Hadoop学习笔记四
一、fsimage,edits和datanode的block在本地文件系统中位置的配置
fsimage:hdfs-site.xml中的dfs.namenode.name.dir 值例如file:///opt/software/hadoop/data/nn/image
edits:hdfs-site.xml中的dfs.namenode.edits.dir
datanode block:hdfs-site.xml中的dfs.datanode.data.dir
secondarynanode的fsimage:hdfs-site.xml中的dfs.namenode.checkpoint.dir
secondarynanode的edits:hdfs-site.xml中的dfs.namenode.checkpoint.edits.dir
一个配置项需要多个文件路径时,用英文的逗号隔开。
修改了fsimage和edits后,需要格式化namenode,或者把旧目录中的文件拷贝过来。否则会因为元数据文件缺失,导致集群无法正常启动。
二、MapReduce程序相关日志路径的配置
MapReduce程序相关日志分为历史作业日志和Container日志。
历史作业日志包括一个作业用了多少个Map,用了多少个Reduce,作业提交时间,作业启动时间,作业完成时间等。
Container日志包括ApplicationMaster日志和普通Task的日志等。
相关的配置在mapred-site.xml中,如下
历史作业日志,默认为HDFS路径,mapreduce.jobhistory.done-dir和mapreduce.jobhistory.intermediate-done-dir,默认为hdfs的tmp目录下
App Master运行的数据目录,yarn.app.mapreduce.am.staging-dir,client将application定义以及需要的jar包文件等上传到hdfs的指定目录,默认为hdfs的tmp目录下
Container日志目录路径,yarn.nodemanager.log-dirs,默认为本地目录${HADOOP_HOME}/logs/userlogs
三、复制或者克隆方式新建虚拟机,建立Hadoop集群
NameNode和DataNode可以位于一个机器上,ResourceManager和NodeManager也可以位于一个机器上。
可以先做好机器规划,主机名,IP,上面所运行的服务等,在一个机器上做好配置,其他的机器以复制或者克隆的方式来直接创建,然后修改mac,IP,主机名等,配置主节点到各从节点的SSH免密码登录。
复制虚拟机文件夹方式可以创建新的虚拟机,创建好后,查看ifconfig中的mac地址,修改ifcfg-eth0的mac配置。修改IP,hostname。
克隆方式创建新的虚拟机时,需要在虚拟机属性中重新生成新的mac地址,修改etc/udev/rules.d/70-persistent-net.rules中,注释掉eth0的行,将eth1改为eth0,并修改mac地址,然后修改ifcfg-eth0的mac配置。修改IP,hostname。
以非root的普通用户启动Hadoop时,需要集群中拥有相同的用户名和密码,并且该用户要有无密码sudo权限。
四、复制方式建立集群时的一些事项
DataNode和NodeManager的配置都在slave.xml中。
可以以tar包形式复制,也可以以scp直接复制scp -rp /opt/software/hadoop/* cyhp@hadoop-nn.cloudy.com:/opt/software/hadoop。cyhp为共同的用户名。
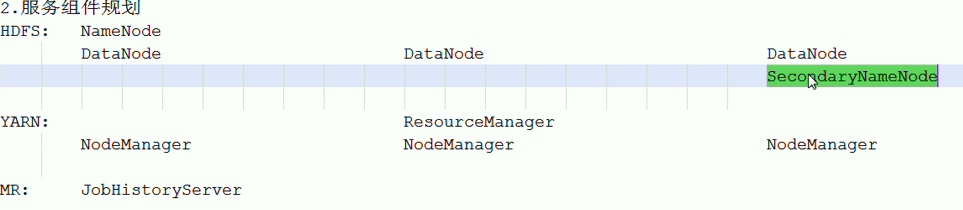
在node1,node2,node3上建立如下的集群时,需要依次启动各组件:
在node1,node2,node3上依次启动NameNode,DataNode,SecondaryNameNode,ResourceManager,NodeManager,JobHistoryServer。
HDFS的监控在Namenode节点的50070端口,YARN的监控在ResourceManager节点的8088端口。JobHistoryServer默认端口为19888.
五、Hadoop基准测试
集群环境安装好了之后,还需要对环境做基准测试,测试dfs的读写速度,网卡的读写速度,mr压力测试等。
查看测试程序的帮助信息:hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-tests.jar
测试写速度:向HDFS文件系统中写入数据,10个文件,每个文件10MB,文件存放到/benchmarks/TestDFSIO/io_data中
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB
查看写入结果cat TestDFSIO_results.log
测试读速度:在HDFS文件系统中读入10个文件,每个文件10M
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB
查看结果cat TestDFSIO_results.log
删除临时文件:hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-tests.jar TestDFSIO -clean
六、无密钥SSH登录的配置
使用start-dfs.sh启动dfs时,需要配置namenode节点到其他datanode节点的无密钥登录。
使用start-yarn.sh启动yarn时,需要配置resourcemanager节点到其他nodemanager节点的无密钥登录。
先使用kengen生成公钥和秘钥后,使用scp拷贝到其他机器,也可以简单地使用ssh-copy-id otherhostname的方式。
本地即是namenode又是datanode时,也需要拷贝公钥到本机。
使用hadoop-demons.sh stop datanode可以依次停止多个节点上的datanode进程。
Hadoop学习笔记四的更多相关文章
- hadoop学习笔记(四)——eclipse+maven+hadoop2.5.2源代码
Eclipse同maven进口hadoop源代码 1) 安装和配置maven环境变量 M2_HOME: D:\profession\hadoop\apache-maven-3.3.3 PATH: % ...
- hadoop学习笔记(四):HDFS文件权限,安全模式,以及整体注意点总结
本文原创,转载注明作者和原文链接! 一:总结注意点: 到现在为止学习到的角色:三个NameNode.SecondaryNameNode.DataNode 1.存储的是每一个文件分割存储之后的元数据信息 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记—5.自定义类型处理手机上网日志
转载自http://www.cnblogs.com/edisonchou/p/4288737.html Hadoop学习笔记—5.自定义类型处理手机上网日志 一.测试数据:手机上网日志 1.1 关于这 ...
- hadoop学习笔记-目录
以下是hadoop学习笔记的顺序: hadoop学习笔记(一):概念和组成 hadoop学习笔记(二):centos7三节点安装hadoop2.7.0 hadoop学习笔记(三):hdfs体系结构和读 ...
- C#可扩展编程之MEF学习笔记(四):见证奇迹的时刻
前面三篇讲了MEF的基础和基本到导入导出方法,下面就是见证MEF真正魅力所在的时刻.如果没有看过前面的文章,请到我的博客首页查看. 前面我们都是在一个项目中写了一个类来测试的,但实际开发中,我们往往要 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
随机推荐
- Playrix Codescapes Cup (Codeforces Round #413, rated, Div. 1 + Div. 2)(A.暴力,B.优先队列,C.dp乱搞)
A. Carrot Cakes time limit per test:1 second memory limit per test:256 megabytes input:standard inpu ...
- hdu_1576A/B(扩展欧几里得求逆元)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1576 A/B Time Limit: 1000/1000 MS (Java/Others) Me ...
- UEP-find查询
实体类: @Entity @Table(name = "xxxxx") public class WzInitializeStoreInfo extends EntityBean{ ...
- Ceph部署(一)集群搭建
背景 Ceph简介 Ceph是一个分布式存储,可以提供对象存储.块存储和文件存储,其中对象存储和块存储可以很好地和各大云平台集成.一个Ceph集群中有Monitor节点.MDS节点(可选,用于文件存储 ...
- oracle存储过程的创建和使用
创建存储过程: 格式:create or replace procedure procedure_name(参数 参数类型) Is/as 变量1 变量1的类型: begin ----------业务逻 ...
- SQL Server 使用问题解答(持续更新中)
问题一:sql server 2014不允许保存更改,您所做的更改要求删除并重新创建以下表 解答:工具-选项-不勾选组织保存要求重新创建表的更改,如下图确定.
- .24-浅析webpack源码之事件流compilation(2)
下一个compilation来源于以下代码: compiler.apply(new EntryOptionPlugin()); compiler.applyPluginsBailResult(&quo ...
- 从零开始学习前端开发 — 15、CSS3过渡、动画
一.css3过渡 语法: transition: 过渡属性 过渡时间 延迟时间 过渡方式; 1.过渡属性(transition-property) 取值:all 所有发生变化的css属性都添加过渡 e ...
- ACTION_NAME等常量 不能在模板里直接取值?
在控制器里可以取得,显示模板之前需要向模板传递. condition 下用$Think.const.MODULE_NAME 在模板里要用{$Think.ACTION_NAME}
- 基于VUE的九宫格抽奖功能
HTML代码: <template> <div class="luckDraw"> <title-bar :title="title&quo ...