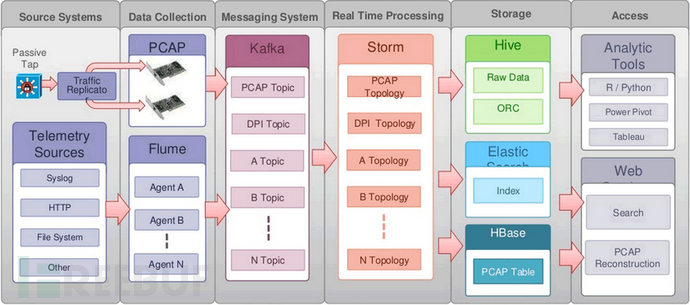
上图是Opensoc给出的框架,初次看非常费解,我们以数据存储与数据处理两个纬度来细化,以常见的linux服务器ssh登录日志搜集为例。
数据搜集纬度
数据搜集纬度需求是搜集原始数据,存储,提供用户交互式检索的UI接口,典型场景就是出现安全事件后,通过检索日志回溯攻击行为,定损。
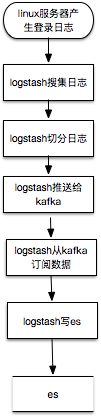
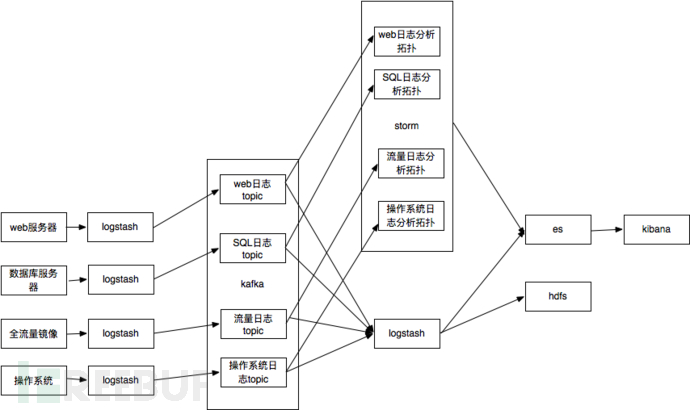
logtash其实可以直接把数据写es,但是考虑到storm也要数据处理,所以把数据切分放到logstash,切分后的数据发送kafka,提供给storm处理和logstash写入es。数据检索可以直接使用kibana,非常方便。数据切分也可以在storm里面完成。这个就是大名鼎鼎的ELK架构。es比较适合存储较短时间的热数据的实时检索查询,对于需要长期存储,并且希望使用hadoop或者spark进行大时间跨度的离线分析时,还需要存储到hdfs上,所以比较常见的数据流程图为:
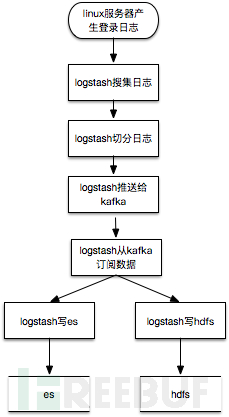
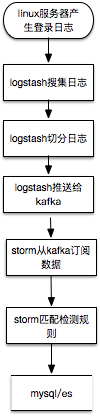
数据处理纬度
这里以数据实时流式处理为例,storm从kafka中订阅切分过的ssh登录日志,匹配检测规则,检测结果的写入mysql或者es。
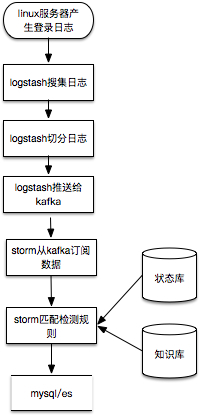
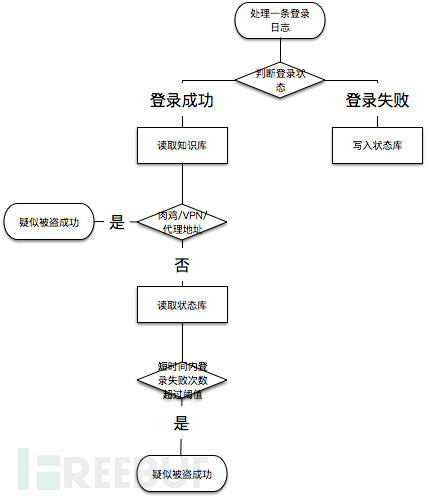
在这个例子中,孤立看一条登录日志难以识别安全问题,最多识别非跳板机登录,真正运行还需要参考知识库中的常见登录IP、时间、IP情报等以及临时存储处理状态的状态库中最近该IP的登录成功与失败情况。比较接近实际运行情况的流程如下:
具体判断逻辑举例如下,实际中使用大量代理IP同时暴力破解,打一枪换一个地方那种无法覆盖,这里只是个举例:
扩展数据源
生产环境中,处理安全事件,分析入侵行为,只有ssh登录日志肯定是不够,我们需要尽可能多的搜集数据源,以下作为参考:
- linux/window系统安全日志/操作日志
- web服务器访问日志
- 数据库SQL日志
- 网络流量日志
简化后的系统架构如下,报警也存es主要是查看报警也可以通过kibana,人力不足界面都不用开发了:
storm拓扑
storm拓扑支持python开发,以处理SQL日志为例子:
假设SQL日志的格式
"Feb 16 06:32:50 " "127.0.0.1" "root@localhost" "select * from user where id=1"一般storm的拓扑结构
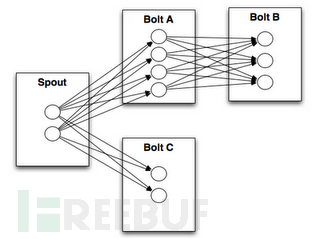
简化后spout是通用的从kafka读取数据的,就一个bolt处理SQL日志,匹配规则,命中策略即输出”alert”:”原始SQL日志”
核心bolt代码doSQLCheckBolt伪码
import storm
class doSQLCheckBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
sql = word[3]
if re.match(规则,sql):
storm.emit(["sqli",tup.values[0]])
doSQLCheckBolt().run()
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sqlLog", new kafkaSpout(), 10);
builder.setBolt("sqliAlert", new doSQLCheckBolt(), 3)
.shuffleGrouping("sqlLog");
拓扑提交示例
Config conf = new Config();
conf.setDebug(true);
conf.setNumWorkers(2);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("doSQL", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("doSQL");
cluster.shutdown();
logstash
在本文环节中,logstash的配置量甚至超过了storm的拓扑脚本开发量,下面讲下比较重点的几个点,切割日志与检索需求有关系,非常个性化,这里就不展开了。
从文件读取
input
file {
path => ["/var/log/*.log", "/var/log/message"]
type => "system"
start_position => "beginning"
}
}
从kafka中订阅
input {
kafka {
zk_connect => "localhost:2181"
group_id => "logstash"
topic_id => "test"
reset_beginning => false # boolean (optional), default: false
consumer_threads => 5 # number (optional), default: 1
decorate_events => true # boolean (optional), default: false
}
}
写kafka
output {
kafka {
broker_list => "localhost:9092"
topic_id => "test"
compression_codec => "snappy" # string (optional), one of ["none", "gzip", "snappy"], default: "none"
}
}
写hdfs
output {
hadoop_webhdfs {
workers => 2
server => "localhost:14000"
user => "flume"
path => "/user/flume/logstash/dt=%{+Y}-%{+M}-%{+d}/logstash-%{+H}.log"
flush_size => 500
compress => "snappy"
idle_flush_time => 10
retry_interval => 0.5
}
}
写es
output {
elasticsearch {
host => "localhost"
protocol => "http"
index => "logstash-%{type}-%{+YYYY.MM.dd}"
index_type => "%{type}"
workers => 5
template_overwrite => true
}
}
前言
SIEM(security information and event management),顾名思义就是针对安全信息和事件的管理系统,针对大多数企业是不便宜的安全系统,本文结合作者的经验介绍如何使用开源软件离线分析数据,使用攻击建模的方式识别攻击行为。
回顾系统架构
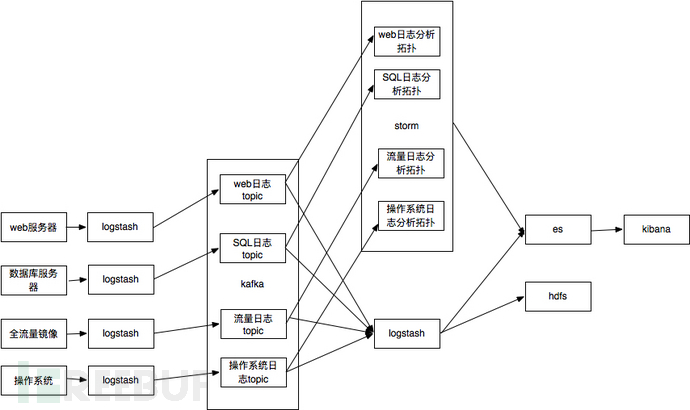
以数据库为例,通过logstash搜集mysql的查询日志,近实时备份到hdfs集群上,通过hadoop脚本离线分析攻击行为。
数据库日志搜集
常见的数据日志搜集方式有三种:
镜像方式
大多数数据库审计产品都支持这种模式,通过分析数据库流量,解码数据库协议,识别SQL预计,抽取出SQL日志
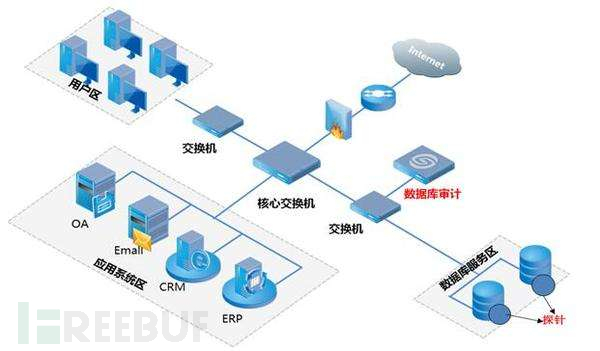
代理方式
比较典型的就是db-proxy方式,目前百度、搜狐、美团、京东等都有相关开源产品,前端通过db-proxy访问后端的真实数据库服务器。SQL日志可以直接在db-proxy上搜集。
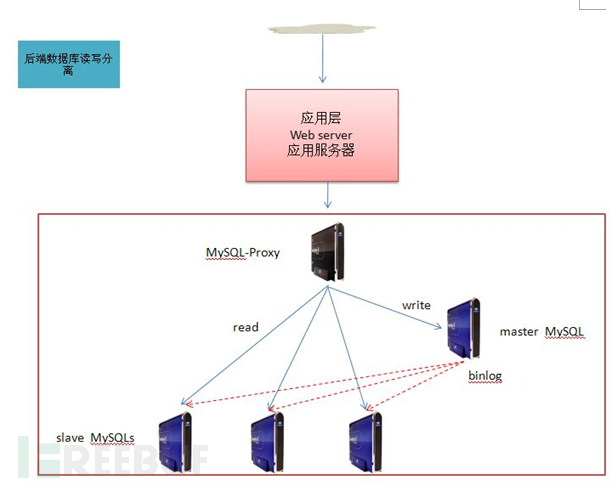
客户端方式
通过在数据库服务器安装客户端搜集SQL日志,比较典型的方式就是通过logstash来搜集,本文以客户端方式进行讲解,其余方式本质上也是类似的。
logstash配置
安装
下载logstash https://www.elastic.co/downloads/logstash 目前最新版本5.2.1版
开启mysql查询日志
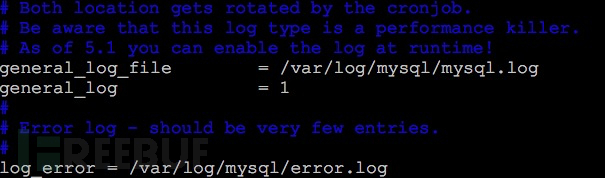
mysql查询日志
配置logstash
input {
file {
type => "mysql_sql_file"
path => "/var/log/mysql/mysql.log"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
output {
kafka { broker_list => "localhost:9092" topic_id => "test" compression_codec => "snappy" # string (optional), one of ["none", "gzip", "snappy"], default: "none" }
}
运行logstash
bin/logstash -f mysql.conf日志举例
2017-02-16T23:29:00.813Z localhost 170216 19:10:15 37 Connect
debian-sys-maint@localhost on
2017-02-16T23:29:00.813Z localhost 37 Quit
2017-02-16T23:29:00.813Z localhost 38 Connect debian-sys-maint@localhost on
2017-02-16T23:29:00.813Z localhost 38 Query SHOW VARIABLES LIKE 'pid_file'
切词
最简化操作是不用进行切词,如果喜欢自动切分出数据库名,时间等字段,请参考:
grok语法
https://github.com/elastic/logstash/blob/v1.4.2/patterns/grok-patterns
grok语法调试
http://grokdebug.herokuapp.com/
常见攻击特征
以常见的wavsep搭建靶场环境,请参考我的另外一篇文章《基于WAVSEP的靶场搭建指南》
使用SQL扫描链接

分析攻击特征,下列列举两个,更多攻击特征请大家自行总结
特征一
2017-02-16T23:29:00.993Z localhost 170216 19:19:12 46 Query SELECT username, password FROM users WHERE username='textvalue' UNION ALL SELECT NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL#' AND password='textvalue2'使用联合查询枚举数据时会产生大量的NULL字段
特征二、三
枚举数据库结构时会使用INFORMATION_SCHEMA,另外个别扫描器会使用GROUP BY x)a)
2017-02-16T23:29:00.998Z localhost 46 Query SELECT username, password FROM users WHERE username='textvalue' AND (SELECT 7473 FROM(SELECT COUNT(*),CONCAT(0x7171716271,(SELECT (CASE WHEN (8199= 8199) THEN 1 ELSE 0 END)),0x717a627871,FLOOR(RAND(0)*2))x FROM INFORMATION_SCHEMA.PLUGINS GROUP BY x)a)-- LFpQ' AND password='textvalue2'hadoop离线处理
hadoop是基于map,reduce模型
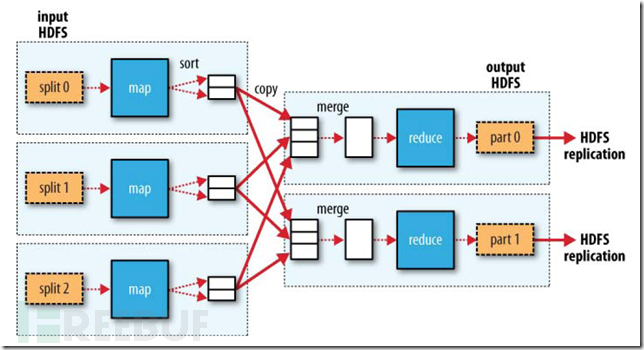
简化理解就是:
cat data.txt | ./map | ./reduce最简化期间,我们可以只开发map程序,在map中逐行处理日志数据,匹配攻击行为。
以perl脚本开发,python类似
#!/usr/bin/perl -w
my $rule="(null,){3,}|information_schema|GROUP BY x\\)a\\)";
my $line="";
while($line=<>)
{
if( $line=~/$rule/i )
{
printf($line);
}
}
在hadoop下运行即可。
生产环境
生产环境中的规则会比这复杂很多,需要你不断补充,这里只是举例;
单纯只编写map会有大量的重复报警,需要开发reduce用于聚合;
应急响应时需要知道SQL注入的是那个库,使用的是哪个账户,这个需要在logstash切割字段时补充;
应急响应时最好可以知道SQL注入对应的链接,这个需要将web的accesslog与SQL日志关联分析,比较成熟的方案是基于机器学习,学习出基于时间的关联矩阵;
客户端直接搜集SQL数据要求mysql也开启查询日志,这个对服务器性能有较大影响,我知道的大型公司以db-prxoy方式接入为主,建议可以在db-proxy上搜集;
基于规则识别SQL注入存在瓶颈,虽然相对web日志层面以及流量层面有一定进步,SQL语义成为必然之路。
后继
前言
SIEM(security information and event management),顾名思义就是针对安全信息和事件的管理系统,针对大多数企业是不便宜的安全系统,本文结合作者的经验介绍如何使用开源软件离线分析数据,使用算法挖掘未知攻击行为。上集传送门
回顾系统架构
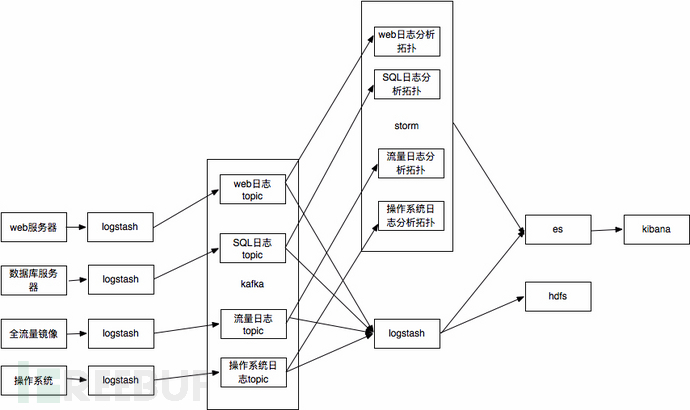
以WEB服务器日志为例,通过logstash搜集WEB服务器的查询日志,近实时备份到hdfs集群上,通过hadoop脚本离线分析攻击行为。
自定义日志格式
开启httpd自定义日志格式,记录User-Agen以及Referer
<IfModule logio_module>
# You need to enable mod_logio.c to use %I and %O
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %I %O" combinedio
</IfModule>
CustomLog "logs/access_log" combined
日志举例
180.76.152.166 - - [26/Feb/2017:13:12:37 +0800] "GET /wordpress/ HTTP/1.1" 200 17443 "http://180.76.190.79:80/" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.21"
180.76.152.166 - - [26/Feb/2017:13:12:37 +0800] "GET /wordpress/wp-json/ HTTP/1.1" 200 51789 "-" "print `env`"
180.76.152.166
- - [26/Feb/2017:13:12:38 +0800] "GET
/wordpress/wp-admin/load-styles.php?c=0&dir=ltr&load[]=dashicons,buttons,forms,l10n,login&ver=Li4vLi4vLi4vLi4vLi4vLi4vLi4vLi4vLi4vLi4vZXRjL3Bhc3N3ZAAucG5n
HTTP/1.1" 200 35841 "http://180.76.190.79:80/" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.21"
180.76.152.166 - - [26/Feb/2017:13:12:38 +0800] "GET /wordpress/ HTTP/1.1" 200 17442 "http://180.76.190.79:80/" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.21"
测试环境
在wordpress目录下添加测试代码1.php,内容为phpinfo
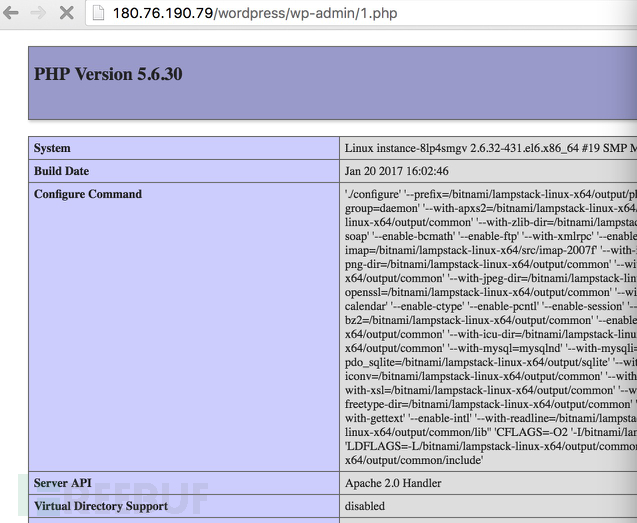
针对1.php的访问日志
[root@instance-8lp4smgv logs]# cat access_log | grep 'wp-admin/1.php'
125.33.206.140
- - [26/Feb/2017:13:09:47 +0800] "GET /wordpress/wp-admin/1.php
HTTP/1.1" 200 17 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102
Safari/537.36"
125.33.206.140 - - [26/Feb/2017:13:11:19 +0800]
"GET /wordpress/wp-admin/1.php HTTP/1.1" 200 17 "-" "Mozilla/5.0
(Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like
Gecko) Chrome/50.0.2661.102 Safari/537.36"
125.33.206.140 - -
[26/Feb/2017:13:13:44 +0800] "GET /wordpress/wp-admin/1.php HTTP/1.1"
200 17 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102
Safari/537.36"
127.0.0.1 - - [26/Feb/2017:13:14:19 +0800] "GET
/wordpress/wp-admin/1.php HTTP/1.1" 200 17 "-" "curl/7.19.7
(x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.14.0.0 zlib/1.2.3
libidn/1.18 libssh2/1.4.2"
127.0.0.1 - - [26/Feb/2017:13:16:04
+0800] "GET /wordpress/wp-admin/1.php HTTP/1.1" 200 107519 "-"
"curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.14.0.0
zlib/1.2.3 libidn/1.18 libssh2/1.4.2"
125.33.206.140 - -
[26/Feb/2017:13:16:12 +0800] "GET /wordpress/wp-admin/1.php HTTP/1.1"
200 27499 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102
Safari/537.36"
[root@instance-8lp4smgv logs]#
hadoop离线处理
hadoop是基于map,reduce模型
map脚本
localhost:work maidou$ cat mapper-graph.pl
#!/usr/bin/perl -w
#180.76.152.166 - - [26/Feb/2017:13:12:37 +0800] "GET /wordpress/ HTTP/1.1" 200 17443 "http://180.76.190.79:80/" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.21"
my $line="";
while($line=<>)
{
if( $line=~/"GET (\S+) HTTP\/1.[01]" 2\d+ \d+ "(\S+)"/ )
{
my $path=$1;
my $ref=$2;
if( $path=~/(\S+)\?(\S+)/ )
{
$path=$1;
}
if( $ref=~/(\S+)\?(\S+)/ )
{
$ref=$1;
}
if( ($ref=~/^http:\/\/180/)||( "-" eq $ref ) )
{
my $line=$ref."::".$path."\n";
#printf("$ref::$path\n");
print($line);
}
}
}
reducer脚本
localhost:work maidou$ cat reducer-graph.pl
#!/usr/bin/perl -w
my %result;
my $line="";
while($line=<>)
{
if( $line=~/(\S+)\:\:(\S+)/ )
{
unless( exists($result{$line}) )
{
$result{$line}=1;
}
}
}
foreach $key (sort keys %result)
{
if( $key=~/(\S+)\:\:(\S+)/ )
{
my $ref=$1;
my $path=$2;#这里是举例,过滤你关注的webshell文件后缀,常见的有php、jsp,白名单形式过滤存在漏报风险;也可以以黑名单形式过滤你忽略的文件类型
if( $path=~/(\.php)$/ )
{
my $output=$ref." -> ".$path."\n";
print($output);
}
}
}
生成结果示例为:
- -> http://180.76.190.79/wordpress/wp-admin/1.php
- -> http://180.76.190.79/wordpress/wp-admin/admin-ajax.php
- -> http://180.76.190.79/wordpress/wp-admin/customize.php
http://180.76.190.79/wordpress/ -> http://180.76.190.79/wordpress/wp-admin/edit-comments.php
http://180.76.190.79/wordpress/ -> http://180.76.190.79/wordpress/wp-admin/profile.php
http://180.76.190.79/wordpress/ -> http://180.76.190.79/wordpress/wp-login.php
http://180.76.190.79/wordpress/ -> http://180.76.190.79/wordpress/xmlrpc.php
图算法
讲生成数据导入图数据库neo4j,满足webshell特征的为:
入度出度均为0
入度出度均为1且自己指向自己
neo4j
neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中,因其嵌入式、高性能、轻量级等优势,越来越受到关注。
neo4j安装
https://neo4j.com/ 上下载安装包安装,默认配置即可
ne04j启动
以我的mac为例子,通过gui启动即可,默认密码为ne04j/ne04j,第一次登录会要求更改密码
GUI管理界面
python api库安装
sudo pip install neo4j-driver
下载JPype
https://pypi.python.org/pypi/JPype1
安装JPype
tar -zxvf JPype1-0.6.2.tar.gz
cd JPype1-0.6.2
sudo python setup.py install
将数据导入图数据库代码如下:
B0000000B60544:freebuf liu.yan$ cat load-graph.py
import re
from neo4j.v1 import GraphDatabase, basic_auth
nodes={}
index=1
driver = GraphDatabase.driver("bolt://localhost:7687",auth=basic_auth("neo4j","maidou"))
session = driver.session()
file_object = open('r-graph.txt', 'r')
try:
for line in file_object:
matchObj = re.match( r'(\S+) -> (\S+)', line, re.M|re.I)
if matchObj:
path = matchObj.group(1);
ref = matchObj.group(2);
if path in nodes.keys():
path_node = nodes[path]
else:
path_node = "Page%d" % index
nodes[path]=path_node
sql = "create (%s:Page {url:\"%s\" , id:\"%d\",in:0,out:0})" %(path_node,path,index)
index=index+1
session.run(sql)
#print sql
if ref in nodes.keys():
ref_node = nodes[ref]
else:
ref_node = "Page%d" % index
nodes[ref]=ref_node
sql = "create (%s:Page {url:\"%s\",id:\"%d\",in:0,out:0})" %(ref_node,ref,index)
index=index+1
session.run(sql)
#print sql
sql = "create (%s)-[:IN]->(%s)" %(path_node,ref_node)
session.run(sql)
#print sql
sql = "match (n:Page {url:\"%s\"}) SET n.out=n.out+1" % path
session.run(sql)
#print sql
sql = "match (n:Page {url:\"%s\"}) SET n.in=n.in+1" % ref
session.run(sql)
#print sql
finally:
file_object.close( )
session.close()
生成有向图如下
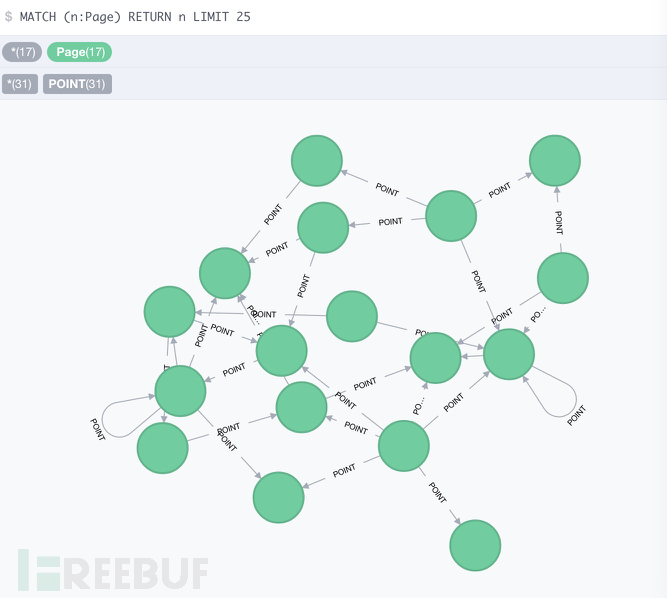
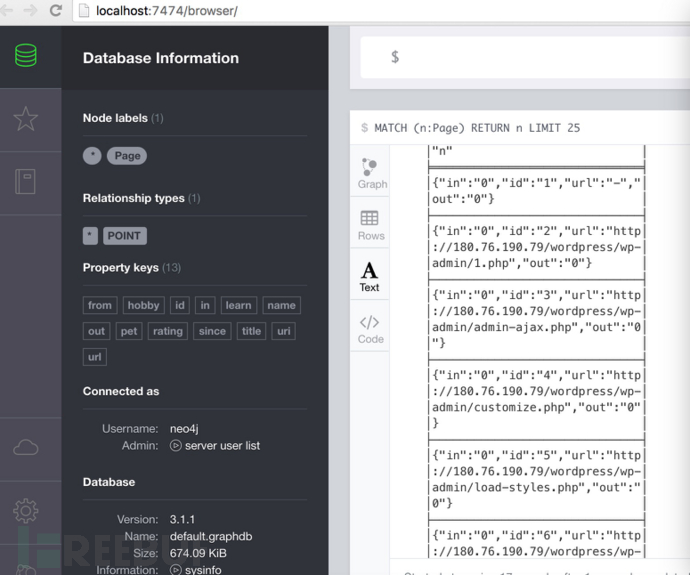
查询入度为1出度均为0的结点或者查询入度出度均为1且指向自己的结点,由于把ref为空的情况也识别为”-”结点,所以入度为1出度均为0。
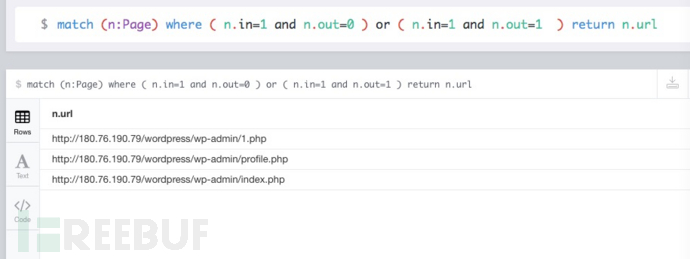
优化点
生产环境实际使用中,我们遇到误报分为以下几种:
主页,各种index页面(第一个误报就是这种)
phpmyadmin、zabbix等运维管理后台
hadoop、elk等开源软件的控制台
API接口
这些通过短期加白可以有效解决,比较麻烦的是扫描器对结果的影响(第二个误报就是这种),这部分需要通过扫描器指纹或者使用高大上的人机算法来去掉干扰。
后记
使用算法来挖掘未知攻击行为是目前非常流行的一个研究方向,本文只是介绍了其中比较好理解和实现的一种算法,该算法并非我首创,不少安全公司也都或多或少有过实践。篇幅有限,我将陆续在企业安全建设专题其他文章中由浅入深介绍其他算法。算法或者说机器学习本质是科学规律在大数据集集合上趋势体现,所以很难做到精准报警,目前阶段还是需要通过各种规则和模型来辅助,不过对于挖掘未知攻击行为确实是一支奇兵。
企业安全建设之搭建开源SIEM平台的更多相关文章
- 企业安全建设之搭建开源SIEM平台(上)
前言 SIEM(security information and event management),顾名思义就是针对安全信息和事件的管理系统,针对大多数企业是不便宜的安全系统,本文结合作者的经验介绍 ...
- Docker 搭建开源 CMDB平台 之 “OpsManage”
说明: 我一次build 完 所以images 包 有1G多 可分层build bash 环境一层 应用程序及启动脚本(shell.sh) 一层 步骤: 1 ...
- Docker 搭建开源 CMDB平台 “OpsManage” 之 Mariadb
整理了一下文档 今天来构建mariadb 主机还是 centos 172.16.0.200 构建第二个images 直接shell.sh 完成 #!/bin/bash echo " ...
- Docker 搭建开源 CMDB平台 “OpsManage” 之 Redis
整体结构如下图 先来在 172.16.0.200 安装docker-ce (新)或 docker-io(旧) 0: Docker-ce (新版本 Docker version 17. ...
- 【译文】用Spring Cloud和Docker搭建微服务平台
by Kenny Bastani Sunday, July 12, 2015 转自:http://www.kennybastani.com/2015/07/spring-cloud-docker-mi ...
- Spring Cloud和Docker搭建微服务平台
用Spring Cloud和Docker搭建微服务平台 This blog series will introduce you to some of the foundational concepts ...
- 高级PHP开发:利用PHPEMS搭建在线考试平台
今天给大家分享一个小技巧,就是利用PHP ems搭建在线考试平台:希望能给你给予帮助: 在给大家分享之前,这里推荐下我自己建的PHP开发-VIP资料出售平台 :638965404,不管你是小白还是大牛 ...
- 轻松搭建Windows8云平台开发环境
原文:轻松搭建Windows8云平台开发环境 Windows Store应用是基于Windows 8操作系统的新一代Windows应用程序,其开发平台以及运行模式和以往传统平台略有不同.为了帮助更多开 ...
- 开源视频平台:Kaltura
Kaltura是一个很优秀的开源视频平台.提供了视频的管理系统,视频的在线编辑系统等等一整套完整的系统,功能甚是强大. Kaltura不同于其他诸如Brightcove,Ooyala这样的网络视频平台 ...
随机推荐
- Web侦察工具HTTrack (爬取整站)
Web侦察工具HTTrack (爬取整站) HTTrack介绍 爬取整站的网页,用于离线浏览,减少与目标系统交互,HTTrack是一个免费的(GPL,自由软件)和易于使用的离线浏览器工具.它允许您从I ...
- Python3 卷积神经网络卷积层,池化层,全连接层前馈实现
# -*- coding: utf-8 -*- """ Created on Sun Mar 4 09:21:41 2018 @author: markli " ...
- 条件随机场之CRF++源码详解-开篇
介绍 最近在用条件随机场做切分标注相关的工作,系统学习了下条件随机场模型.能够理解推导过程,但还是比较抽象.因此想研究下模型实现的具体过程,比如:1) 状态特征和转移特征具体是什么以及如何构造 2)前 ...
- anaconda虚拟环境管理,从此Python版本不用愁
1 引言 在前几篇博文中介绍过virtualenv.virtualenvwrapper等几个虚拟环境管理工具,本篇要介绍的anaconda也有很强大的虚拟环境管理功能,甚至相比virtualenv.v ...
- linux下构建MysqlCluster集群,NDB搜索引擎
搭建管理节点 Ndb搜索引擎对于服务器的内存要求比较高,因为所有数据节点的数据,以及索引,事务等等都需要加载进内存中. 下载 mysql-cluster-gpl-7.6.8-linux-glibc2. ...
- vue 开发环境搭建,超级简单仅需3步。
1,打开 http://nodejs.cn/download/ 下载 nodejs,并安装. 2,成功以后,启动cmd命令行,输入npm install -g cnpm --registry=htt ...
- Python解释数学系列——分位数Quantile
跳转到我的博客 1. 分位数计算案例与Python代码 案例1 Ex1: Given a data = [6, 47, 49, 15, 42, 41, 7, 39, 43, 40, 36],求Q1, ...
- mongoDB进行分组操作
一.$group 进行分组 1.每个职位的雇员人数: db.getCollection('emp').aggregate( [ {'$group':{ ‘_id’:'$job', job_count: ...
- 跟着ZooKeeper学Java——CountDownLatch和Join的使用
在阅读ZooKeeper的源码时,看到这么一个片段,在单机模式启动的时候,会调用下面的方法,根据zoo.cfg的配置启动单机版本的服务器: public void runFromConfig(Serv ...
- 一道面试题 包含了new的细节 和运算符的优先级 还有属性访问机制
function Foo() { getName = function () { alert(1); } return this; } Foo.getName = function () { aler ...