【spring boot】9.spring boot+spring-data-jpa的入门使用,实现数据持久化
spring-data-jpa官方使用说明文档:https://docs.spring.io/spring-data/jpa/docs/current/reference/html/
spring-data-jpa的使用说明:https://www.cnblogs.com/WangJinYang/p/4257383.html
spring-data-jpa API地址:https://docs.spring.io/spring-data/data-jpa/docs/current/api/
参考地址:http://blog.didispace.com/springbootdata2/
===============================================================================================
spring boot搭建项目后,想要数据进行持久化操作,更进一步的完善项目的话,就要使用到一个具体的ORM了。而spring boot中完美的支持了spring-data-jpa。
这一篇就使用spring-data-jpa进行入门的数据持久化处理
===============================================================================================
本篇数据库使用mysql,所以pom加入依赖需要两个
<!--jpa hibernate-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!--mysql连接架包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
结构如下:
【entity与domain,dao与repository的区别是什么,看附录2】
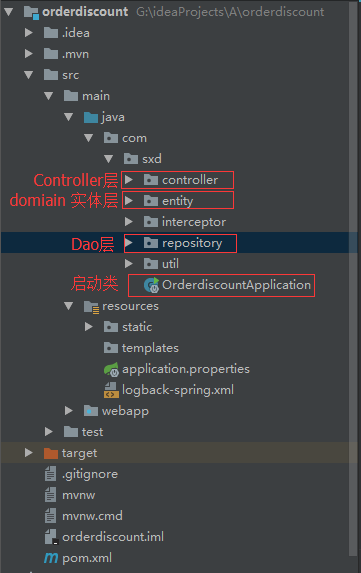
配置文件application.properties
【在首次启动之后,将spring.jpa.hibernate.ddl-auto=create 修改为spring.jpa.hibernate.ddl-auto=update,以免下次启动重新创建所有的数据表】
【或者 直接将值设置为update,也是可以实现首次创建表,且之后实体字段变化或新增实体,都会自动在数据库中更新且不会删除原来的表和数据,所以建议直接使用update,但是不会打印创建表的sql语句】
【application.properties字段详解请看:http://www.cnblogs.com/sxdcgaq8080/p/7890218.html】
#view
spring.mvc.view.prefix = /WEB-INF/views/
spring.mvc.view.suffix = .jsp #datasource
spring.datasource.continue-on-error=false
spring.datasource.url=jdbc:mysql://localhost:3306/orderdiscount
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.jpa.database=mysql
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=update
spring.jpa.properties.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
日志配置文件 logback-spring.xml
【日志文件详解请看:http://www.cnblogs.com/sxdcgaq8080/p/7852858.html】
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="60 seconds" debug="false">
<contextName>logback</contextName>
<!--定义日志文件的存储地址目录-->
<property name="LOG_HOME" value="E:/log/"/>
<!--输出到控制台-->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<withJansi>true</withJansi>
<encoder>
<!--<pattern>%d %p (%file:%line\)- %m%n</pattern>-->
<!--格式化输出:%d:表示日期 %thread:表示线程名 %-5level:级别从左显示5个字符宽度 %msg:日志消息 %n:是换行符-->
<pattern>%black(控制台-) %red(%d{yyyy-MM-dd HH:mm:ss}) %green([%thread]) %highlight(%-5level) %boldMagenta(%logger) - %cyan(%msg%n)</pattern>
<charset>UTF-8</charset>
</encoder>
</appender>
<!--输出到文件-->
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}logback.%d{yyyy-MM-dd-HH-mm}[%i].log</fileNamePattern>
<maxFileSize>10kb</maxFileSize>
<maxHistory>30</maxHistory>
<totalSizeCap>1GB</totalSizeCap>
</rollingPolicy>
<encoder>
<!--格式化输出:%d:表示日期 %thread:表示线程名 %-5level:级别从左显示5个字符宽度 %msg:日志消息 %n:是换行符-->
<pattern>文件记录-%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger - %msg%n</pattern>
<charset>UTF-8</charset>
</encoder>
</appender>
<root level="info">
<appender-ref ref="console" />
<appender-ref ref="file" />
</root>
<logger name="com.sxd.controller"/>
<logger name="com.sxd.util.LogTestController" level="WARN" additivity="false">
<appender-ref ref="console" />
</logger>
</configuration>
要想和数据库打交道,这里还是关系型数据库,那就来个实体和数据库的表对应起来
实体User.java
package com.sxd.entity; import org.hibernate.annotations.GenericGenerator; import javax.persistence.*; @Entity
@GenericGenerator(name = "uuid2", strategy = "org.hibernate.id.UUIDGenerator" )
public class User {
private String id;
private String username;
private String password;
private Integer age; @Id
@GeneratedValue(generator = "uuid2")
public String getId() {
return id;
} public void setId(String id) {
this.id = id;
} @Column(nullable = false)
public String getUsername() {
return username;
} public void setUsername(String username) {
this.username = username;
} @Column(nullable = false)
public String getPassword() {
return password;
} public void setPassword(String password) {
this.password = password;
} @Column(nullable = false)
public Integer getAge() {
return age;
} public void setAge(Integer age) {
this.age = age;
} public User() { } public User(String id, String username, String password, Integer age) {
this.id = id;
this.username = username;
this.password = password;
this.age = age;
}
}
spring-data-jpa的优势体现就是下面这个接口啦!!
【spring-data-jpa的详细介绍和复杂使用http://www.cnblogs.com/sxdcgaq8080/p/7894828.html】
Dao层放在repository目录下 接口UserRepository.java
package com.sxd.repository; import com.sxd.entity.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param; public interface UserRepository extends JpaRepository<User,String>{ User findByUsername(String username); User findByUsernameAndPassword(String username,String password); User findById(String id); @Query("select u from User u where u.username = :name")
User findUser(@Param("name")String username); User findTop3ByAge(Integer age);
}
就这么几步,就能进行数据的持久化操作了。
启动创建数据表如下,执行的sql语句如下:
【如果spring.jpa.hibernate.ddl-auto=update,也会创建数据表,但是不会有SQL语句打印出来】

好了建立一个单元测试类,使用一下自己写的Repository层的方法和已经封装好的一些方法:
JunitTest.java是放在test目录下的
package com.sxd.logexample; import com.sxd.LogExampleApplication;
import com.sxd.entity.User;
import com.sxd.repository.UserRepository;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner; import java.util.List;
import java.util.Objects;
import java.util.UUID; @RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = LogExampleApplication.class)
public class JunitTest { @Autowired
private UserRepository userRepository; @Test
public void dealUser(){ //插入新的数据
for (int i = 0; i < 10; i++) {
User user = new User();
user.setId(UUID.randomUUID().toString());
user.setUsername("用户名"+i);
user.setPassword("123"+i);
user.setAge(i+1); userRepository.saveAndFlush(user);
} //根据ID查询
// User user = userRepository.findById("03d99bf3-a171-4986-a75f-92cadc3aa75b");
// System.out.println(user);//重写了user的toString()方法即可打印出 //根据userRepository中自写方法查询
// User user = userRepository.findByUsernameAndPassword("用户名1","1231");
// System.out.println(user); //查询所有
// List<User> list = userRepository.findAll();
// if(Objects.nonNull(list)){
// list.forEach(i->{
// System.out.println(i);
// });
// } //删除所有
userRepository.deleteAll(); }
}
然后右键在单元测试方法上 运行起来即可。【单元测试,具体看:http://www.cnblogs.com/sxdcgaq8080/p/7894444.html】
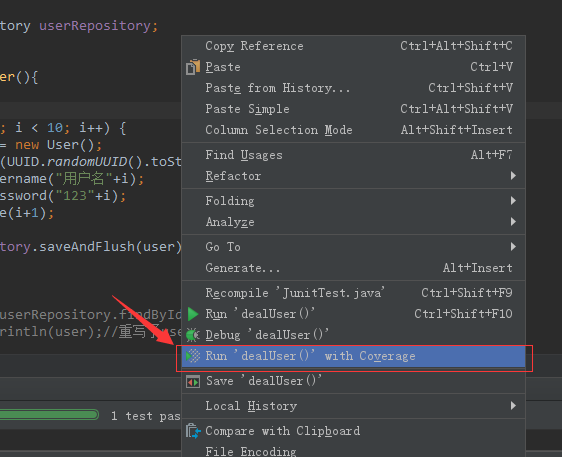
执行完sava方法之后,就会执行插入,sql语句如下:
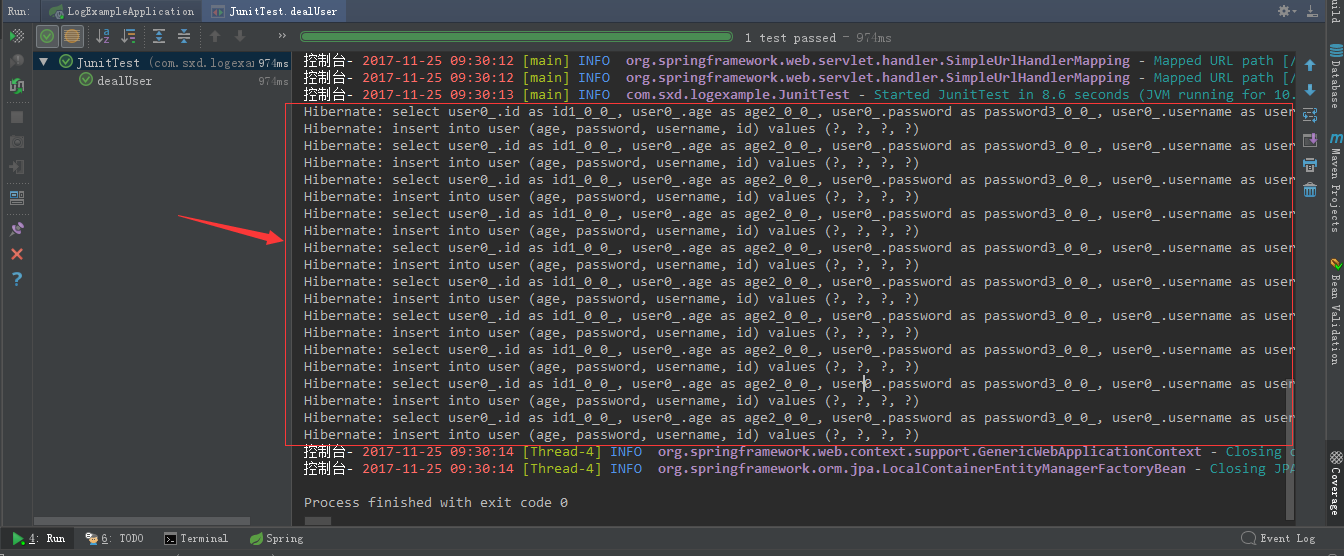
数据库中也插入成功:
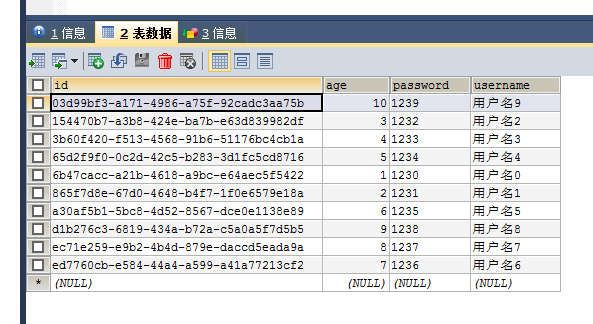
下面的方法 自己一个一个测试即可。
==========================================结束语====================================================
这章就是简单的使用spring-data-jpa进行和数据库交互的操作。数据持久化得以实现,那就解决了项目一个很重大的问题了。但这里只是最最开始的一些,后面会把spring-data-jpa的复杂使用解开面纱。
===========================================附录1:===================================================
如果有人对spring-data-jpa和hibernate是什么关系存在疑问,可以看看这部分:
①JPA首先得介绍一下,他只是一套规范和标准,也就是一堆堆的接口,并未实现;
②hibernate是对JPA的一种实现,就是你具体执行持久化操作调用的方法内具体干了什么,都是Hibernate实现的;
③spring-data-jpa则是对hibernate实行了再封装,大大的简化了原本DAO层的实现,也就是现在的repository层。因为本章就是用的spring-data-jpa,如果你之前使用的是三大框架还是什么巴拉巴拉之类的,肯定是上去先把项目的目录框架,entity,dao,daoimpl,service,serviceimpl,controller层搭建好,才开发的。
④spring spring-boot官方对hibernate是一直都有支持的,而对mybatis则没有,但并不代表它不能与mybatis集成。【这点有点废话,但是却是想表达】
===========================================附录2:===================================================
参考自:http://blog.sina.com.cn/s/blog_93df03f20102vwpm.html
entity:和数据库数据表绝对对应的实体,放在entity下
model:前台需要是什么,model就被处理成什么
domain:代表一个对象模块。
分开来说:
①entity【实体】习惯性使用这个,作为实体的包名。entity中有几个属性,对应的数据表中就有几个字段。并且字段类型都保持绝对一致。
②model【模型】的使用,例如User对象实体中有十个字段,但是前台仅需要username和age的话,那把整个实体传给前台无疑多传输了好些无用的数据。又比如User的sex字段,数据库中存储为男的1,女的2。如果把User对象传给前台,前台js还需要判断一下,而如果sex存储改变了,2为男,1为女,这样js还需要进行改动。所以可以将前台需要的数据封装为model传给前台。而model对象都放在model包下。
③domain【域】是一个订单,一个用户信息等概念的划分。比如一个招聘网站的项目,最重要的对象就是简历了,那么简历是怎么存到数据库的呢,不可能用一张表就能存的,因为简历包含基本信息和工作经验,项目经验,学习经验等。基本信息可以存在简历表,但是涉及到多条的就不行,因为没人知道有多少条工作经验,项目经验,所以必须要单独建工作经验表和项目经验表关联到简历基本信息表。但是前台页面是不关心这些的,前台需要的数据就是一个简历所有信息,这时就可以用到domain来处理,domain里面的类就是一个简历对象,包含了简历基本信息以及list的工作经验,项目经验等。这样前端只需要获取一个对象就行了,不需要同时即要获取基本信息,还要从基本信息里面获取工作经验关联的简历编号,然后再去获取对应的工作经验了。
===========================================附录3:关于自定义简单查询的说明=================================================
| Keyword | Sample | JPQL snippet |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age ⇐ ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection age) | … where x.age not in ?1 |
| TRUE | findByActiveTrue() | … where x.active = true |
| FALSE | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
根据方法名自己生成的sql语句
====================================================================================================================
【spring boot】9.spring boot+spring-data-jpa的入门使用,实现数据持久化的更多相关文章
- Spring Data JPA —— 快速入门
一.概述 JPA : Java Persistence API, Java持久层API,是JDK 5.0注解或XML描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中. Spring D ...
- Spring Data JPA -1-CRUD入门
1) 引入jar包支持 <dependency> <groupId>org.springframework.boot</groupId> <artifactI ...
- Spring data JPA 快速入门
1需求 向客户中插入一条数据 如果使用Jpa框架可以不用先建表 可以使用框架生成表 2 实现步骤 a 创建工程 使用maven管理工程 <properties> ...
- 整合Spring Data JPA与Spring MVC: 分页和排序
之前我们学习了如何使用Jpa访问关系型数据库.比较完整Spring MVC和JPA教程请见Spring Data JPA实战入门,Spring MVC实战入门. 通过Jpa大大简化了我们对数据库的开发 ...
- 整合Spring Data JPA与Spring MVC: 分页和排序pageable
https://www.tianmaying.com/tutorial/spring-jpa-page-sort Spring Data Jpa对于分页以及排序的查询也有着完美的支持,接下来,我们来学 ...
- 【Spring Data 系列学习】了解 Spring Data JPA 、 Jpa 和 Hibernate
在开始学习 Spring Data JPA 之前,首先讨论下 Spring Data Jpa.JPA 和 Hibernate 之前的关系. JPA JPA 是 Java Persistence API ...
- 【Spring Data 系列学习】Spring Data JPA 自定义查询,分页,排序,条件查询
Spring Boot Jpa 默认提供 CURD 的方法等方法,在日常中往往时无法满足我们业务的要求,本章节通过自定义简单查询案例进行讲解. 快速上手 项目中的pom.xml.application ...
- Spring Data JPA 教程(翻译)
写那些数据挖掘之类的博文 写的比较累了,现在翻译一下关于spring data jpa的文章,觉得轻松多了. 翻译正文: 你有木有注意到,使用Java持久化的API的数据访问代码包含了很多不必要的模式 ...
- Spring Data Jpa (五)@Entity实例里面常用注解详解
详细介绍javax.persistence下面的Entity中常用的注解. 虽然Spring Data JPA已经帮我们对数据的操作封装得很好了,约定大于配置思想,帮我们默认了很多东西.JPA(Jav ...
- spring boot(五):spring data jpa的使用
在上篇文章springboot(二):web综合开发中简单介绍了一下spring data jpa的基础性使用,这篇文章将更加全面的介绍spring data jpa 常见用法以及注意事项 使用spr ...
随机推荐
- 【BZOJ 3620】似乎在梦中见过的样子
题目 (夢の中で逢った.ような--) 「Madoka,不要相信 QB!」伴随着 Homura 的失望地喊叫,Madoka 与 QB 签订了契约. 这是 Modoka 的一个噩梦,也同时是上个轮回中所发 ...
- IOS笔记051-手势使用
UIGestureRecognizer 利用UIGestureRecognizer,能轻松识别用户在某个view上面做的一些常见手势 UIGestureRecognizer是一个抽象类,定义了所有手势 ...
- poj1111(单身快乐)
...
- Adaboost和GBDT的区别以及xgboost和GBDT的区别
Adaboost和GBDT的区别以及xgboost和GBDT的区别 以下内容转自 https://blog.csdn.net/chengfulukou/article/details/76906710 ...
- Python之实现不同版本线程池
1.利用queue和threading模块可以实现多个版本的线程池,这里先贴上一个简单的 import queue import time import threading class ThreadP ...
- File IO(NIO.2):读、写并创建文件
简介 本页讨论读,写,创建和打开文件的细节.有各种各样的文件I / O方法可供选择.为了帮助理解API,下图以复杂性排列文件I / O方法 在图的最左侧是实用程序方法readAllBytes,read ...
- UVALive 5987
求第n个数,该数满足至少由3个不同的素数的乘机组成 #include #include #include #include #include using namespace std; int prim ...
- HDU——2089 不要62
不要62 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submis ...
- 【bzoj2127】happiness 最大流
happiness Time Limit: 51 Sec Memory Limit: 259 MBSubmit: 2579 Solved: 1245[Submit][Status][Discuss ...
- Kubectl管理工具
1.常用指令如下 运行应用程序 [root@manager ~]# kubectl run hello-world --replicas=3 --labels="app=example&qu ...