Django_ORM操作 - 查询
ORM 操作
必知必会13条
<1> all():
查询所有结果 <2> filter(**kwargs):
它包含了与所给筛选条件相匹配的对象 <3> get(**kwargs):
返回与所给筛选条件相匹配的对象
返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。 <4> exclude(**kwargs):
它包含了与所给筛选条件不匹配的对象 <5> values(*field):
返回一个ValueQuerySet,
运行后得到的不是一系列model的实例化对象,而是一个可迭代的字典序列 <6> values_list(*field):
它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 <7> order_by(*field):
对查询结果排序 <8> reverse():
对查询结果反向排序,请注意reverse()通常只能在具有已定义顺序的QuerySet上调用
(在model类的Meta中指定ordering或调用order_by()方法)。 <9> distinct():
从返回结果中剔除重复纪录
(如果你查询跨越多个表,可能在计算QuerySet时得到重复的结果此时可以使用distinct(),
注意只有在PostgreSQL中支持按字段去重。) <10> count():
返回数据库中匹配查询(QuerySet)的对象数量。 <11> first():
返回第一条记录
.all().first 等效于 .first() <12> last():
返回最后一条记录 <13> exists():
如果QuerySet包含数据,就返回True,否则返回False
返回QuerySet对象的方法有
all()
filter()
exclude()
order_by()
reverse()
distinct()
特殊的QuerySet
values() 返回一个可迭代的字典序列
values_list() 返回一个可迭代的元祖序列
具体的对象是无法使用这两个方法的
原理上来说models.py 里面的 class类 中就没有 这两个属性
这两个属性只针对于一个QuerySet序列集进行筛选才可以使用
比如 .filter(id=1) 虽然只返回了一个QuerySet对象 但是也可以使用
返回具体对象的
get()
first()
last()
对象可以直接 .属性 的方法去取值
原理上来说在数据库对象的里面就有属性自然是可以知己调用的
返回布尔值的方法
exists()
返回数字的方法有
count()
对象和QuerySet对象的区别
具体对象
- 可以直接 .属性 的方法去取值
- 本质上来说具体对象就是 models.py 里面的 class类的实例化,本身就有属性可以自己调用
- 无法使用values()和values_list()的, 因为自己的属性里面就没有
- 没有 .update() 方法, 在QuerySet对象才可以调用
QuerySet对象
- 可以调用values()和values_list()
- 这两个属性只针对于一个QuerySet序列集进行筛选才可以使用
- 比如 .filter(id=1) 虽然只返回了一个QuerySet对象 但是也可以使用
转换
QuerySet对象------>具体对象
QuerySet对象.first()
QuerySet对象[0]
# 查询 "部门表" 的全部内容
# 查询的时候不带 values或者values_list 默认就是查询 all() ret = models.Employee.objects.all()
# """
# SELECT `employee`.`id`, `employee`.`name`, `employee`.`age`, `employee`.`salary`, `employee`.`province`, `employee`.`dept` FROM `employee` LIMIT 21; args=()
# """ # 查询所有人的 "部门" 和 "年龄"
# values 或者 values_list 里面写什么就相当于 select 什么字段 ret = models.Employee.objects.all().values("dept", "age")
# """
# SELECT `employee`.`dept`, `employee`.`age` FROM `employee` LIMIT 21; args=()
# """
单表查询之神奇的双下划线
models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据 models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in models.Tb1.objects.filter(name__contains="ven") # 获取name字段包含"ven"的 models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 models.Tb1.objects.filter(id__range=[1, 3]) # id范围是1到3的,等价于SQL的bettwen and 左右都包含 # 类似的还有:startswith,istartswith, endswith, iendswith # date字段还可以单独将年月日拿出来 models.Class.objects.filter(birtday__year=2017)
models.Class.objects.filter(birtday__month=7)
models.Class.objects.filter(birtday__day=17)
基础查询操作
基于对象关联查询
一对多查询(Book--Publish)
正向查询,按字段
book_obj.publish : 与这本书关联的出版社对象
book_obj.publish.addr: 与这本书关联的出版社的地址
反向查询,按表名_set
publish_obj.book_set: 与这个出版社关联的书籍对象集合
publish_obj.book_set.all() :[obj1,obj2,....]
一对一查询(Author---AuthorDetail)
正向查询,按字段
author_obj.ad : 与这个作者关联的作者详细信息对象
反向查询:按表名
author_detail_obj.author : 与这个作者详细对象关联的作者对象
多对多(Book----Author)
正向查询,按字段
book_obj.authorList.all(): 与这本书关联的所有这作者对象的集合 [obj1,obj2,....]
book_obj.authorList.all().values("name"): 如果想查单个值的时候可以这样查
反向查询,按表名_set
author_obj.book_set.all() : 与这个作者关联的所有书籍对象的集合
book_obj.book_set.all().values("name"): 如果想查单个值的时候可以这样查
基于双下滑线的跨表查询(queryset对象查询)
一对多查询(Book--Publish)
正向查询,按字段
# 查询linux这本书的出版社的名字:
models.Book.objects.all().filter(title="linux").values("publish__name")
反向查询:按表名
# 查询人民出版社出版过的所有书籍的名字
models.Publish.objects.filter(name="人民出版社出版").values("book__title")
一对一查询(Author---AuthorDetail)
正向查询,按字段
#查询egon的手机号
models.Author.objects.filter(name="egon").values("ad__tel")
反向查询:按表名
#查询手机号是151的作者
models.AuthorDetail.objects.filter(tel="").values("author__name")
多对多(Book----Author)
正向查询,按字段
#查询python这本书的作者的名字
models.Book.objects.filter(title="python").values("authorList__name") [{},{},{},{}]
反向查询,按表名
#查询alex出版过的出的价格
models.Author.objects.filter(name="alex").values("book__price")
ps:
如果哟有设置,反向查询的时候都用:related_name 的值
publish=models.ForeignKey("Publish",related_name="bookList")
authorlist=models.ManyToManyField("Author",related_name="bookList")
ad=models.models.OneToOneField("AuthorDetail",related_name="authorInfo")
ManyToManyField
概念原理
利用 关联管理器 进行维护
- 外键关系的反向查询
- 多对多关联关系
create()
创建一个新的对象,保存对象,并将它添加到关联对象集之中,返回新创建的对象。
models.Author.objects.first().book_set.create(title="羊驼之歌", publish_id=2)
add()
把指定的model对象添加到关联对象集中。
添加对象
>>> author_objs = models.Author.objects.filter(id__lt=3)
>>> models.Book.objects.first().authors.add(*author_objs)
添加id
>>> models.Book.objects.first().authors.add(*[1, 2])
set()
更新model对象的关联对象。
book_obj = models.Book.objects.first()
book_obj.authors.set([2, 3])
remove()
从关联对象集中移除执行的model对象
book_obj = models.Book.objects.first()
author_obj.books.remove(book_obj)
author_obj.books.remove(8) # 把id = 8 的书删掉
clear()
从关联对象移除一切对象。
book_obj = models.Book.objects.first()
book_obj.authors.clear()
注意:
对于ForeignKey对象,clear()和remove()方法仅在null=True时存在。
# ForeignKey字段没设置null=True时,
class Book(models.Model):
title = models.CharField(max_length=32)
publisher = models.ForeignKey(to=Publisher) # 没有clear()和remove()方法:
>>> models.Publisher.objects.first().book_set.clear()
Traceback (most recent call last):
File "<input>", line 1, in <module>
AttributeError: 'RelatedManager' object has no attribute 'clear' # 当ForeignKey字段设置null=True时,
class Book(models.Model):
name = models.CharField(max_length=32)
publisher = models.ForeignKey(to=Class, null=True) # 此时就有clear()和remove()方法:
dels.Publisher.objects.first().book_set.clear()
注意
对于所有类型的关联字段,add()、create()、remove() 和 clear(), set() 都会马上更新数据库。
换句话说,在关联的任何一端,都不需要再调用save()方法。
基于对象以及 queryset 对象的综合查询示例
from django.shortcuts import render,HttpResponse
# Create your views here.
from app01 import models
def query(request):
# #####################基于对象查询(子查询)##############################
# 按字段(publish)
# 一对多 book -----------------> publish
# <----------------
# book_set.all()
# 正向查询按字段:
# 查询python这本书籍的出版社的邮箱
# python=models.Book.objects.filter(title="python").first()
# print(python.publish.email)
# 反向查询按 表名小写_set.all()
# 苹果出版社出版的书籍名称
# publish_obj=models.Publish.objects.filter(name="苹果出版社").first()
# for obj in publish_obj.book_set.all():
# print(obj.title)
# 按字段(authors.all())
# 多对多 book -----------------------> author
# <----------------
# book_set.all()
# 查询python作者的年龄
# python = models.Book.objects.filter(title="python").first()
# for author in python.authors.all():
# print(author.name ,author.age)
# 查询alex出版过的书籍名称
# alex=models.Author.objects.filter(name="alex").first()
# for book in alex.book_set.all():
# print(book.title)
# 按字段 authorDetail
# 一对一 author -----------------------> authordetail
# <----------------
# 按表名 author
#查询alex的手机号
# alex=models.Author.objects.filter(name='alex').first()
# print(alex.authorDetail.telephone)
# 查询家在山东的作者名字
# ad_list=models.AuthorDetail.objects.filter(addr="shandong")
#
# for ad in ad_list:
# print(ad.author.name)
'''
对应sql:
select publish_id from Book where title="python"
select email from Publish where nid = 1
'''
# #####################基于queryset和__查询(join查询)############################
# 正向查询:按字段 反向查询:表名小写
# 查询python这本书籍的出版社的邮箱
# ret=models.Book.objects.filter(title="python").values("publish__email")
# print(ret.query)
'''
select publish.email from Book
left join Publish on book.publish_id=publish.nid
where book.title="python"
'''
# 苹果出版社出版的书籍名称
# 方式1:
ret1=models.Publish.objects.filter(name="苹果出版社").values("book__title")
print("111111111====>",ret1.query)
#方式2:
ret2=models.Book.objects.filter(publish__name="苹果出版社").values("title")
print("2222222222====>", ret2.query)
#查询alex的手机号
# 方式1:
ret=models.Author.objects.filter(name="alex").values("authorDetail__telephone")
# 方式2:
models.AuthorDetail.objects.filter(author__name="alex").values("telephone")
# 查询手机号以151开头的作者出版过的书籍名称以及书籍对应的出版社名称
ret=models.Book.objects.filter(authors__authorDetail__telephone__startswith="").values('title',"publish__name")
print(ret.query)
return HttpResponse("OK")
queryset对象特性及优化
特性:
惰性执行
books = BookInfo.objects.all() # 此时,数据库并不会进行实际查询
# 只有当真正使用时,如遍历的时候,才会真正去数据库进行查询
for b in books:
print(b)
缓存
# 进行数据库实际查询遍历,保存结果到bs,会进行数据库实际交互
bs = [b.id for b in BookInfo.objects.all()] # 再次调用缓存结果bs,不再进行数据库查询,而是使用缓存结果
优化方法:
exists()
简单的使用if语句进行判断也会完全执行整个queryset并且把数据放入cache,虽然你并不需要这些数据!为了避免这个,可以用exists()方法来检查是否有数据:
if queryResult.exists():
#SELECT (1) AS "a" FROM "blog_article" LIMIT 1; args=()
print("exists...")
iterator()
当queryset非常巨大时,cache会成为问题。
处理成千上万的记录时,巨大的queryset可能会锁住系统进程,让你的程序濒临崩溃。
要避免在遍历数据的同时产生queryset cache,可以使用 iterator() 方法 来获取数据,处理完数据就将其丢弃
objs = Book.objects.all().iterator() # iterator()可以一次只从数据库获取少量数据,这样可以节省内存
for obj in objs:
print(obj.title) # 基于迭代器的特性,被遍历到底部之后下次在使用是无效的了。
for obj in objs:
print(obj.title)
使用 .iterator() 来防止生成cache,意味着遍历同一个queryset时会重复执行查询.
所以使 用 .iterator() 时需确保操作一个大queryset时没有重复执行查询.
总结:
Queryset的cache是用于减少程序对数据库的查询,在通常的使用下会保证只有在需要的时候才会查询数据库。
使用exists()和iterator()方法可以优化程序对内存的使用。不过,由于它们并不会生成queryset cache,可能 会造成额外的数据库查询。
聚合
导入
from django.db.models import Avg, Sum, Max, Min, Count
示例
>>> from django.db.models import Avg, Sum, Max, Min, Count
>>> models.Book.objects.all().aggregate(Avg("price"))
{'price__avg': 13.233333}
# 指定名称
>>> models.Book.objects.aggregate(average_price=Avg('price'))
{'average_price': 13.233333} # 多次聚合
>>> models.Book.objects.all().aggregate(Avg("price"), Max("price"), Min("price"))
{'price__avg': 13.233333, 'price__max': Decimal('19.90'), 'price__min': Decimal('9.90')}
注意:
aggregate 返回的是一个字典,而不是queryset 对象
分组
命令
Employee.objects.values("dept").annotate(avg=Avg("salary").values(dept, "avg")
示例
# 每个 “省” 的 “平均工资” , 查询后的结果为 “省 : 平均工资 ”
# annotate前面是什么就按照什么来分组,annotate后面的字段是被分组后被计算的新增数据列, ret = models.Employee.objects.values("province").annotate(a=Avg("salary")).values("province", "a")
# """
# SELECT `employee`.`province`, AVG(`employee`.`salary`) AS `a` FROM `employee` GROUP BY `employee`.`province` ORDER BY NULL LIMIT 21; args=()
# """
# 统计每一本书的作者个数
book_list = models.Book.objects.all().annotate(author_num=Count("author")) # 统计出每个出版社买的最便宜的书的价格
publisher_list = models.Publisher.objects.annotate(min_price=Min("book__price"))
publisher_list = models.Book.objects.values("publisher__name").annotate(min_price=Min("price")) # 统计不止一个作者的图书
book_list = models.Book.objects.annotate(author_num=Count("author")).filter(author_num__gt=1) # 根据一本图书作者数量的多少对查询集 QuerySet进行排序
book_list = models.Book.objects.annotate(author_num=Count("author")).order_by("author_num") # 查询各个作者出的书的总价格
author_list = models.author.annotate(sum_price=Sum("book__price")).values("name", "sum_price"))
# ORM连表分组查询
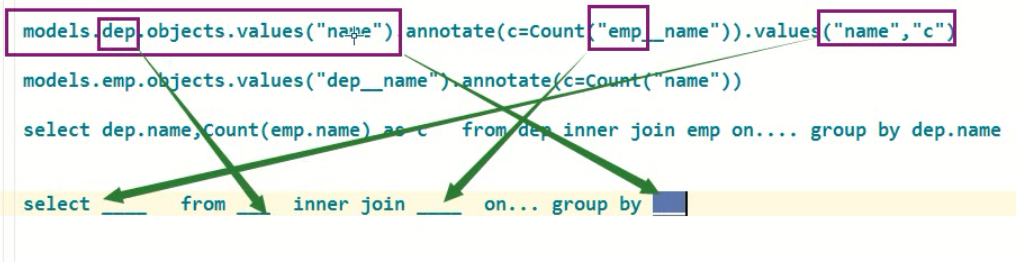
# 根据 "部门" 计算出 "平均工资" 结果为显示为 "部门名字 : 平均工资" 的表 ret = models.Person.objects.values("dept_id").annotate(a=Avg("salary")).values("dept__name", "a")
# """
# SELECT `dept`.`name`, AVG(`person`.`salary`) AS `a` FROM `person` INNER JOIN `dept` ON (`person`.`dept_id` = `dept`.`id`) GROUP BY `person`.`dept_id`, `dept`.`name` ORDER BY NULL LIMIT 21; args=()
# """
查询每个部门的员工的员工数
关键点:
- queryset 对象.anntate()
- anntate 按前面的 select 字段进行 group by 分组统计 ,
- anntate() 的返回值依旧是 queryset 对象 , 只是增加了分组统计后的键值对
- 即 " 分组规则 " .anntate(" 连表操作,数据处理 ") . " 筛选字段 "
- 分组规则 :
- 基于queryset 方法 对分组关键字段进行筛选
- 即 "根据"什么
- 转换成 sql 语句 为 group by 后面的部分
- 基于queryset 方法 对分组关键字段进行筛选
- 连表操作,数据处理:
- 视情况进行是否连表,以及新增一个计算出的字段
- 即 " 计算 " 什么
- 视情况进行是否连表,以及新增一个计算出的字段
- 筛选字段:
- 基于queryset 方法 对新增字段进行筛选 并呈现最终结果
- 即 "想要" 什么
- 转换成 sql 语句 为 select 后面的部分
- 基于queryset 方法 对新增字段进行筛选 并呈现最终结果
- 分组规则 :
分组查询的超级详细的解析示例:
查询每个部门的员工总工总人数


F查询
概念
对于基础的两个值得比较可以通过上面的方法实现
但是对于两个字段的比较则需要用到 F 查询
示例
# 查询评论数大于收藏数的书籍
from django.db.models import F
models.Book.objects.filter(commnet_num__gt=F('keep_num')) # Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
models.Book.objects.filter(commnet_num__lt=F('keep_num')*2) # 对整个字段的所有值的操作也可以通过 F 函数实现
# 比如将每一本书的价格提高30元
models.Book.objects.all().update(price=F("price")+30)
关于修改 char 字段的操作
# 把所有书名后面加上(第一版)
>>> from django.db.models.functions import Concat
>>> from django.db.models import Value
>>> models.Book.objects.all().update(title=Concat(F("title"), Value("("), Value("第一版"), Value(")")))
Q查询
概念
当使用filter 的时候 ,内部多个筛选条件是 and 的关系
若需求为 or 的关系需要用到 Q 查询
示例
# 查询作者名是羊驼或山羊的
models.Book.objects.filter(Q(authors__name="羊驼")|Q(authors__name="山羊"))
复杂示例
# 可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询。
# 查询作者名字是羊驼之歌并且不是2018年出版的书的书名。
models.Book.objects.filter(Q(author__name="羊驼之歌") & ~Q(publish_date__year=2018)).values_list("title")
注意
当 and 和 or 同时一起用的时候 , Q 查询需要放在前面
示例
# 查询出版年份是2017或2018,书名中带羊驼的所有书。
models.Book.objects.filter(Q(publish_date__year=2018) | Q(publish_date__year=2017), title__icontains="羊驼")
Q查询的另一种方法:
此方法比通常使用稍微复杂一些。本质上和 .filter(Q(title="yang")|Q(price=123)) 实现效果相同,
但是 这样子拆分出来可以实现 不在使用字段对象,而是用字符串来筛选
场景适用:
搜索框获取当前get 请求中的参数时,参数为字符串形式,用常规的Q查询必须依靠字段对象从而无法实现
q = Q() # 将Q实例化对象单独拿出来
q.connnection = "or" # 默认多条件的关系是 "and" 通过connection 可以改成其他
q.children.append(("title", "yang")) # 添加查询字段
q.children.append(("price", 123))
锁
限制住当前查询结束后才可以其他的操作.保证数据的可靠性
select_for_update(nowait=False, skip_locked=False)
示例
entries = Entry.objects.select_for_update().filter(author=request.user)
执行原生的sql 语句
# 查询person表,判断每个人的工资是否大于2000
# 利用子查询,可以写入原生的sql语句
ret = models.Person.objects.all().extra(
select={"gt": "salary > 2000"}
) # """
# SELECT (salary > 2000) AS `gt`, `person`.`id`, `person`.`name`, `person`.`salary`, `person`.`dept_id` FROM `person` LIMIT 21; args=()
# """ for i in ret:
print(i.name, i.gt)
# 执行完全的原生的SQL语句,类似pymql
from django.db import connection
cursor = connection.cursor() # 获取光标,等待执行SQL语句
cursor.execute("""SELECT * from person where id = %s""", [1])
row = cursor.fetchone()
print(row)
Django_ORM操作 - 查询的更多相关文章
- 一对一关联查询时使用relation连贯操作查询后,调用getLastSql()方法输出的sql语句
如题: 一对一关联查询时使用relation连贯操作查询后,调用getLastSql()方法输出的sql语句不是一条关联查询语句. 例如: $list = $db->relation(true) ...
- MySQL查询in操作 查询结果按in集合顺序显示_Mysql_脚本之家
body { font-family: "Microsoft YaHei UI","Microsoft YaHei",SimSun,"Segoe UI ...
- Atitit. 注册表操作查询 修改 api与工具总结 java c# php js python 病毒木马的原理
Atitit. 注册表操作查询 修改 api与工具总结 java c# php js python 病毒木马的原理 1. reg 工具 这个cli工具接口有,优先使用,jreg的要调用dll了,麻烦的 ...
- MongoDB学习笔记~自己封装的Curd操作(查询集合对象属性,更新集合对象)
回到目录 我不得不说,mongodb官方驱动在与.net结合上做的不是很好,不是很理想,所以,我决定对它进行了二次封装,这是显得很必然了,每个人都希望使用简单的对象,而对使用复杂,麻烦,容易出错的对象 ...
- [转] MongoDB shell 操作 (查询)
最近有用到mongoDB,每次都去查看官方文档很是费劲,自己准备写点东西.但在博客园上看到另外的一篇博文不错,就转载过来,加上点儿自己的修饰 左边是mongodb查询语句,右边是sql语句.对照着用, ...
- MySQL查询in操作 查询结果按in集合顺序显示(转)
MySQL 查询in操作,查询结果按in集合顺序显示的实现代码,需要的朋友可以参考下. MySQL 查询in操作,查询结果按in集合顺序显示 复制代码代码如下: select * from test ...
- UNION、EXCEPT和INTERSECT操作查询结果
对查询结果进行合并.剔除.取重操作可以通过UNION.EXCEPT和INTERSECT实现 任意一种操作都要满足以下两个条件: 1.字段的数量和顺序一致 2.对应字段的数据类型相兼容 一.UNION ...
- ORM 多表操作查询及增删改查
------------------------------------------只有对前途乐观的人,才能不怕黑暗,才能有力量去创造光明.乐观不是目的,而是人生旅途中的一种态度. 多表操作 创建模型 ...
- django_orm操作
查询操作和性能优化 1.基本操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 增 models.Tb1.object ...
随机推荐
- Celery工具
什么是Celery Celery的功能 Celery是基于python实现的第三方组件,可以实现定时任务.周期任务等. Celery的组成 Celery的角色 - 任务,创建或发布任务. - 使用re ...
- 项目开发过程中什么是开发环境、测试环境、生产环境、UAT环境、仿真环境?
项目开发过程中什么是开发环境.测试环境.生产环境.UAT环境.仿真环境? 最近在公司项目开发过程中总用到测试环境,生产环境和UAT环境等,然而我对环境什么的并不是很理解它的意思,一直处于开发阶段,出于 ...
- C盘突然报警,空间不足,显示成红色了
1.清理系统垃圾文件 将如下命令保存到一个bat文件中,执行,删除垃圾文件 @echo off net share c$ /del net share d$ /del net share e$ /de ...
- 简单的纯js三级联动
参考这个 日尼禾尔 二级联动 写了三级联动 <!DOCTYPE html> <html> <head> <meta charset="UTF-8 ...
- python使用rabbitMQ介绍四(路由模式)
一.模式介绍 路由模式,与发布-订阅模式一样,消息发送到exchange中,消费者把队列绑定到exchange上. 这种模式在exchange上添加添加了一个路由键(routing-key),生产者发 ...
- Docker-Dockerfile及基本语法
Dockerfile的作用是通过它可以生成自定镜像,先介绍几个基本的docker命令. [docker镜像相关的命令]docker search 镜像名: 搜索镜像docker pull 镜像名: 镜 ...
- nginx平滑升级(1.14--1.15)
查看旧版nginx编译参数 [root@localhost yum.repos.d]# nginx -V nginx version: nginx/1.14.2 built by gcc 4.8.5 ...
- ASP.NET Zero--基础设施
基础设施 启动类 ASP.NET Core从应用程序中的Startup类初始化.我们在这个类中配置所有库(包括ABP).我们建议您先检查此课程.它也被集成到 OWIN.所以,你可以在这里添加OWIN中 ...
- JavaScript jQuery 中定义数组操作及数组操作
1.认识数组 数组就是某类数据的集合,数据类型可以是整型.字符串.甚至是对象 Javascript不支持多维数组,但是因为数组里面可以包含对象(数组也是一个对象),所以数组可以通过相互嵌套实现类似多维 ...
- scp远程拷贝文件及文件夹
scp : 远程copy 命令 -r : 递归copy 从Linux Copy 到 Linux 从Linux Copy 到 Windows (当前目录使用. 就可以了) scp -r root@10. ...