【Python3爬虫】百度一下,坑死你?
一、写在前面
这个标题是借用的路人甲大佬的一篇文章的标题(百度一下,坑死你),而且这次的爬虫也是看了这篇文章后才写出来的,感兴趣的可以先看下这篇文章。
前段时间有篇文章《搜索引擎百度已死》引起了很多讨论,而百度对此的回复是:百家号的内容在百度搜索结果中不超过10%。但是这个10%是第一页的10%还是所有数据的10%,我们不得而知,但是由于很多人都只会看第一页的内容,而如果这第一页里有十分之一的内容都来自于百家号,那搜索体验恐怕不怎么好吧?然后我这次写的爬虫就是把百度上面的热搜事件都搜索一下,然后把搜索结果的第一页上的标题链接提取出来,最后对这些链接进行一些简单的分析,看看百家号的内容占比能有多少。
二、具体步骤
1.页面分析
首先打开网页查看百度的热点事件,页面如下:
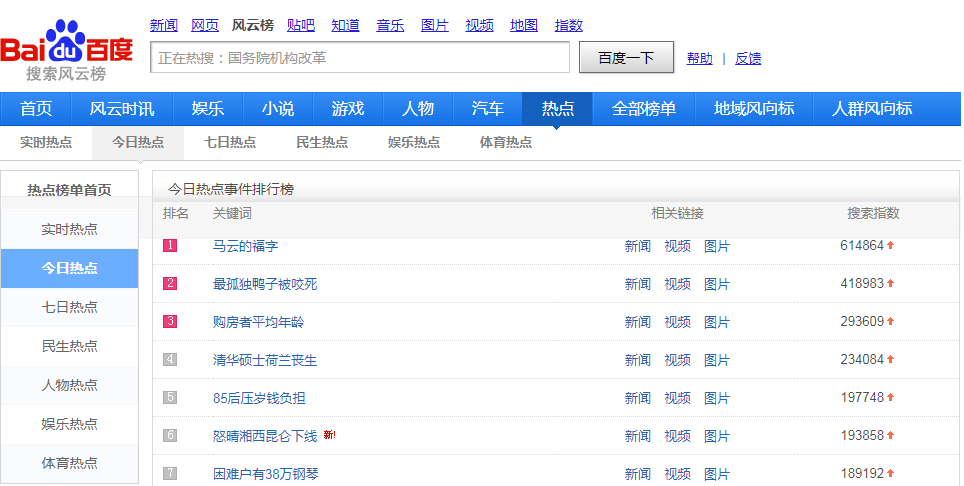
这次我主要对今日热点、娱乐热点、体育热点进行了爬取,每个热点下面有50条热点事件,然后对每个事件进行搜索,比如第一条--马云的福字:
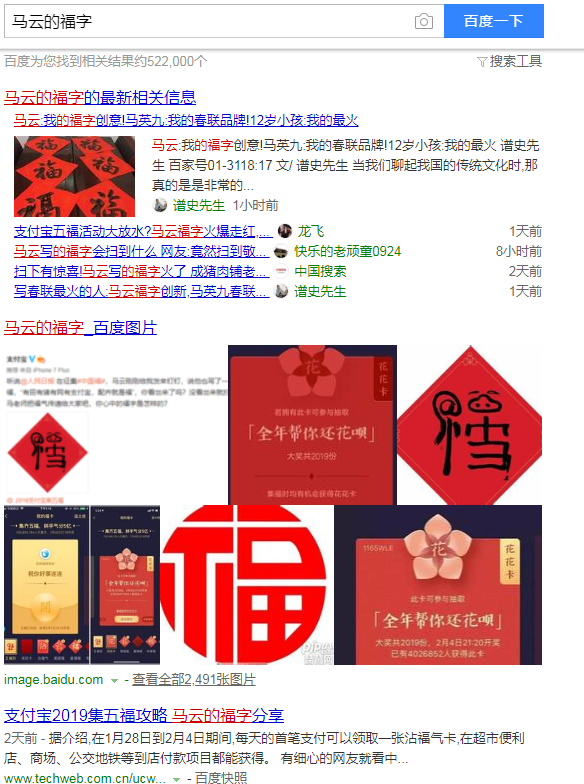
可以看到搜索结果的第一页上有很多标题,然后对这些标题的链接进行爬取,再保存到一个txt文件里,最后对这些数据进行分析。
2.主要代码
(1)获取真实链接
这些搜索结果页面上的链接都是经过加密的,如下图:
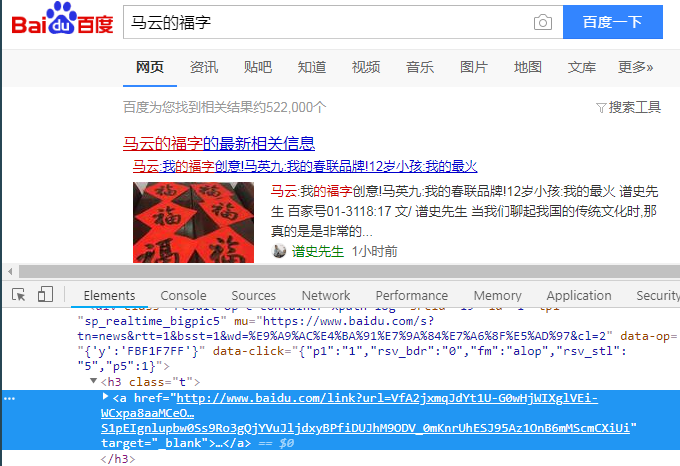
所以我们爬取得到的链接都是http://www.baidu.com/link?url=VfA2jxmqJdYt1U-G0wHjWIXglVEi-WCxpa8aaMCeOzkqK-c5CgYngPiJT6_-kmWE3ePTHCpgYlX5oq9SQDJgEukKCY19o26JlS1pEIgnlupbw0Ss9Ro3gQjYVuJljdxyBPfiDUJhM9ODV_0mKnrUhESJ95Az1OnB6mMScmCXiUi这种,但是我们点进去之后就能得到真实的链接https://www.baidu.com/s?tn=news&rtt=1&bsst=1&wd=%E9%A9%AC%E4%BA%91%E7%9A%84%E7%A6%8F%E5%AD%97&cl=2&origin=ps,那我们要怎么得到真实的链接呢?相关代码如下:
def get_real_url(self, fake_url):
# 获取真实的链接
try:
res = requests.get(fake_url, headers=self.headers)
real_url = res.url
except Exception as e:
print(e)
(2)数据处理
这里我总共爬取了1051条链接,如下图:
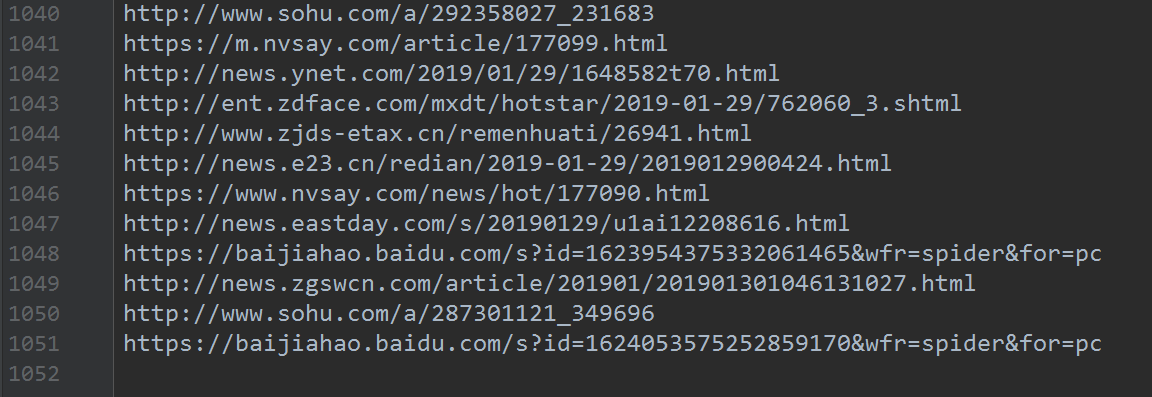
但是这样的数据是明显没有办法进行分析的,所以需要进行一下处理,比如将https://baijiahao.baidu.com/s?id=1624053575252859170&wfr=spider&for=pc变成baijiahao.baidu,相关代码如下:
href = "https://baijiahao.baidu.com/s?id=1624053575252859170&wfr=spider&for=pc"
match = re.match("(http[s]?://.+?[com,cn,net]/)", href)
href = match.group()
href = href.replace('cn', 'com').replace('net', 'com')
href = href[href.index(':') + 3:].rstrip('.com/')
print(href)
# baijiahao.baidu
(3)数据分析
这里主要使用了matplotlib绘图帮助我们分析数据。首先需要统计出各个网站出现的次数,然后进行一个排序,得到排名前十的网站,结果如下(前面是网站,后面是出现次数):
https://baijiahao.baidu.com/ 188
https://www.baidu.com/ 114
http://www.sohu.com/ 60
https://news.china.com/ 29
http://www.guangyuanol.cn/ 27
http://image.baidu.com/ 24
http://3g.163.com/ 20
https://sports.qq.com/ 19
https://www.iqiyi.com/ 17
https://baike.baidu.com/ 17
可以看到百家号出现的次数是最多的。然后进行绘图分析,这里主要是绘图的代码,因为使用的是百分数,所以在绘图的时候会稍微麻烦一点:
def plot(self, index_list, value_list):
b = self.ax.barh(range(len(index_list)), value_list, color='blue', height=0.8)
# 添加数据标签
for rect in b:
w = rect.get_width()
self.ax.text(w, rect.get_y() + rect.get_height() / 2, '{}%'.format(w),
ha='left', va='center')
# 设置Y轴刻度线标签
self.ax.set_yticks(range(len(index_list)))
self.ax.set_yticklabels(index_list)
# 设置X轴刻度线
lst = ["{}%".format(i) for i in range(0, 20, 2)]
self.ax.set_xticklabels(lst) plt.subplots_adjust(left=0.25)
plt.xlabel("占比")
plt.ylabel("网站")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.savefig("bjh.jpg")
print("已保存为bjh.jpg!")
三、运行结果
由于每个事件的搜索结果都是不同的,所以在解析网页的时候可能会出错,然后就是请求频率太高了会被ban掉,而且有时候UA会被识别出来然后就被ban掉了,运行情况如下图:

最后看一下绘制出来的图片:

可以看到百家号的内容占比达到了17%,而排在第二的也是百度自家的产品,内容占比也达到了10%。当然了,由于搜索的都是百度上的热搜事件,所以得到的结果百度自家的内容会多一点,但是光百家号的内容就占了17%,是不是也太多了点呢?
完整代码已上传到GitHub!
【Python3爬虫】百度一下,坑死你?的更多相关文章
- python3爬虫中文乱码之请求头‘Accept-Encoding’:br 的问题
当用python3做爬虫的时候,一些网站为了防爬虫会设置一些检查机制,这时我们就需要添加请求头,伪装成浏览器正常访问. header的内容在浏览器的开发者工具中便可看到,将这些信息添加到我们的爬虫代码 ...
- python3爬虫(4)各种网站视频下载方法
python3爬虫(4)各种网站视频下载方法原创H-KING 最后发布于2019-01-09 11:06:23 阅读数 13608 收藏展开理论上来讲只要是网上(浏览器)能看到图片,音频,视频,都能够 ...
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- Python3 爬虫之 Scrapy 核心功能实现(二)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的搭建过程请参照本人的另一篇博客:Python3 爬虫之 Scrap ...
- Python3 爬虫之 Scrapy 框架安装配置(一)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的爬虫实现过程请参照本人的另一篇博客:Python3 爬虫之 Scr ...
- python3爬虫--反爬虫应对机制
python3爬虫--反爬虫应对机制 内容来源于: Python3网络爬虫开发实战: 网络爬虫教程(python2): 前言: 反爬虫更多是一种攻防战,针对网站的反爬虫处理来采取对应的应对机制,一般需 ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- Python3爬虫:(一)爬取拉勾网公司列表
人生苦短,我用Python 爬取原因:了解一下Python工程师在北上广等大中城市的薪资水平与入职前要求. Python3基础知识 requests,pyquery,openpyxl库的使用 爬取前的 ...
- Python爬虫-百度模拟登录(二)
上一篇-Python爬虫-百度模拟登录(一) 接上一篇的继续 参数 codestring codestring jxG9506c1811b44e2fd0220153643013f7e6b1898075 ...
随机推荐
- []T 还是 []*T, 这是一个问题
全面分析Go语言中的类型和类型指针的抉择 目录 [−] 副本的创建 T的副本创建 *T的副本创建 如何选择 T 和 *T 什么时候发生副本创建 最常见的case map.slice和数组 for-ra ...
- LOJ_2305_「NOI2017」游戏 _2-sat
LOJ_2305_「NOI2017」游戏 _2-sat 题意: 给你一个长度为n的字符串S,其中第i个字符为a表示第i个地图只能用B,C两种赛车,为b表示第i个地图只能用A,C两种赛车,为c表示第i个 ...
- css:id选择器的权重>class选择器的权重=属性选择器的权重>元素选择器
最近的项目要自己写前端了,重新学习下前端的一下基本知识. 一般在css样式表中,上面的会被下面的覆盖,如下图,文字会显示蓝色: 所以按照正常的来说,下面的css样式,测试的文字应该还是蓝色 但结果,测 ...
- 实验吧——隐写术之复杂的QR_code
好久没有更新隐写术方面的题目了,对不起各位小可爱,今天我会多多更新几篇文章,来慰藉你们! 永远爱你们的 ---------新宝宝 1:复杂的QR_code 解题思路:保存图片之后使用在线解码工具,并没 ...
- java Dated Dateformat Calendar
Date类概述 类Date表示特定的瞬间,精确到毫秒.1000毫秒=1秒 时间的原点:公元1970年 一月一日,午夜0:00:00 对应的毫秒值就是0 注意:时间和日期的计算,必须依赖毫秒值 long ...
- Drrols规则引擎
1.什么是规则引擎? 规则引擎是一种嵌套在应用程序中的组件,它实现了将业务规则从应用程序代码中分离出来.规则引擎使用特定的语法编写业务规则,规则引擎可以接受数据输入.解释业务规则.并根据业务规则做出相 ...
- 重磅!!!微软发布ASP.NET Core 2.2,先睹为快。
我很高兴地宣布ASP.NET Core 2.2现在作为.NET Core 2.2的一部分提供! 如何获取? 您可以从.NET Core 2.2下载页面下载适用于您的开发机器和构建服务器的新.NET C ...
- Linux文件属性及权限
一.Linux文件属性: 例如: drwxr-xr-x 2 hdy hdy 4096 11月 28 00:18 桌面 drwxr-xr-x 2 hdy hdy 4096 11月 28 00:18 桌面 ...
- DateTime Tips
DateTime Tips(System.Runtime Version=4.2.1.0) 抛砖引玉,如有错误或是更好的方式还望不吝赐教 1. 根据某个DateTime对象取其当天的起始时间例如:输入 ...
- 学习python的第二天
4.26自我总结 一.程序语言 1.机械语言 由于0和1组成 优点:执行效率快 缺点:操作麻烦繁琐 2.汇编语言 比机械语言好点 优点:比机械语言操作方便 缺点,执行慢 3.高级语言 主要两个,jav ...