scrapy分布式原理
scrapy分布式原理
关于Scrapy工作流程回顾
Scrapy单机架构
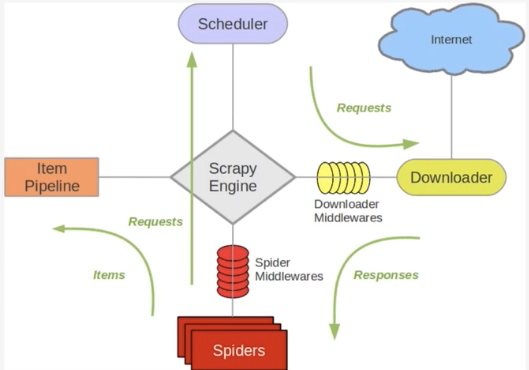
上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列。
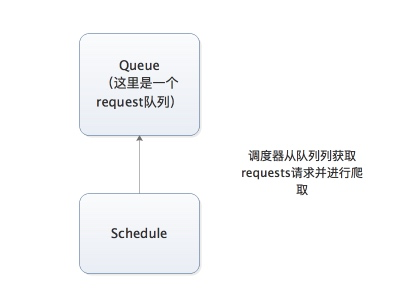
分布式架构
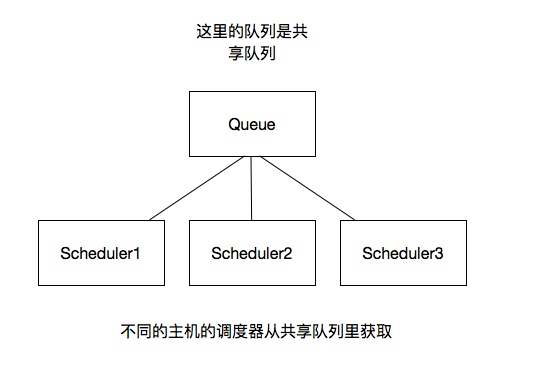
我将上图进行再次更改
这里重要的就是我的队列通过什么维护?
这里一般我们通过Redis为维护,Redis,非关系型数据库,Key-Value形式存储,结构灵活。
并且redis是内存中的数据结构存储系统,处理速度快,提供队列集合等多种存储结构,方便队列维护
如何去重?
这里借助redis的集合,redis提供集合数据结构,在redis集合中存储每个request的指纹
在向request队列中加入Request前先验证这个Request的指纹是否已经加入集合中。如果已经存在则不添加到request队列中,如果不存在,则将request加入到队列并将指纹加入集合
如何防止中断?如果某个slave因为特殊原因宕机,如何解决?
这里是做了启动判断,在每台slave的Scrapy启动的时候都会判断当前redis request队列是否为空
如果不为空,则从队列中获取下一个request执行爬取。如果为空则重新开始爬取,第一台丛集执行爬取向队列中添加request
如何实现上述这种架构?
这里有一个scrapy-redis的库,为我们提供了上述的这些功能
scrapy-redis改写了Scrapy的调度器,队列等组件,利用他可以方便的实现Scrapy分布式架构
关于scrapy-redis的地址:https://github.com/rmax/scrapy-redis
搭建分布式爬虫
参考官网地址:https://scrapy-redis.readthedocs.io/en/stable/
前提是要安装scrapy_redis模块:pip install scrapy_redis
这里的爬虫代码是用的之前写过的爬取知乎用户信息的爬虫
修改该settings中的配置信息:
替换scrapy调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
添加去重的class
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
添加pipeline
如果添加这行配置,每次爬取的数据也都会入到redis数据库中,所以一般这里不做这个配置
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
共享的爬取队列,这里用需要redis的连接信息
这里的user:pass表示用户名和密码,如果没有则为空就可以
REDIS_URL = 'redis://user:pass@hostname:9001'
设置为为True则不会清空redis里的dupefilter和requests队列
这样设置后指纹和请求队列则会一直保存在redis数据库中,默认为False,一般不进行设置
SCHEDULER_PERSIST = True
设置重启爬虫时是否清空爬取队列
这样每次重启爬虫都会清空指纹和请求队列,一般设置为False
SCHEDULER_FLUSH_ON_START=True
分布式
将上述更改后的代码拷贝的各个服务器,当然关于数据库这里可以在每个服务器上都安装数据,也可以共用一个数据,我这里方面是连接的同一个mongodb数据库,当然各个服务器上也不能忘记:
所有的服务器都要安装scrapy,scrapy_redis,pymongo
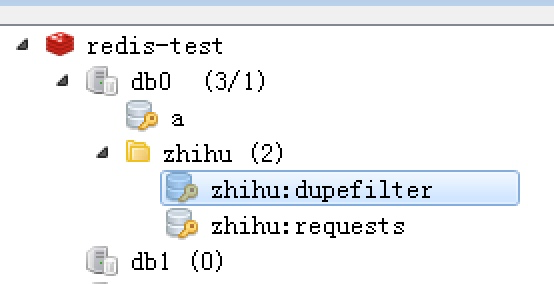
这样运行各个爬虫程序启动后,在redis数据库就可以看到如下内容,dupefilter是指纹队列,requests是请求队列
scrapy分布式原理的更多相关文章
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
- Python爬虫从入门到放弃(二十)之 Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- Python爬虫【五】Scrapy分布式原理笔记
Scrapy单机架构 在这里scrapy的核心是scrapy引擎,它通过里面的一个调度器来调度一个request的队列,将request发给downloader,然后来执行request请求 但是这些 ...
- 爬虫(十七):scrapy分布式原理
一:scrapy工作流程 scrapy单机架构: 单主机爬虫架构: 分布式爬虫架构: 这里重要的就是我的队列通过什么维护?这里一般我们通过Redis为维护,Redis,非关系型数据库,Key-Valu ...
- Python之爬虫(二十二) Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 学习笔记TF061:分布式TensorFlow,分布式原理、最佳实践
分布式TensorFlow由高性能gRPC库底层技术支持.Martin Abadi.Ashish Agarwal.Paul Barham论文<TensorFlow:Large-Scale Mac ...
- scrapy分布式的几个重点问题
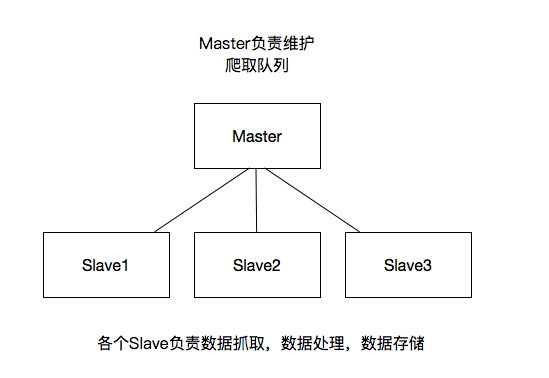
我们之前的爬虫都是在同一台机器运行的,叫做单机爬虫.scrapy的经典架构图也是描述的单机架构.那么分布式爬虫架构实际上就是:由一台主机维护所有的爬取队列,每台从机的sheduler共享该队列,协同存 ...
- scrapy分布式浅谈+京东示例
scrapy分布式浅谈+京东示例: 学习目标: 分布式概念与使用场景 浅谈去重 浅谈断点续爬 分布式爬虫编写流程 基于scrapy_redis的分布式爬虫(阳关院务与京东图书案例) 环境准备: 下载r ...
随机推荐
- 04-树4 是否同一棵二叉搜索树(25 point(s)) 【Tree】
04-树4 是否同一棵二叉搜索树(25 point(s)) 给定一个插入序列就可以唯一确定一棵二叉搜索树.然而,一棵给定的二叉搜索树却可以由多种不同的插入序列得到.例如分别按照序列{2, 1, 3}和 ...
- Kafka理论学习
Kafka Consumer设计解析 http://www.jasongj.com/2015/08/09/KafkaColumn4/
- ps 工具栏使用
1:称动工具,快捷键是v,则选中移动工具:按shift和左键,可移动当前层移到另一层的中间对齐.如果不用sfhift键,则只是移动:alt+左键上移动,则复制层:alt+中间滚轮,则为放大和缩小. 2 ...
- True(False) Positives (Negatives), 召回率和精度定义
True Positive (真正, TP)被模型预测为正的正样本: True Negative(真负 , TN)被模型预测为负的负样本 : False Positive (假正, FP)被模型预测为 ...
- uva 401 Palindromes 解题报告
题目链接:http://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem& ...
- JDBC 笔记3 通过PreparedStatement 对数据库进行增删改查 (转载)
之前MVC时一直用它,学了框架后就没怎么用了.这里转载一位同学的博客,以后可能也会用到的. 转自:https://www.cnblogs.com/zilong882008/archive/2011/1 ...
- windows: Python安装scipy,scikit-image时提示"no lapack/blas resources found"的解决方法
解决方案: 最后,解决我遇到的这个问题的解决方案是来自以下链接的答案: http://www.voidcn.com/blog/z6491679/article/p-5740396.html. 另外还有 ...
- 5.oracle中一个字段中存储'a','b'与'a'与a的写法,存储过程中与之对应
select '''a'',''b''' from dual; --'a','b' select '''a''' from dual; --'a' select 'a' from dual; --a
- java中有关socket通信的学习笔记
最近做的项目中使用到了一些基于java的socket长连接的一些功能,用来穿透有关行业的网闸.用到了也就学习了一下,下面是对学习内容的一个笔记,记录一下也希望有兴趣的同学可以参考一下,加深对javas ...
- checkbox的几种遍历方法
html代码如下: <div> <input type="checkbox" name="ckb" value="1" / ...