Python之算法
一、什么算法
算法:一个计算过程,解决问题的方法

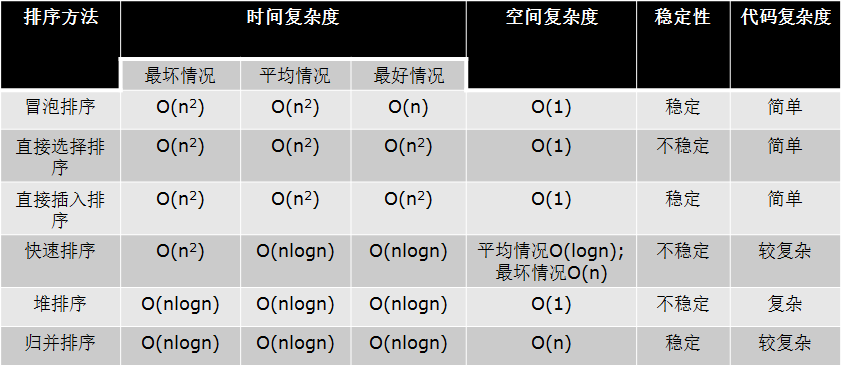
二、时间复杂度
看代码:

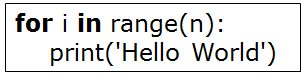




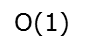
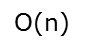







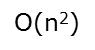

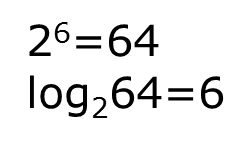


Ο(1)<Ο(log2n)<Ο(n)<Ο(nlog2n)<Ο(n2)<O(n2logn)< Ο(n3)<…<Ο(2^n)<Ο(n!)

三、空间复杂度
空间复杂度:用来评估算法内存占用大小的一个式子
复习:递归
递归的两个特点:
调用自身
结束条件
看下面几个函数
def func1(x):
print(x)
func1(x-1) def func2(x):
if x>0:
print(x)
func2(x+1) def func3(x):
if x>0:
print(x)
func3(x-1) def func4(x):
if x>0:
func4(x-1)
print(x)

def test(n):
if n == 0:
print("我的小鲤鱼", end='')
else:
print("抱着", end='')
test(n-1)
print("的我", end='') test(5)
练习
递归实例:汉诺塔问题






t = 0 def hanoi(n, A, B, C):
global t
if n > 0:
hanoi(n-1, A, C, B)
t += 1
print("%s -> %s" % (A, C))
hanoi(n-1, B, A, C) hanoi(8,'A','B','C')
print(t)
汉诺塔问题

列表查找

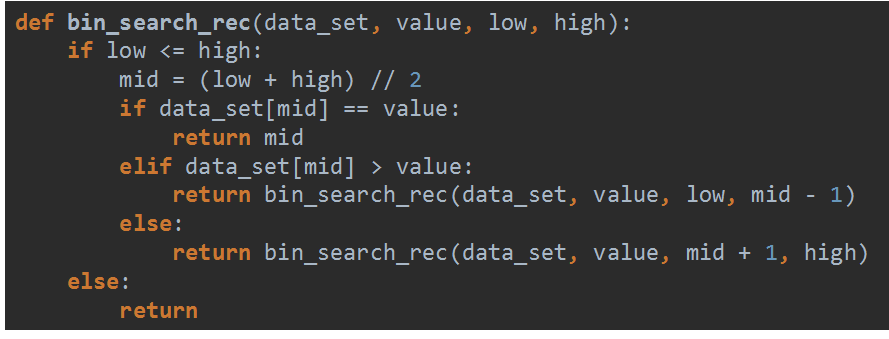
二分法查找
使用二分法查找来查找3




递归版本的二分法查找


排序Low B三人组
冒泡排序
选择排序
插入排序
算法的关键点:
有序区
无序区
1、冒泡排序的思路




冒泡排序---优化

import random
from timewrap import * @cal_time
def bubble_sort(li):
for i in range(len(li) - 1):
# i 表示趟数
# 第 i 趟时: 无序区:(0,len(li) - i)
for j in range(0, len(li) - i - 1):
if li[j] > li[j+1]:
li[j], li[j+1] = li[j+1], li[j] @cal_time
def bubble_sort_2(li): #冒泡排序优化
for i in range(len(li) - 1):
# i 表示趟数
# 第 i 趟时: 无序区:(0,len(li) - i)
change = False
for j in range(0, len(li) - i - 1):
if li[j] > li[j+1]:
li[j], li[j+1] = li[j+1], li[j]
change = True
if not change:
return li = list(range(10000))
# random.shuffle(li)
# print(li)
bubble_sort_2(li)
print(li)
冒泡排序
选择排序的思路


选择排序代码
import random
from timewrap import * @cal_time
def select_sort(li):
for i in range(len(li) - 1):
# i 表示趟数,也表示无序区开始的位置
min_loc = i # 最小数的位置
for j in range(i + 1, len(li)):
if li[j] < li[min_loc]:
min_loc = j
li[i], li[min_loc] = li[min_loc], li[i] li = list(range(10000))
random.shuffle(li)
print(li)
select_sort(li)
print(li)
选择程序

插入排序思路



插入排序代码
import random
from timewrap import * @cal_time
def insert_sort(li):
for i in range(1, len(li)):
# i 表示无序区第一个数
tmp = li[i] # 摸到的牌
j = i - 1 # j 指向有序区最后位置
while li[j] > tmp and j >= 0:
#循环终止条件: 1. li[j] <= tmp; 2. j == -1
li[j+1] = li[j]
j -= 1
li[j+1] = tmp li = list(range(10000))
random.shuffle(li)
print(li)
insert_sort(li)
print(li)
插入排序

排序LOW B三人组------小结

快速排序:





















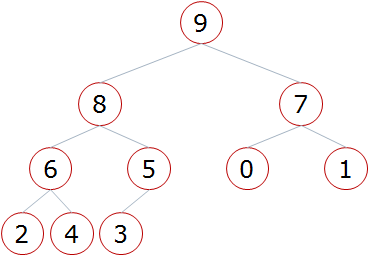
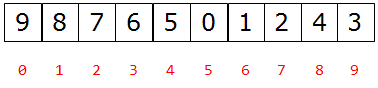











from timewrap import *
import random def _sift(li, low, high):
"""
:param li:
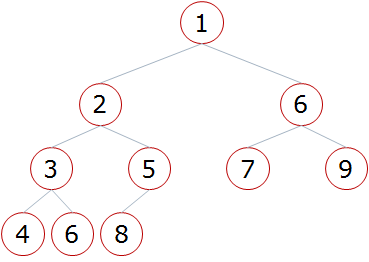
:param low: 堆根节点的位置
:param high: 堆最有一个节点的位置
:return:
"""
i = low # 父亲的位置
j = 2 * i + 1 # 孩子的位置
tmp = li[low] # 原省长
while j <= high:
if j + 1 <= high and li[j + 1] > li[j]: # 如果右孩子存在并且右孩子更大
j += 1
if tmp < li[j]: # 如果原省长比孩子小
li[i] = li[j] # 把孩子向上移动一层
i = j
j = 2 * i + 1
else:
li[i] = tmp # 省长放到对应的位置上(干部)
break
else:
li[i] = tmp # 省长放到对应的位置上(村民/叶子节点) def sift(li, low, high):
"""
:param li:
:param low: 堆根节点的位置
:param high: 堆最有一个节点的位置
:return:
"""
i = low # 父亲的位置
j = 2 * i + 1 # 孩子的位置
tmp = li[low] # 原省长
while j <= high:
if j + 1 <= high and li[j+1] > li[j]: # 如果右孩子存在并且右孩子更大
j += 1
if tmp < li[j]: # 如果原省长比孩子小
li[i] = li[j] # 把孩子向上移动一层
i = j
j = 2 * i + 1
else:
break
li[i] = tmp @cal_time
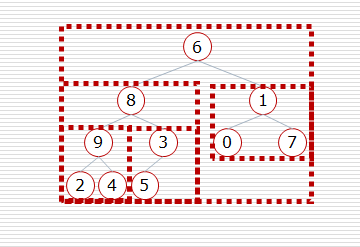
def heap_sort(li):
n = len(li)
# 1. 建堆
for i in range(n//2-1, -1, -1):
sift(li, i, n-1)
# 2. 挨个出数
for j in range(n-1, -1, -1): # j表示堆最后一个元素的位置
li[0], li[j] = li[j], li[0]
# 堆的大小少了一个元素 (j-1)
sift(li, 0, j-1) li = list(range(10000))
random.shuffle(li)
heap_sort(li)
print(li) # li=[2,9,7,8,5,0,1,6,4,3]
# sift(li, 0, len(li)-1)
# print(li)
堆排序代码
import heapq, random li = [5,8,7,6,1,4,9,3,2] heapq.heapify(li)
print(heapq.heappop(li))
print(heapq.heappop(li)) def heap_sort(li):
heapq.heapify(li)
n = len(li)
new_li = []
for i in range(n):
new_li.append(heapq.heappop(li))
return new_li li = list(range(10000))
random.shuffle(li)
# li = heap_sort(li)
# print(li) print(heapq.nlargest(100, li))
堆排序代码1





import random
from timewrap import *
import copy
import sys def merge(li, low, mid, high):
i = low
j = mid + 1
ltmp = []
while i <= mid and j <= high:
if li[i] < li[j]:
ltmp.append(li[i])
i += 1
else:
ltmp.append(li[j])
j += 1
while i <= mid:
ltmp.append(li[i])
i += 1
while j <= high:
ltmp.append(li[j])
j += 1
li[low:high+1] = ltmp def _merge_sort(li, low, high):
if low < high: # 至少两个元素
mid = (low + high) // 2
_merge_sort(li, low, mid)
_merge_sort(li, mid+1, high)
merge(li, low, mid, high)
print(li[low:high+1]) def merge_sort(li):
return _merge_sort(li, 0, len(li)-1) li = list(range(16))
random.shuffle(li)
print(li)
merge_sort(li) print(li)
一次归并代码

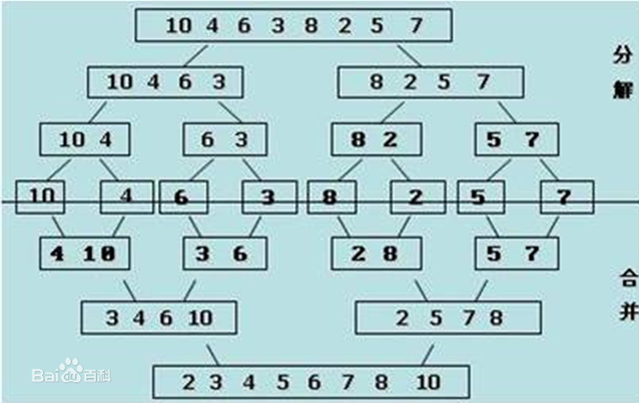









希尔排序
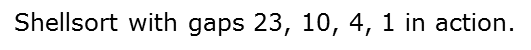
插入排序
def insert_sort(li):
for i in range(1, len(li)):
# i 表示无序区第一个数
tmp = li[i] # 摸到的牌
j = i - 1 # j 指向有序区最后位置
while li[j] > tmp and j >= 0:
#循环终止条件: 1. li[j] <= tmp; 2. j == -1
li[j+1] = li[j]
j -= 1
li[j+1] = tmp 比较 希尔排序
def shell_sort(li):
d = len(li) // 2
while d > 0:
for i in range(d, len(li)):
tmp = li[i]
j = i - d
while li[j] > tmp and j >= 0:
li[j+d] = li[j]
j -= d
li[j+d] = tmp
d = d >> 1
希尔排序

计数排序


# 0 0 1 1 2 4 3 3 1 4 5 5
import random
import copy
from timewrap import * @cal_time
def count_sort(li, max_num = 100):
count = [0 for i in range(max_num+1)]
for num in li:
count[num]+=1
li.clear()
for i, val in enumerate(count):
for _ in range(val):
li.append(i) @cal_time
def sys_sort(li):
li.sort() li = [random.randint(0,100) for i in range(100000)]
li1 = copy.deepcopy(li)
count_sort(li)
sys_sort(li1)
计算排序
from collections import deque
f = open('test.txt','r')
q = deque(f, 3)
for line in q:
print(line)
问题
Python之算法的更多相关文章
- Python基础算法综合:加减乘除四则运算方法
#!usr/bin/env python# -*- coding:utf-8 -*-#python的算法加减乘除用符号:+,-,*,/来表示#以下全是python2.x写法,3.x以上请在python ...
- xsank的快餐 » Python simhash算法解决字符串相似问题
xsank的快餐 » Python simhash算法解决字符串相似问题 Python simhash算法解决字符串相似问题
- python聚类算法实战详细笔记 (python3.6+(win10、Linux))
python聚类算法实战详细笔记 (python3.6+(win10.Linux)) 一.基本概念: 1.计算TF-DIF TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库 ...
- python排序算法实现(冒泡、选择、插入)
python排序算法实现(冒泡.选择.插入) python 从小到大排序 1.冒泡排序: O(n2) s=[3,4,2,5,1,9] #count = 0 for i in range(len(s)) ...
- Python C3 算法 手动计算顺序
Python C3 算法 手动计算顺序 手动计算类继承C3算法原则: 以所求类的直接子类的数目分成相应部分 按照从左往右的顺序依次写出继承关系 继承关系第一个第一位,在所有后面关系都是第一个出现的 ...
- python聚类算法解决方案(rest接口/mpp数据库/json数据/下载图片及数据)
1. 场景描述 一直做java,因项目原因,需要封装一些经典的算法到平台上去,就一边学习python,一边网上寻找经典算法代码,今天介绍下经典的K-means聚类算法,算法原理就不介绍了,只从代码层面 ...
- python相关性算法解决方案(rest/数据库/json/下载)
1. 场景描述 一直做java,因项目原因,需要封装一些经典的算法到平台上去,就一边学习python,一边网上寻找经典算法代码,今天介绍下经典的相关性算法,算法原理就不介绍了,只从代码层面进行介绍,包 ...
- 关联规则 -- apriori 和 FPgrowth 的基本概念及基于python的算法实现
apriori 使用Apriori算法进行关联分析 貌似网上给的代码是这个大牛写的 关联规则挖掘及Apriori实现购物推荐 老师 Apriori 的python算法实现 python实现关联规则 ...
- Python排序算法之选择排序定义与用法示例
Python排序算法之选择排序定义与用法示例 这篇文章主要介绍了Python排序算法之选择排序定义与用法,简单描述了选择排序的功能.原理,并结合实例形式分析了Python定义与使用选择排序的相关操作技 ...
- 44.python排序算法(冒泡+选择)
一,冒泡排序: 是一种简单的排序算法.它重复地遍历要排序的数列,一次比较两个,如果他们的排序错误就把他们交换过来. 冒泡排序是稳定的(所谓稳定性就是两个相同的元素不会交换位置) 冒泡排序算法的运作如下 ...
随机推荐
- ORA-28002 -- oracle密码过期
1.登录oracle 2.查看密码有效期时长 SELECT * FROM dba_profiles s WHERE s.profile='DEFAULT' AND resource_name='PAS ...
- 爬虫、请求库requests
阅读目录 一 介绍 二 基于GET请求 三 基于POST请求 四 响应Response 五 高级用法 一 介绍 #介绍:使用requests可以模拟浏览器的请求,比起之前用到的urllib,req ...
- spring boot +mysql + mybatis + druid的整理(一)——单数据源
一,使用spring boot脚手架搭建spring boot框架生成maven项目 如下图所示: 设置自定义的坐标,即左侧的Group和Artifact,右侧可以搜索添加一些依赖,搜索不到的可以在p ...
- python os 模块
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径os.chdir("dirname") 改变当前脚本工作目录:相当于shell下cdos.curdir ...
- b9934107349625014ec251e1333d73a8 这个代码是mad5值
Message Digest Algorithm MD5(中文名为消息摘要算法第五版)为计算机安全领域广泛使用的一种散列函数,用以提供消息的完整性保护.该算法的文件号为RFC 1321(R.Rives ...
- Codeforces 777B Game of Credit Cards
B. Game of Credit Cards time limit per test:2 seconds memory limit per test:256 megabytes input:stan ...
- BZOJ 1083: [SCOI2005]繁忙的都市【Kruscal最小生成树裸题】
1083: [SCOI2005]繁忙的都市 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 2925 Solved: 1927[Submit][Sta ...
- TypeScript笔记 5--变量声明(解构和展开)
解构是什么 解构(destructuring assignment)是一种表达式,将数组或者对象中的数据赋给另一变量. 在开发过程中,我们经常遇到这样问题,需要将对象某个属性的值赋给其它两个变量.代码 ...
- 最小生成树之Prim算法
描述 最近,小Hi很喜欢玩的一款游戏模拟城市开放出了新Mod,在这个Mod中,玩家可以拥有不止一个城市了! 但是,问题也接踵而来--小Hi现在手上拥有N座城市,且已知这N座城市中任意两座城市之间建造道 ...
- 使用django建博客时遇到的URLcon相关错误以及解决方法。错误提示:类型错误:include0获得一个意外的关键参数app_name
root@nanlyvm:/home/mydj/mysite# python manage.py runserver Performing system checks... Unhandled exc ...