挑子学习笔记:DBSCAN算法的python实现
转载请标明出处:https://www.cnblogs.com/tiaozistudy/p/dbscan_algorithm.html
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)聚类算法,是一种基于高密度连通区域的、基于密度的聚类算法,能够将具有足够高密度的区域划分为簇(Cluster),并在具有噪声的数据中发现任意形状的簇。DBSCAN算法通过距离定义出一个密度函数,计算出每个样本附近的密度,从而根据每个样本附近的密度值来找出那些样本相对比较集中的区域,这些区域就是我们要找的簇。
1. DBSCAN算法的基本原理
其它聚类方法大都是基于对象之间的距离进行聚类,聚类结果是球状的簇。DBSCAN 算法利用簇的高密度连通性,寻找被低密度区域分离的高密度区域,可以发现任意形状的簇,其基本思想是:对于一个簇中的每个对象,在其给定半径的领域中包含的对象不能少于某一给定的最小数目。
DBSCAN算法中有两个重要参数:$\varepsilon$表示定义密度时的邻域半径,$M$ 表示定义核心点时的阈值。
考虑数据集合$X= \{x^{(1)}, x^{(2)},...,x^{(n)} \}$,引入以下概念与记号。
1. $\varepsilon$邻域
设$x \in X$,称
\begin{equation*}
N_{\varepsilon}(x) = \{ y \in X: d(y,x) \le \varepsilon \}
\end{equation*}
为$X$的$\varepsilon$邻域。显然,$x \in N_{\varepsilon}(x)$。
为了简单起见,节点$x^{(i)}$与其下标$i$一一对应,引入记号
\begin{equation*}
N_{\varepsilon}(i) = \{ j: d(y^{(j)},x^{(i)}) \le \varepsilon; \; y^{(j)},x^{(i)} \in X \}
\end{equation*}
2. 密度
设$x \in X$,称$\rho(x) = |N_{\varepsilon}(x)|$为$x$的密度。密度是一个整数,且依赖于半径$\varepsilon$。
3. 核心点
设$x \in X$,若$\rho(x) \ge M$,则称$x$为$X$的核心点。记由$X$中所有核心点构成的集合为$X_c$,并记$X_{nc}=X-X_c$表示$X$中所有非核心点构成的集合。
4. 边界点
若$x \in X_{nc}$,且$\exists y \in X$,满足$y \in N_{\varepsilon}(x) \bigcap X_c$,即$X$的非核心点$x$的$\varepsilon$邻域中存在核心点,则称$x$ 为$X$的边界点。记由$X$中所有边界点构成的集合为$X_{bd}$。
此外,边界点也可以这么定义,若$x \in X_{nc}$,且$x$落在某个核心点的$\varepsilon$邻域内,则称$x$为$X$的边界点。一个边界点可能同时落入一个或多个核心点的$\varepsilon$ 邻域内。
5. 噪声点
记$X_{noi} = X - (X_c \bigcup X_{bd})$,若$x \in X_{noi}$,则称$x$为噪音点。
至此,我们严格给出了核心点、边界点和噪音点的数学定义,且满足$X = X_c \bigcup X_{bd} \bigcup X_{noi}$.

图1:核心点、边界点和噪声点
直观地说,核心点对应稠密区域内部的点,边界点对应稠密区域边缘的点,而噪音点对应稀疏区域中的点。
数据集通过聚类形成的子集是簇。核心点位于簇的内部,它确定无误地属于某个特定的簇;噪音点是数据集中的干扰数据,它不属于任何一个簇;边界点是一类特殊的点,它位于一个或几个簇的边缘地带,可能属于一个簇,也可能属于另外一个簇,其归属并不明确。
6. 直接密度可达
设$x,y \in X$. 若满足$x \in X_c$,则称$y$是$x$从直接密度可达的。
7. 密度可达
设$p^{(1)}, p^{(2)},..., p^{(m)} \in X$,其中$m \ge 2$。若它们满足:$p^ {(i+1)}$ 是从$p^{(i)}$直接密度可达的,其中$i = 1,2,...,m-1$,则称$p^ {(m)}$ 是从$p^{(1)}$ 中密度可达的。
7.1. 当$m = 2$时,密度可达即为直接密度可达。实际上,密度可达是直接密度可达的传递闭包。
7.2. 密度可达关系不具有对称性。若$p^{(m)}$是从$p^{(1)}$密度可达的,那么$p^ {(1)}$ 不一定是从$p^{(m)}$密度可达的。根据上述定义可知,$p^{(1)}, p^{(2)}, ..., p^{(m-1)}$必须为核心点,而$p^{(m)}$可以是核心点,也可以是边界点。当$p^ {(m)}$是边界点时,$p^{(1)}$一定不是从$p^{(m)}$密度可达的。
8. 密度相连
设$x,y,z \in X$,若$y$和$z$均是从$x$密度可达的,则称$y$和$z$是密度相连的。显然,密度相连具有对称性。
9. 簇(cluster)
非空集合$C \subset X$,如果$C$满足:对于$x,y \in X$
- 若$x \in C$,且$y$是从$x$密度可达的,则$y \in C$,
- 若$x \in C$,$y \in C$,则$x,y$是密度相连的。
则称$C$是$X$的一个簇。
DBSCAN 算法基于以下一个基本事实:对于任一核心点$x$,数据集$X$中所有从$x$ 密度可达的数据点可以构成一个完整的簇$C$,且$x \in C$。其核心思想描述如下:从某个选定的核心点出发,不断向密度可达的区域扩张,从而得到一个包含核心点和边界点的最大化区域,区域中任意两点密度相连。
2. DBSCAN算法的实现
《数据挖掘概念与技术》给出的算法伪代码如下:

考虑数据集合$X= \{x^{(1)}, x^{(2)},..., x^{(n)} \}$。DBSCAN算法的目标是将数据集合$X$分成$K$个簇及噪声点集合,其中$K$也是由算法得到,为此,引入簇的标记数组
\begin{equation*}
m_i =
\begin{cases}
j, & \text{若}x^{(i)}\text{属于第}j\text{个簇}; \\
-1, & \text{若}x^{(i)}\text{为噪声点}
\end{cases}
\end{equation*}
DBSCAN算法的目标就是生成标记数组$m_i, \; i=1,...,n$.
为了保证可以更有效地实现算法1中第3句随机选择一个unvisited对象$p$,设计了一个数据结构visitlist,其中包含两个列表visitedlist和unvisitedlist,分别用于存储已访问的点和未访问的点,每次从unvisitedlist 中取点可以保证每次取到的点都是未访问过的点,实现代码如下:
代码1:visitlist数据结构
# visitlist类用于记录访问列表
# unvisitedlist记录未访问过的点
# visitedlist记录已访问过的点
# unvisitednum记录访问过的点数量
class visitlist:
def _init_(self, count=0):
self.unvisitedlist=[i for i in range(count)]
self.visitedlist=list()
self.unvisitednum=count def visit(self, pointId):
self.visitedlist.append(pointId)
self.unvisitedlist.remove(pointId)
self.unvisitednum -= 1
DBSCAN算法实现代码如下:
代码2:DBSCAN算法实现
import numpy as np
import matplotlib.pyplot as plt
import math
import random def dist(a, b):
# 计算a,b两个元组的欧几里得距离
return math.sqrt(np.power(a-b, 2).sum()) def my_dbscanl(dataSet, eps, minPts):
# numpy.ndarray的 shape属性表示矩阵的行数与列数
nPoints = dataSet.shape[0]
# (1)标记所有对象为unvisited
# 在这里用一个类vPoints进行买现
vPoints = visitlist(count=nPoints)
# 初始化簇标记列表C,簇标记为 k
k = -1
C = [-1 for i in range(nPoints)]
while(vPoints.unvisitednum > 0):
# (3)随机上选择一个unvisited对象p
P = random.choice(vPoints.unvisitedlist)
# (4)标记p为visited
vPoints.visit(p)
# (5)if p的$\varepsilon$-邻域至少有MinPts个对象
# N是p的$\varepsilon$-邻域点列表
N = [i for i in range(nPoints) if dist(dataSet[i], dataSet[p])<= eps]
if len(N) >= minPts:
# (6)创建个新簇C,并把p添加到C
# 这里的C是一个标记列表,直接对第p个结点进行赋植
k += 1
C[p]=k
# (7)令N为p的ε-邻域中的对象的集合
# N是p的$\varepsilon$-邻域点集合
# (8) for N中的每个点p'
for p1 in N:
# (9) if p'是unvisited
if p1 in vPoints.unvisitedlist:
# (10)标记p’为visited
vPoints.visit(p1)
# (11) if p'的$\varepsilon$-邻域至少有MinPts个点,把这些点添加到N
# 找出p'的$\varepsilon$-邻域点,并将这些点去重添加到N
M=[i for i in range(nPoints) if dist(dataSet[i], \
dataSet[p1]) <= eps]
if len(M) >= minPts:
for i in M:
if i not in N:
N.append(i)
# (12) if p'还不是任何簇的成员,把P'添加到C
# C是标记列表,直接把p'分到对应的簇里即可
if C[p1] == -1:
C[p1]= k
# (15)else标记p为噪声
else:
C[p]=-1 # (16)until没有标t己为unvisitedl内对象
return C
利用sklearn生成数据集,共2500条数据,并利用matplotlib画出散点图,代码如下:
代码3:生成数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets X1, Y1 = datasets.make_circles(n_samples=2000, factor=0.6, noise=0.05,
random_state=1)
X2, Y2 = datasets.make_blobs(n_samples=500, n_features=2, centers=[[1.5,1.5]],
cluster_std=[[0.1]], random_state=5) X = np.concatenate((X1, X2))
plt.figure(figsize=(12, 9), dpi=80)
plt.scatter(X[:,0], X[:,1], marker='.')
plt.show()
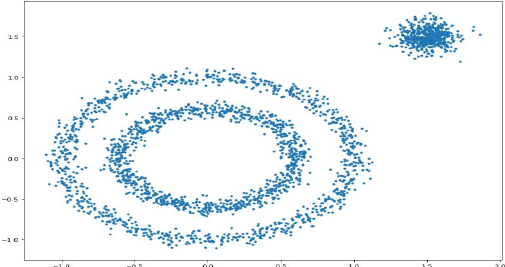
图2:数据集散点图
设置参数Eps=0.1, MinPts=10,聚类结果如下图:
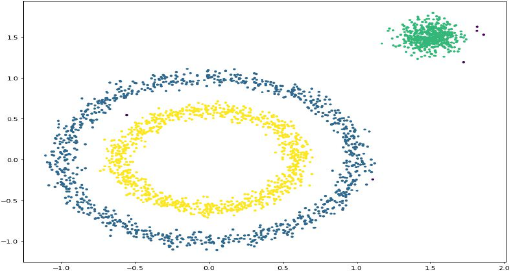
图3:聚类结果
3. 利用KD树进行优化
KD树(K-Dimensional Tree),是一种分割k维数据空间的数据结构,是二叉搜索树在多维条件下的推广。主要应用于多维空间关键数据的搜索。KD树的介绍见:https://www.jianshu.com/p/ffe52db3e12b,不赘述。
利用scipy实现KD树的构造和查询,对代码2的算法进行改进,代码如下:
代码4:DBSCAN算法的优化实现
import numpy as np
import matplotlib.pyplot as plt
import math
import random
from scipy.spatial import KDTree def my-dbscan2(dataSet, eps, minPts):
# numpy.ndarray的 shape属性表示矩阵的行数与列数
# 行数即表小所有点的个数
nPoints = dataSet.shape[0]
# (1) 标记所有对象为unvisited
# 在这里用一个类vPoints进行实现
vPoints = visitlist(count=nPoints)
# 初始化簇标记列表C,簇标记为 k
k = -1
C = [-1 for i in range(nPoints)]
# 构建KD-Tree,并生成所有距离<=eps的点集合
kd = KDTree(X)
while(vPoints.unvisitednum>0):
# (3) 随机选择一个unvisited对象p
p = random.choice(vPoints.unvisitedlist)
# (4) 标t己p为visited
vPoints.visit(p)
# (5) if p 的$\varepsilon$-邻域至少有MinPts个对象
# N是p的$\varepsilon$-邻域点列表
N = kd.query_ball_point(dataSet[p], eps)
if len(N) >= minPts:
# (6) 创建个一个新簇C,并把p添加到C
# 这里的C是一个标记列表,直接对第p个结点进行赋值
k += 1
C[p] = k
# (7) 令N为p的$\varepsilon$-邻域中的对象的集合
# N是p的$\varepsilon$-邻域点集合
# (8) for N中的每个点p'
for p1 in N:
# (9) if p'是unvisited
if p1 in vPoints.unvisitedlist:
# (10) 标记p'为visited
vPoints.visit(p1)
# (11) if p'的$\varepsilon$-邻域至少有MinPts个点,把这些点添加到N
# 找出p'的$\varepsilon$-邻域点,并将这些点去重新添加到N
M = kd.query_ball_point(dataSet[p1], eps)
if len(M) >= minPts:
for i in M:
if i not in N:
N.append(i)
# (12) if p'还不是任何簇的成员,把p'添加到c
# C是标记列表,直接把p'分到对应的簇里即可
if C[p1] == -1
C[p1] = k
# (15) else标记p为噪声
else:
C[p1] = -1 # (16) until没有标记为unvisited的对象
return C
以代码3中生成的2500条数据作为测试,比较优化前后的算法性能
import time
start = time.time()
C1 = my_dbscanl(X, 0.1, 10)
end = time.time()
print "`运行时间`:", end - start
plt.scatter(X[:, 0], X[:, 1], c=C1, marker='.')
plt.show()
>>> `运行时间:`29.1249849796
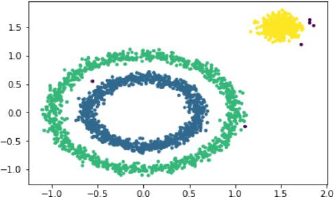
图4:优化前算法结果
import time
start = time.time()
C2 = my_dbscan2(X, 0.1, 10)
end = time.time()
print "运行时间:", end - start
plt.scatter(X[:, 0], X[:, 1], c=C2, marker='.')
plt.show()
>>> 运行时间:4.72340583801
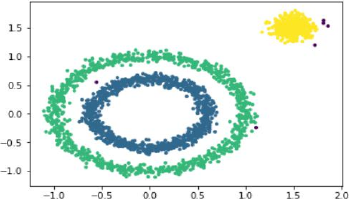
图5:优化后算法结果
可以看到优化后的算法运行时间从29.12s降到了4.72s,优化的效果非常明显。
4. 后记
上文仅仅是对DBSCAN算法的思想与实现进行了简略摘要,是学习算法的一个过程。算法的学习还比较粗劣和浅层,在实践应用中上述代码并不实用。如果需要使用DBSCAN的算法求解聚类问题,建议使用sklearn自带的DBSCAN函数。以代码3中生成数据为例:
# DBSCAN eps = 0.1, MinPts = 10
import time
from sklearn.cluster import DBSCAN
start = time.time()
C = DBSCAN(eps=0.1, min_pts=10).
end = time.time()
print "运行时间:", end - start
plt.scatter(X[:, 0], X[:, 1], c=C, marker='.')
plt.show()
>>> 运行时间:0.0240921974182
挑子学习笔记:DBSCAN算法的python实现的更多相关文章
- [ML学习笔记] XGBoost算法
[ML学习笔记] XGBoost算法 回归树 决策树可用于分类和回归,分类的结果是离散值(类别),回归的结果是连续值(数值),但本质都是特征(feature)到结果/标签(label)之间的映射. 这 ...
- python3.4学习笔记(二十六) Python 输出json到文件,让json.dumps输出中文 实例代码
python3.4学习笔记(二十六) Python 输出json到文件,让json.dumps输出中文 实例代码 python的json.dumps方法默认会输出成这种格式"\u535a\u ...
- python3.4学习笔记(二十五) Python 调用mysql redis实例代码
python3.4学习笔记(二十五) Python 调用mysql redis实例代码 #coding: utf-8 __author__ = 'zdz8207' #python2.7 import ...
- python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法
python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法window安装redis,下载Redis的压缩包https://git ...
- python3.4学习笔记(二十二) python 在字符串里面插入指定分割符,将list中的字符转为数字
python3.4学习笔记(二十二) python 在字符串里面插入指定分割符,将list中的字符转为数字在字符串里面插入指定分割符的方法,先把字符串变成list然后用join方法变成字符串str=' ...
- openresty 学习笔记番外篇:python的一些扩展库
openresty 学习笔记番外篇:python的一些扩展库 要写一个可以使用的python程序还需要比如日志输出,读取配置文件,作为守护进程运行等 读取配置文件 使用自带的ConfigParser模 ...
- openresty 学习笔记番外篇:python访问RabbitMQ消息队列
openresty 学习笔记番外篇:python访问RabbitMQ消息队列 python使用pika扩展库操作RabbitMQ的流程梳理. 客户端连接到消息队列服务器,打开一个channel. 客户 ...
- 学习笔记 - Manacher算法
Manacher算法 - 学习笔记 是从最近Codeforces的一场比赛了解到这个算法的~ 非常新奇,毕竟是第一次听说 \(O(n)\) 的回文串算法 我在 vjudge 上开了一个[练习],有兴趣 ...
- python学习笔记:安装boost python库以及使用boost.python库封装
学习是一个累积的过程.在这个过程中,我们不仅要学习新的知识,还需要将以前学到的知识进行回顾总结. 前面讲述了Python使用ctypes直接调用动态库和使用Python的C语言API封装C函数, C+ ...
随机推荐
- win7 64位专业版下的x64编译问题
在Django的开发过程中,碰到一个问题,就是所有本地库的位数必须是相同的,于是某些库需要重新编译一下,工作环境,不能用盗版程序,VC++ 2008\2010 Express版本身都不支持X64的编译 ...
- 建站记录:设置apache .htaccess文件给网站添加404错误处理页面
有些空间服务商会在后台设置中,提供这个选项,可以直观地设置404错误指向的页面,这一点很方便,比如我之前用的阿里云虚拟主机就可以在控制台直接设置. 新租用的香港主机后台没有找到选取文件的地方,只是可以 ...
- httpClient连接超时设置
注: 每个HttpClinet对象设置都不一样 这里已3.x和4.x为例说明 1)3.X版本 创建连接 HttpClient httpClient=new DefaultHttpClient(); 这 ...
- 用Django做一个团队介绍
所用工具 Pycharm 社区版 Django 2.x Python 3.6.4 总目录 settings中的设置 总的路由设置 templates中的index.html文件 <!DOCTYP ...
- Collection、List、Set集合概括
1.Collection是一个接口,定义了集合相关的操作方法,其有两个子接口List和Set. 2.List和Set的区别 List是有序的可重复集合,Set是无序的不可重复集合. 3.集合持有 ...
- PAT1133:Splitting A Linked List
1133. Splitting A Linked List (25) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Y ...
- String的valueOf()用于将其它类型转换为字符串
String的valueOf()重载方法可将double类型,int类型,boolean类型以及char数组类型等变量转换为String类变量. 注:String的valueOf()可将char数组转 ...
- 定时器Timer的使用
概述 Timer类的主要作用是设置计划任务,但封装任务的类却是TimerTask类.执行计划任务的代码要放入TimerTask的子类中,因为TimerTask是一个抽象类. 方法schedule(ta ...
- Spring通过构造方法注入的四种方式
通过构造方法注入,就相当于给构造方法的参数传值 set注入的缺点是无法清晰表达哪些属性是必须的,哪些是可选 的,构造注入的优势是通过构造强制依赖关系,不可能实例化不 完全的或无法使用的bean. Me ...
- SSM-Spring-03:Spring中AOP的初窥和入门小案例
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- AOP:面向切面编程 AOP的主要作用:是为了程序员更好的关注"业务",专心"做 ...